Data Exploration#
Table df_orders#
Let’s look at the information about the dataframe.
df_orders.explore.info()
| Summary | Column Types | |||
|---|---|---|---|---|
| Rows | 99.44k | Text | 2 | |
| Features | 8 | Categorical | 1 | |
| Missing cells | 4.91k (<1%) | Int | 0 | |
| Exact Duplicates | --- | Float | 0 | |
| Fuzzy Duplicates | --- | Datetime | 5 | |
| Memory Usage (Mb) | 19 | |||
Initial Column Analysis#
We will examine each column individually.
order_id
df_orders.order_id.explore.info(plot=False)
| Summary | Text Metrics | |||
|---|---|---|---|---|
| Total Values | 99.44k (100%) | Avg Word Count | 1.0 | |
| Missing Values | --- | Max Length (chars) | 32.0 | |
| Empty Strings | --- | Avg Length (chars) | 32.0 | |
| Distinct Values | 99.44k (100%) | Median Length (chars) | 32.0 | |
| Non-Duplicates | 99.44k (100%) | Min Length (chars) | 32.0 | |
| Exact Duplicates | --- | Most Common Length | 32 (100.0%) | |
| Fuzzy Duplicates | --- | Avg Digit Ratio | 0.63 | |
| Values with Duplicates | --- | |||
| Memory Usage | 8 | |||
customer_id
df_orders.customer_id.explore.info(plot=False)
| Summary | Text Metrics | |||
|---|---|---|---|---|
| Total Values | 99.44k (100%) | Avg Word Count | 1.0 | |
| Missing Values | --- | Max Length (chars) | 32.0 | |
| Empty Strings | --- | Avg Length (chars) | 32.0 | |
| Distinct Values | 99.44k (100%) | Median Length (chars) | 32.0 | |
| Non-Duplicates | 99.44k (100%) | Min Length (chars) | 32.0 | |
| Exact Duplicates | --- | Most Common Length | 32 (100.0%) | |
| Fuzzy Duplicates | --- | Avg Digit Ratio | 0.62 | |
| Values with Duplicates | --- | |||
| Memory Usage | 8 | |||
order_status
df_orders.order_status.explore.info()
| Summary | Text Metrics | Value Counts | |||||
|---|---|---|---|---|---|---|---|
| Total Values | 99.44k (100%) | Avg Word Count | 1.0 | Delivered | 96.48k (97%) | ||
| Missing Values | --- | Max Length (chars) | 11.0 | Shipped | 1.11k (1%) | ||
| Empty Strings | --- | Avg Length (chars) | 9.0 | Canceled | 625 (<1%) | ||
| Distinct Values | 8 (<1%) | Median Length (chars) | 9.0 | Unavailable | 609 (<1%) | ||
| Non-Duplicates | --- | Min Length (chars) | 7.0 | Invoiced | 314 (<1%) | ||
| Exact Duplicates | 99.43k (99%) | Most Common Length | 9 (97.0%) | Processing | 301 (<1%) | ||
| Fuzzy Duplicates | 99.43k (99%) | Avg Digit Ratio | 0.00 | Created | 5 (<1%) | ||
| Values with Duplicates | 8 (<1%) | Approved | 2 (<1%) | ||||
| Memory Usage | <1 Mb | ||||||
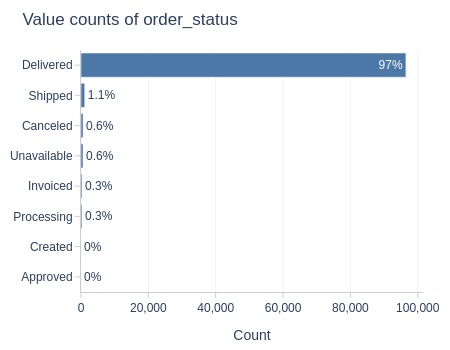
Key Observations:
97% of all orders were delivered
order_purchase_dt
df_orders.order_purchase_dt.explore.info()
| Summary | Data Quality Stats | Temporal Stats | |||||
|---|---|---|---|---|---|---|---|
| First date | 2016-09-04 | Values | 99.44k (100%) | Missing Years | --- | ||
| Last date | 2018-10-17 | Zeros | --- | Missing Months | 1 (4%) | ||
| Avg Days Frequency | 0.01 | Missings | --- | Missing Weeks | 11 (10%) | ||
| Min Days Interval | 0 | Distinct | 98.88k (99%) | Missing Days | 140 (18%) | ||
| Max Days Interval | 62 | Duplicates | 566 (<1%) | Weekend Percentage | 23.0% | ||
| Memory Usage | 1 | Dup. Values | 556 (<1%) | Most Common Weekday | Monday | ||
Key Observations:
In order_purchase_dt missing 4% of months, 10% of weeks, 18% of days
order_approved_dt
df_orders.order_approved_dt.explore.info()
| Summary | Data Quality Stats | Temporal Stats | |||||
|---|---|---|---|---|---|---|---|
| First date | 2016-09-15 | Values | 99.28k (99%) | Missing Years | --- | ||
| Last date | 2018-09-03 | Zeros | --- | Missing Months | 1 (4%) | ||
| Avg Days Frequency | 0.01 | Missings | 160 (<1%) | Missing Weeks | 11 (11%) | ||
| Min Days Interval | 0 | Distinct | 90.73k (91%) | Missing Days | 108 (15%) | ||
| Max Days Interval | 66 | Duplicates | 8.71k (9%) | Weekend Percentage | 21.4% | ||
| Memory Usage | 1 | Dup. Values | 7.04k (7%) | Most Common Weekday | Tuesday | ||
Key Observations:
In order_approved_dt 160 missing values (<1% of total rows)
In order_approved_dt missing 4% of months, 11% of weeks, 15% of days
order_delivered_carrier_dt
df_orders.order_delivered_carrier_dt.explore.info()
| Summary | Data Quality Stats | Temporal Stats | |||||
|---|---|---|---|---|---|---|---|
| First date | 2016-10-08 | Values | 97.66k (98%) | Missing Years | --- | ||
| Last date | 2018-09-11 | Zeros | --- | Missing Months | --- | ||
| Avg Days Frequency | 0.01 | Missings | 1.78k (2%) | Missing Weeks | 2 (2%) | ||
| Min Days Interval | 0 | Distinct | 81.02k (81%) | Missing Days | 157 (22%) | ||
| Max Days Interval | 20 | Duplicates | 18.42k (19%) | Weekend Percentage | 1.9% | ||
| Memory Usage | 1 | Dup. Values | 10.09k (10%) | Most Common Weekday | Tuesday | ||
Key Observations:
In order_delivered_carrier_dt 1.78k missing values (2% of total rows).
In order_delivered_carrier_dt missing 2% of weeks, 22% of days.
order_delivered_customer_dt
df_orders.order_delivered_customer_dt.explore.info()
| Summary | Data Quality Stats | Temporal Stats | |||||
|---|---|---|---|---|---|---|---|
| First date | 2016-10-11 | Values | 96.48k (97%) | Missing Years | --- | ||
| Last date | 2018-10-17 | Zeros | --- | Missing Months | --- | ||
| Avg Days Frequency | 0.01 | Missings | 2.96k (3%) | Missing Weeks | 3 (3%) | ||
| Min Days Interval | 0 | Distinct | 95.66k (96%) | Missing Days | 92 (12%) | ||
| Max Days Interval | 13 | Duplicates | 3.78k (4%) | Weekend Percentage | 6.9% | ||
| Memory Usage | 1 | Dup. Values | 804 (<1%) | Most Common Weekday | Monday | ||
Key Observations:
In order_delivered_customer_dt 2.96k missing values (3% of total rows).
In order_delivered_customer_dt missing 3% of weeks, 12% of days.
order_estimated_delivery_dt
df_orders.order_estimated_delivery_dt.explore.info(plot=False)
| Summary | Data Quality Stats | Temporal Stats | |||||
|---|---|---|---|---|---|---|---|
| First date | 2016-09-30 | Values | 99.44k (100%) | Missing Years | --- | ||
| Last date | 2018-11-12 | Zeros | --- | Missing Months | --- | ||
| Avg Days Frequency | 0.01 | Missings | --- | Missing Weeks | 5 (4%) | ||
| Min Days Interval | 0 | Distinct | 459 (<1%) | Missing Days | 315 (41%) | ||
| Max Days Interval | 16 | Duplicates | 98.98k (99%) | Weekend Percentage | 0.0% | ||
| Memory Usage | 1 | Dup. Values | 438 (<1%) | Most Common Weekday | Wednesday | ||
Key Observations:
In order_estimated_delivery_dt missing 4% of weeks, 41% of days.
Adding Temporary Dimensions#
To study anomalies across different dimensions, we will add temporary metrics.
We will prefix their names with ‘tmp_’ to indicate that these are temporary metrics to be removed later.
They are temporary because the data may change after preprocessing.
Therefore, the primary metrics will be created after preprocessing.
Let’s check the initial DataFrame size and save it to ensure no data is lost later.
print(df_orders.shape[0])
tmp_ids = df_orders.order_id
99441
tmp_df_reviews = (
df_reviews.groupby('order_id', as_index=False)
.agg(tmp_avg_reviews_score = ('review_score', 'mean'))
)
tmp_df_reviews['tmp_avg_reviews_score'] = np.floor(tmp_df_reviews['tmp_avg_reviews_score']).astype(int).astype('category')
tmp_df_payments = (
df_payments.groupby('order_id', as_index=False)
.agg(tmp_payment_types = ('payment_type', lambda x: ', '.join(x.unique())))
)
tmp_df_items = (
df_items.merge(df_products, on='product_id', how='left')
.assign(product_category_name = lambda x: x['product_category_name'].cat.add_categories(['missed in df_products']))
.fillna({'product_category_name': 'missed in df_products'})
.groupby('order_id', as_index=False)
.agg(tmp_product_categories = ('product_category_name', lambda x: ', '.join(x.unique())))
)
df_orders = (
df_orders.merge(tmp_df_reviews, on='order_id', how='left')
.merge(tmp_df_payments, on='order_id', how='left')
.merge(tmp_df_items, on='order_id', how='left')
.merge(df_customers[['customer_id', 'customer_state']], on='customer_id', how='left')
.rename(columns={'customer_state': 'tmp_customer_state'})
)
df_orders['tmp_product_categories'] = df_orders['tmp_product_categories'].fillna('Missing in Items').astype('category')
df_orders['tmp_payment_types'] = df_orders['tmp_payment_types'].fillna('Missing in Pays').astype('category')
df_orders['tmp_order_purchase_month'] = df_orders['order_purchase_dt'].dt.month_name().fillna('Missing purchase dt').astype('category')
df_orders['tmp_order_purchase_weekday'] = df_orders['order_purchase_dt'].dt.day_name().fillna('Missing purchase dt').astype('category')
conditions = [
df_orders['order_purchase_dt'].isna()
, df_orders['order_purchase_dt'].dt.hour.between(4,11)
, df_orders['order_purchase_dt'].dt.hour.between(12,16)
, df_orders['order_purchase_dt'].dt.hour.between(17,22)
, df_orders['order_purchase_dt'].dt.hour.isin([23, 0, 1, 2, 3])
]
choices = ['Missing purchase dt', 'Morning', 'Afternoon', 'Evening', 'Night']
df_orders['tmp_purchase_time_of_day'] = np.select(conditions, choices, default='Missing purchase dt')
df_orders['tmp_purchase_time_of_day'] = df_orders['tmp_purchase_time_of_day'].astype('category')
conditions = [
df_orders['order_delivered_customer_dt'].isna() | df_orders['order_estimated_delivery_dt'].isna()
, df_orders['order_delivered_customer_dt'] > df_orders['order_estimated_delivery_dt']
, df_orders['order_delivered_customer_dt'] <= df_orders['order_estimated_delivery_dt']
]
choices = ['Missing delivery dt', 'Delayed', 'Not Delayed']
df_orders['tmp_is_delayed'] = np.select(conditions, choices, default='Missing delivery dt')
df_orders['tmp_is_delayed'] = df_orders['tmp_is_delayed'].astype('category')
conditions = [
df_orders['order_status'].isna(),
df_orders['order_status'] == 'Delivered',
df_orders['order_status'] != 'Delivered',
]
choices = ['Missing Status', 'Delivered', 'Not Delivered']
df_orders['tmp_is_delivered'] = np.select(conditions, choices, default='Missing Status')
df_orders['tmp_is_delivered'] = df_orders['tmp_is_delivered'].astype('category')
del tmp_df_reviews, tmp_df_payments, tmp_df_items
Verified that nothing was lost.
df_orders.shape[0]
99441
set(df_orders.order_id) == set(tmp_ids)
True
All good.
Exploring Missing Values#
Let’s examine which columns contain missing values.
df_orders.explore.anomalies_report(
anomaly_type='missing'
, width=600
)
| Count | Percent | |
|---|---|---|
| order_approved_dt | 160 | 0.2% |
| order_delivered_carrier_dt | 1783 | 1.8% |
| order_delivered_customer_dt | 2965 | 3.0% |
| order_approved_dt | order_delivered_carrier_dt | order_delivered_customer_dt | |
|---|---|---|---|
| order_approved_dt | |||
| order_delivered_carrier_dt | < 8.2% / ^ 91.2% | ||
| order_delivered_customer_dt | < 4.9% / ^ 91.2% | < 60.1% / ^ 99.9% |
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| tmp_is_delayed | Missing delivery dt | 2965 | 2965 | 100.0% | 3.0% | 99.5% | 96.5% |
| tmp_is_delivered | Not Delivered | 2963 | 2957 | 99.8% | 3.0% | 99.2% | 96.2% |
| tmp_avg_reviews_score | 1 | 11756 | 2086 | 17.7% | 11.8% | 70.0% | 58.2% |
| order_status | Shipped | 1107 | 1107 | 100.0% | 1.1% | 37.1% | 36.0% |
| tmp_product_categories | Missing in Items | 775 | 775 | 100.0% | 0.8% | 26.0% | 25.2% |
| order_status | Canceled | 625 | 619 | 99.0% | 0.6% | 20.8% | 20.1% |
| order_status | Unavailable | 609 | 609 | 100.0% | 0.6% | 20.4% | 19.8% |
| order_status | Invoiced | 314 | 314 | 100.0% | 0.3% | 10.5% | 10.2% |
| order_status | Processing | 301 | 301 | 100.0% | 0.3% | 10.1% | 9.8% |
| order_id | customer_id | order_status | order_purchase_dt | order_approved_dt | order_delivered_carrier_dt | order_delivered_customer_dt | order_estimated_delivery_dt | tmp_avg_reviews_score | tmp_payment_types | tmp_product_categories | tmp_customer_state | tmp_order_purchase_month | tmp_order_purchase_weekday | tmp_purchase_time_of_day | tmp_is_delayed | tmp_is_delivered | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 95049 | aef214f769de82d355c5d2ab49e15891 | d83a72326816260884edd05238aaa508 | Invoiced | 2016-10-06 13:07:13 | 2016-10-06 16:03:13 | NaT | NaT | 2016-12-02 00:00:00 | 5 | Credit Card | telefonia | SP | October | Thursday | Afternoon | Missing delivery dt | Not Delivered |
| 14994 | 263f5778d1130e9c186958780172a107 | 7324ecb0ff143f561193d22bea7d63fb | Canceled | 2017-10-12 08:39:30 | 2017-10-12 09:06:26 | NaT | NaT | 2017-11-06 00:00:00 | 1 | Credit Card, Voucher | dvds_blu_ray | SP | October | Thursday | Morning | Missing delivery dt | Not Delivered |
| 3786 | b07abc8b9acaf00e79b4657419f469f3 | 15308b044c9608fc82e57f2e5d6878f6 | Unavailable | 2017-03-09 17:45:04 | 2017-03-09 17:45:04 | NaT | NaT | 2017-03-28 00:00:00 | 1 | Credit Card | Missing in Items | SP | March | Thursday | Evening | Missing delivery dt | Not Delivered |
| 87216 | 560f8dd770a2b2c009a4fc935c507014 | 8ba0374666bfb38c409875762a5af81e | Shipped | 2017-12-16 18:51:09 | 2017-12-16 19:10:22 | 2017-12-19 20:28:56 | NaT | 2018-01-12 00:00:00 | 1 | Credit Card | telefonia | RJ | December | Saturday | Evening | Missing delivery dt | Not Delivered |
| 72190 | 3757dc827b45811e32f858867877df67 | 442c2a88842315cb04a3d46658371689 | Processing | 2017-08-21 10:59:48 | 2017-08-23 02:46:19 | NaT | NaT | 2017-09-14 00:00:00 | 2 | Boleto | informatica_acessorios | SP | August | Monday | Morning | Missing delivery dt | Not Delivered |
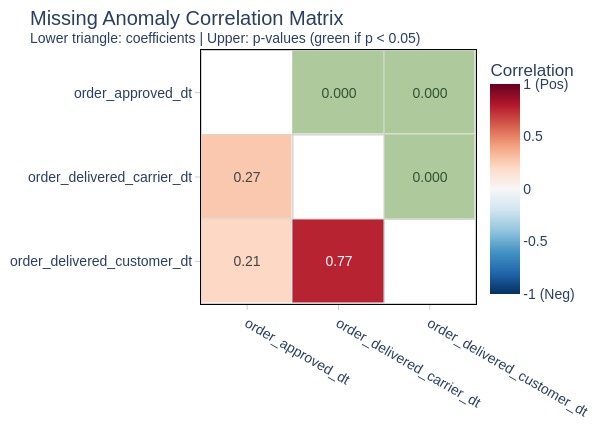
Key Observations:
Missing values in these columns likely belong to orders that did not reach a certain status.
We will analyze missing values in each column separately.
Missing in order_approved_dt
tmp_miss = df_orders[df_orders['order_approved_dt'].isna()]
Let’s examine missing values in payment approval time over time. Time will be based on order creation time.
df_orders['order_approved_dt'].explore.anomalies_over_time(
time_column='order_purchase_dt'
, anomaly_type='missing'
, freq='W'
)
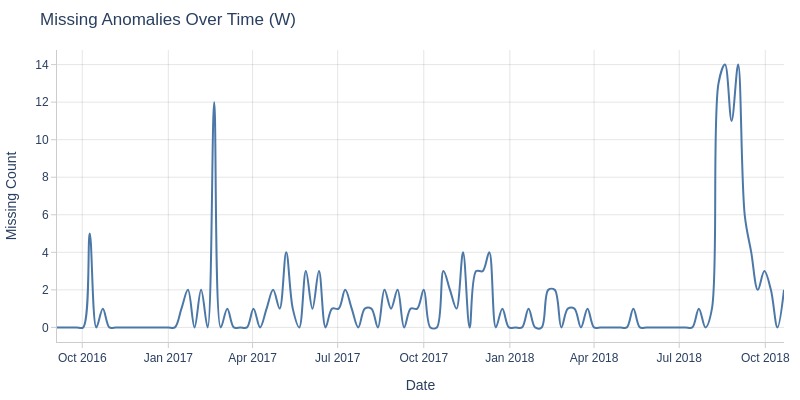
Key Observations:
In February 2017 and August 2018, there was a spike in orders missing payment approval timestamps.
Let’s analyze by order status.
df_orders['order_approved_dt'].explore.anomalies_by_categories(
anomaly_type='missing'
, pct_diff_threshold=-100
, include_columns='order_status'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| order_status | Canceled | 625 | 141 | 22.6% | 0.6% | 88.1% | 87.5% |
| order_status | Created | 5 | 5 | 100.0% | 0.0% | 3.1% | 3.1% |
| order_status | Delivered | 96478 | 14 | 0.0% | 97.0% | 8.8% | -88.3% |
Key Observations:
Missing values in the “canceled” and “created” statuses are logical.
However, 14 missing values in order_approved_dt for orders with “delivered” status are unusual.
Let’s examine these 14 delivered orders with missing order_approved_dt.
tmp_miss[lambda x: x.order_status == 'Delivered']
| order_id | customer_id | order_status | order_purchase_dt | order_approved_dt | order_delivered_carrier_dt | order_delivered_customer_dt | order_estimated_delivery_dt | tmp_avg_reviews_score | tmp_payment_types | tmp_product_categories | tmp_customer_state | tmp_order_purchase_month | tmp_order_purchase_weekday | tmp_purchase_time_of_day | tmp_is_delayed | tmp_is_delivered | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5323 | e04abd8149ef81b95221e88f6ed9ab6a | 2127dc6603ac33544953ef05ec155771 | Delivered | 2017-02-18 14:40:00 | NaT | 2017-02-23 12:04:47 | 2017-03-01 13:25:33 | 2017-03-17 | 4 | Boleto | eletroportateis | SP | February | Saturday | Afternoon | Not Delayed | Delivered |
| 16567 | 8a9adc69528e1001fc68dd0aaebbb54a | 4c1ccc74e00993733742a3c786dc3c1f | Delivered | 2017-02-18 12:45:31 | NaT | 2017-02-23 09:01:52 | 2017-03-02 10:05:06 | 2017-03-21 | 5 | Boleto | construcao_ferramentas_seguranca | RS | February | Saturday | Afternoon | Not Delayed | Delivered |
| 19031 | 7013bcfc1c97fe719a7b5e05e61c12db | 2941af76d38100e0f8740a374f1a5dc3 | Delivered | 2017-02-18 13:29:47 | NaT | 2017-02-22 16:25:25 | 2017-03-01 08:07:38 | 2017-03-17 | 5 | Boleto | missed in df_products | SP | February | Saturday | Afternoon | Not Delayed | Delivered |
| 22663 | 5cf925b116421afa85ee25e99b4c34fb | 29c35fc91fc13fb5073c8f30505d860d | Delivered | 2017-02-18 16:48:35 | NaT | 2017-02-22 11:23:10 | 2017-03-09 07:28:47 | 2017-03-31 | 5 | Boleto | cool_stuff | CE | February | Saturday | Afternoon | Not Delayed | Delivered |
| 23156 | 12a95a3c06dbaec84bcfb0e2da5d228a | 1e101e0daffaddce8159d25a8e53f2b2 | Delivered | 2017-02-17 13:05:55 | NaT | 2017-02-22 11:23:11 | 2017-03-02 11:09:19 | 2017-03-20 | 5 | Boleto | cool_stuff | RJ | February | Friday | Afternoon | Not Delayed | Delivered |
| 26800 | c1d4211b3dae76144deccd6c74144a88 | 684cb238dc5b5d6366244e0e0776b450 | Delivered | 2017-01-19 12:48:08 | NaT | 2017-01-25 14:56:50 | 2017-01-30 18:16:01 | 2017-03-01 | 4 | Boleto | esporte_lazer | SP | January | Thursday | Afternoon | Not Delayed | Delivered |
| 38290 | d69e5d356402adc8cf17e08b5033acfb | 68d081753ad4fe22fc4d410a9eb1ca01 | Delivered | 2017-02-19 01:28:47 | NaT | 2017-02-23 03:11:48 | 2017-03-02 03:41:58 | 2017-03-27 | 5 | Boleto | moveis_decoracao | SP | February | Sunday | Night | Not Delayed | Delivered |
| 39334 | d77031d6a3c8a52f019764e68f211c69 | 0bf35cac6cc7327065da879e2d90fae8 | Delivered | 2017-02-18 11:04:19 | NaT | 2017-02-23 07:23:36 | 2017-03-02 16:15:23 | 2017-03-22 | 5 | Boleto | esporte_lazer | SP | February | Saturday | Morning | Not Delayed | Delivered |
| 48401 | 7002a78c79c519ac54022d4f8a65e6e8 | d5de688c321096d15508faae67a27051 | Delivered | 2017-01-19 22:26:59 | NaT | 2017-01-27 11:08:05 | 2017-02-06 14:22:19 | 2017-03-16 | 2 | Boleto | moveis_decoracao | MG | January | Thursday | Evening | Not Delayed | Delivered |
| 61743 | 2eecb0d85f281280f79fa00f9cec1a95 | a3d3c38e58b9d2dfb9207cab690b6310 | Delivered | 2017-02-17 17:21:55 | NaT | 2017-02-22 11:42:51 | 2017-03-03 12:16:03 | 2017-03-20 | 5 | Boleto | ferramentas_jardim | MG | February | Friday | Evening | Not Delayed | Delivered |
| 63052 | 51eb2eebd5d76a24625b31c33dd41449 | 07a2a7e0f63fd8cb757ed77d4245623c | Delivered | 2017-02-18 15:52:27 | NaT | 2017-02-23 03:09:14 | 2017-03-07 13:57:47 | 2017-03-29 | 5 | Boleto | moveis_decoracao | MG | February | Saturday | Afternoon | Not Delayed | Delivered |
| 67697 | 88083e8f64d95b932164187484d90212 | f67cd1a215aae2a1074638bbd35a223a | Delivered | 2017-02-18 22:49:19 | NaT | 2017-02-22 11:31:06 | 2017-03-02 12:06:06 | 2017-03-21 | 4 | Boleto | telefonia | RJ | February | Saturday | Evening | Not Delayed | Delivered |
| 72407 | 3c0b8706b065f9919d0505d3b3343881 | d85919cb3c0529589c6fa617f5f43281 | Delivered | 2017-02-17 15:53:27 | NaT | 2017-02-22 11:31:30 | 2017-03-03 11:47:47 | 2017-03-23 | 3 | Boleto | cama_mesa_banho | RS | February | Friday | Afternoon | Not Delayed | Delivered |
| 84999 | 2babbb4b15e6d2dfe95e2de765c97bce | 74bebaf46603f9340e3b50c6b086f992 | Delivered | 2017-02-18 17:15:03 | NaT | 2017-02-22 11:23:11 | 2017-03-03 18:43:43 | 2017-03-31 | 4 | Boleto | cool_stuff | MA | February | Saturday | Evening | Not Delayed | Delivered |
Key Observations:
All delivered orders with missing order_approved_dt used “boleto” as the payment method. This may be a characteristic of “boleto” usage.
All these orders were placed in January and February 2017. There may have been a system issue where approval timestamps were not saved.
Let’s examine the 5 created orders that have missing values in the payment approval time.
Let’s look at 5 “created” orders with missing payment approval timestamps.
tmp_miss[lambda x: x.order_status == 'Created']
| order_id | customer_id | order_status | order_purchase_dt | order_approved_dt | order_delivered_carrier_dt | order_delivered_customer_dt | order_estimated_delivery_dt | tmp_avg_reviews_score | tmp_payment_types | tmp_product_categories | tmp_customer_state | tmp_order_purchase_month | tmp_order_purchase_weekday | tmp_purchase_time_of_day | tmp_is_delayed | tmp_is_delivered | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 7434 | b5359909123fa03c50bdb0cfed07f098 | 438449d4af8980d107bf04571413a8e7 | Created | 2017-12-05 01:07:52 | NaT | NaT | NaT | 2018-01-11 | 1 | Credit Card | Missing in Items | SP | December | Tuesday | Night | Missing delivery dt | Not Delivered |
| 9238 | dba5062fbda3af4fb6c33b1e040ca38f | 964a6df3d9bdf60fe3e7b8bb69ed893a | Created | 2018-02-09 17:21:04 | NaT | NaT | NaT | 2018-03-07 | 1 | Boleto | Missing in Items | DF | February | Friday | Evening | Missing delivery dt | Not Delivered |
| 21441 | 7a4df5d8cff4090e541401a20a22bb80 | 725e9c75605414b21fd8c8d5a1c2f1d6 | Created | 2017-11-25 11:10:33 | NaT | NaT | NaT | 2017-12-12 | 1 | Boleto | Missing in Items | RJ | November | Saturday | Morning | Missing delivery dt | Not Delivered |
| 55086 | 35de4050331c6c644cddc86f4f2d0d64 | 4ee64f4bfc542546f422da0aeb462853 | Created | 2017-12-05 01:07:58 | NaT | NaT | NaT | 2018-01-08 | 1 | Credit Card | Missing in Items | RS | December | Tuesday | Night | Missing delivery dt | Not Delivered |
| 58958 | 90ab3e7d52544ec7bc3363c82689965f | 7d61b9f4f216052ba664f22e9c504ef1 | Created | 2017-11-06 13:12:34 | NaT | NaT | NaT | 2017-12-01 | 5 | Credit Card | Missing in Items | PR | November | Monday | Afternoon | Missing delivery dt | Not Delivered |
Key Observations:
Orders with “created” status and missing payment approval timestamps were placed long ago and never delivered. The data may not have been processed.
Let’s analyze by average order review score.
df_orders['order_approved_dt'].explore.anomalies_by_categories(
anomaly_type='missing'
, pct_diff_threshold=-100
, include_columns='tmp_avg_reviews_score'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| tmp_avg_reviews_score | 1 | 11756 | 67 | 0.6% | 11.8% | 41.9% | 30.1% |
| tmp_avg_reviews_score | 2 | 3244 | 16 | 0.5% | 3.3% | 10.0% | 6.7% |
| tmp_avg_reviews_score | 3 | 8268 | 18 | 0.2% | 8.3% | 11.2% | 2.9% |
| tmp_avg_reviews_score | 4 | 19129 | 16 | 0.1% | 19.2% | 10.0% | -9.2% |
| tmp_avg_reviews_score | 5 | 57044 | 43 | 0.1% | 57.4% | 26.9% | -30.5% |
Key Observations:
The difference in proportions is significantly higher for score 1. These orders were likely not delivered.
Let’s examine a word cloud from review messages.
tmp_miss = tmp_miss.merge(df_reviews, on='order_id', how='left')
tmp_miss.viz.wordcloud('review_comment_message')
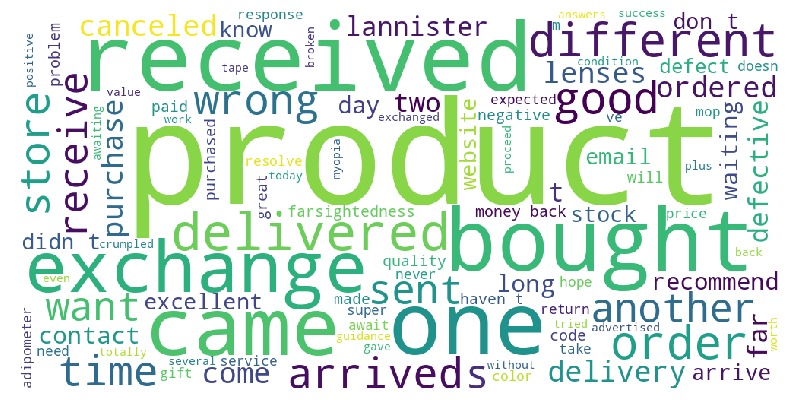
Key Observations:
Many words relate to delivery.
Let’s analyze the sentiment of the text.
tmp_miss.analysis.sentiment('review_comment_message')
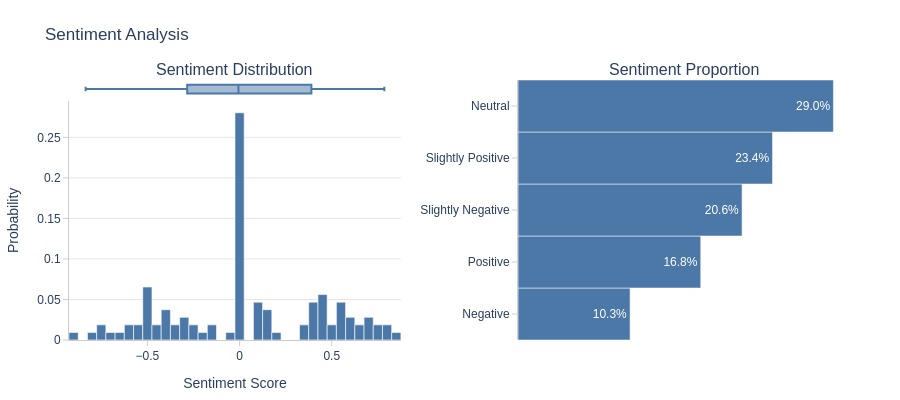
Key Observations:
The sentiment is not predominantly negative.
Let’s randomly sample 20 review comments. We’ll repeat this several times.
messages = (
tmp_miss['review_comment_message']
.dropna()
.sample(20)
.tolist()
)
display(messages)
['contact lenses are positive for farsightedness or negative for myopia i have farsightedness i need plus lenses negative lenses were delivered no one answers me to resolve',
'product did not come as purchased',
'the product i ordered came in a number different from the one i ordered',
'the product arrived at me diverging from what was reported on the website about how it works missing speed reducer button',
'contact lenses are positive for farsightedness or negative for myopia i have farsightedness i need plus lenses negative lenses were delivered no one answers me to resolve',
'although the product was out of stock the company made contact to notify and canceled the order',
'more than 30 days after the purchase was made i received an email stating that the product i purchased was no longer available simply a disregard for the consumer and a regrettable service',
'excellent',
'i believe the order has been cancelled',
'they exchanged my product they sent me someone else s product',
'delivery of the product different from the one ordered i await guidance for the exchange',
'congratulations',
'i did not receive the product it was canceled on request before billing',
'i always buy from lannister stores and i ve never had any problems i think it s safe',
'product was supposed to arrive on the 04/01th and until today nothing a huge amount of nonsense i want urgent provisions to be taken',
'i m waiting could you send a confirmation if it will be delivered',
'easy to assemble',
'product different than advertised',
'i am super disappointed the product came before the deadline but it has come wrong and so far i could not exchange or cancel the purchase',
'and remold is not reliable']
Key Observations:
Based on review messages, many orders were not delivered, but a significant number were delivered.
Therefore, missing payment approval timestamps cannot be assumed to indicate order cancellation.
Let’s analyze by payment type.
df_orders['order_approved_dt'].explore.anomalies_by_categories(
anomaly_type='missing'
, pct_diff_threshold=-100
, include_columns='tmp_payment_types'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| tmp_payment_types | Voucher | 1621 | 71 | 4.4% | 1.6% | 44.4% | 42.7% |
| tmp_payment_types | Not Defined | 3 | 3 | 100.0% | 0.0% | 1.9% | 1.9% |
| tmp_payment_types | Voucher, Credit Card | 1118 | 1 | 0.1% | 1.1% | 0.6% | -0.5% |
| tmp_payment_types | Credit Card, Voucher | 1127 | 1 | 0.1% | 1.1% | 0.6% | -0.5% |
| tmp_payment_types | Boleto | 19784 | 30 | 0.2% | 19.9% | 18.8% | -1.1% |
| tmp_payment_types | Credit Card | 74259 | 54 | 0.1% | 74.7% | 33.8% | -40.9% |
Key Observations:
The proportion of “voucher” payments in missing values has increased significantly. This payment type is notably more frequent in missing values.
The “voucher” payment type has a stronger correlation with missing payment approval timestamps. This is likely a characteristic of this payment method.
Let’s analyze by month.
df_orders['order_approved_dt'].explore.anomalies_by_categories(
anomaly_type='missing'
, pct_diff_threshold=-100
, include_columns='tmp_order_purchase_month'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| tmp_order_purchase_month | August | 10843 | 59 | 0.5% | 10.9% | 36.9% | 26.0% |
| tmp_order_purchase_month | September | 4305 | 19 | 0.4% | 4.3% | 11.9% | 7.5% |
| tmp_order_purchase_month | October | 4959 | 15 | 0.3% | 5.0% | 9.4% | 4.4% |
| tmp_order_purchase_month | February | 8508 | 18 | 0.2% | 8.6% | 11.2% | 2.7% |
| tmp_order_purchase_month | December | 5674 | 7 | 0.1% | 5.7% | 4.4% | -1.3% |
| tmp_order_purchase_month | November | 7544 | 9 | 0.1% | 7.6% | 5.6% | -2.0% |
| tmp_order_purchase_month | May | 10573 | 10 | 0.1% | 10.6% | 6.2% | -4.4% |
| tmp_order_purchase_month | January | 8069 | 4 | 0.0% | 8.1% | 2.5% | -5.6% |
| tmp_order_purchase_month | July | 10318 | 6 | 0.1% | 10.4% | 3.8% | -6.6% |
| tmp_order_purchase_month | March | 9893 | 5 | 0.1% | 9.9% | 3.1% | -6.8% |
| tmp_order_purchase_month | April | 9343 | 4 | 0.0% | 9.4% | 2.5% | -6.9% |
| tmp_order_purchase_month | June | 9412 | 4 | 0.0% | 9.5% | 2.5% | -7.0% |
Key Observations:
August has a noticeably higher proportion of missing values than other months. This is also visible in the graph above.
Missing Values in order_delivered_carrier_dt
tmp_miss = df_orders[df_orders['order_delivered_carrier_dt'].isna()]
Let’s examine the distribution of missing values in the carrier handover time.
df_orders['order_delivered_carrier_dt'].explore.anomalies_over_time(
time_column='order_purchase_dt'
, anomaly_type='missing'
, freq='W'
)
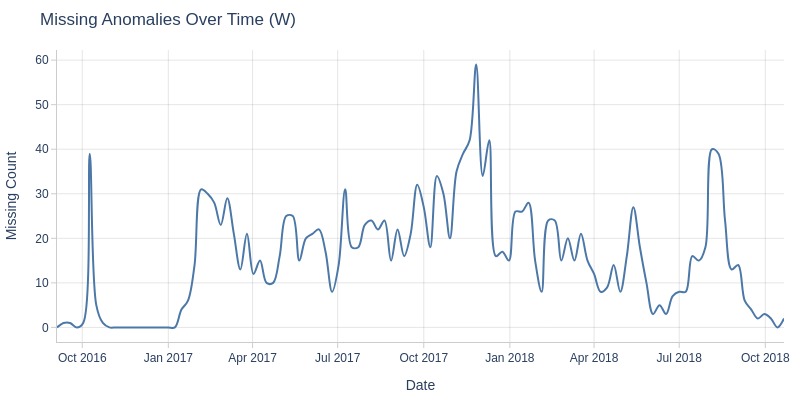
Key Observations:
In November 2017, there was a spike in orders missing carrier handover timestamps. This may be related to Black Friday.
Let’s analyze by order status.
df_orders['order_delivered_carrier_dt'].explore.anomalies_by_categories(
anomaly_type='missing'
, pct_diff_threshold=-100
, include_columns='order_status'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| order_status | Unavailable | 609 | 609 | 100.0% | 0.6% | 34.2% | 33.5% |
| order_status | Canceled | 625 | 550 | 88.0% | 0.6% | 30.8% | 30.2% |
| order_status | Invoiced | 314 | 314 | 100.0% | 0.3% | 17.6% | 17.3% |
| order_status | Processing | 301 | 301 | 100.0% | 0.3% | 16.9% | 16.6% |
| order_status | Created | 5 | 5 | 100.0% | 0.0% | 0.3% | 0.3% |
| order_status | Approved | 2 | 2 | 100.0% | 0.0% | 0.1% | 0.1% |
| order_status | Delivered | 96478 | 2 | 0.0% | 97.0% | 0.1% | -96.9% |
Key Observations:
There are 2 delivered orders with missing order_delivered_carrier_dt.
All orders with “unavailable” status have missing order_delivered_carrier_dt.
Let’s examine these 2 delivered orders.
tmp_miss[lambda x: x.order_status == 'Delivered'].merge(df_payments, on='order_id', how='left')
| order_id | customer_id | order_status | order_purchase_dt | order_approved_dt | order_delivered_carrier_dt | order_delivered_customer_dt | order_estimated_delivery_dt | tmp_avg_reviews_score | tmp_payment_types | tmp_product_categories | tmp_customer_state | tmp_order_purchase_month | tmp_order_purchase_weekday | tmp_purchase_time_of_day | tmp_is_delayed | tmp_is_delivered | payment_sequential | payment_type | payment_installments | payment_value | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2aa91108853cecb43c84a5dc5b277475 | afeb16c7f46396c0ed54acb45ccaaa40 | Delivered | 2017-09-29 08:52:58 | 2017-09-29 09:07:16 | NaT | 2017-11-20 19:44:47 | 2017-11-14 | 5 | Credit Card | moveis_decoracao | SP | September | Friday | Morning | Delayed | Delivered | 1 | Credit Card | 1 | 193.98 |
| 1 | 2d858f451373b04fb5c984a1cc2defaf | e08caf668d499a6d643dafd7c5cc498a | Delivered | 2017-05-25 23:22:43 | 2017-05-25 23:30:16 | NaT | NaT | 2017-06-23 | 5 | Credit Card | esporte_lazer | RS | May | Thursday | Night | Missing delivery dt | Delivered | 1 | Credit Card | 4 | 194.00 |
Key Observations:
Both orders with missing order_delivered_carrier_dt were paid via credit card.
Let’s analyze by average review score.
df_orders['order_delivered_carrier_dt'].explore.anomalies_by_categories(
anomaly_type='missing'
, pct_diff_threshold=-100
, include_columns='tmp_avg_reviews_score'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| tmp_avg_reviews_score | 1 | 11756 | 1350 | 11.5% | 11.8% | 75.7% | 63.9% |
| tmp_avg_reviews_score | 2 | 3244 | 133 | 4.1% | 3.3% | 7.5% | 4.2% |
| tmp_avg_reviews_score | 3 | 8268 | 107 | 1.3% | 8.3% | 6.0% | -2.3% |
| tmp_avg_reviews_score | 4 | 19129 | 64 | 0.3% | 19.2% | 3.6% | -15.6% |
| tmp_avg_reviews_score | 5 | 57044 | 129 | 0.2% | 57.4% | 7.2% | -50.1% |
Key Observations:
The difference in proportions is significantly higher for score 1. These orders were likely not delivered.
Review score 1 has the strongest correlation with missing carrier handover timestamps. This suggests these orders were not delivered, and customers were highly dissatisfied.
Let’s examine a word cloud from review messages.
tmp_miss = tmp_miss.merge(df_reviews, on='order_id', how='left')
tmp_miss.viz.wordcloud('review_comment_message')

Key Observations:
Many words relate to delivery.
Let’s analyze the sentiment of the text.
tmp_miss.analysis.sentiment('review_comment_message')
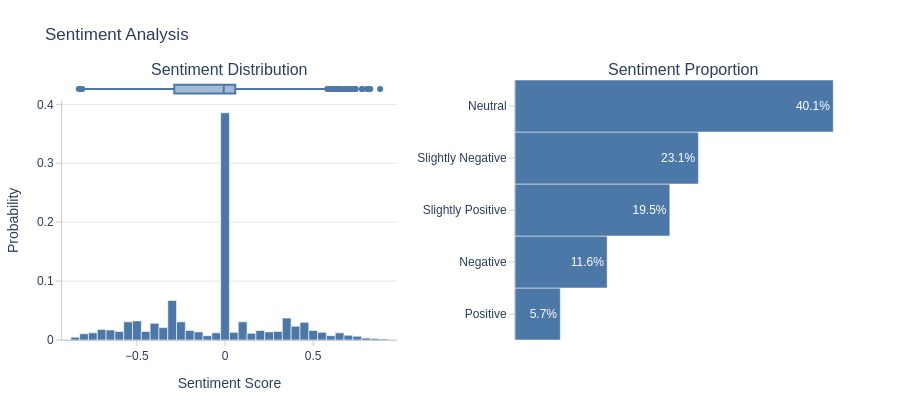
Key Observations:
Negative reviews outnumber positive ones, and the boxplot body lies mostly below 0.
Let’s randomly sample 20 review comments. We’ll repeat this several times.
messages = (
tmp_miss['review_comment_message']
.dropna()
.sample(20)
.tolist()
)
display(messages)
['the supplier got in touch but did not provide any solution or delivery time it was not responsible for the delay it blamed a third party i just bought it and i want to receive it',
'until now i have not received my product i would like an opinion on delivery',
'product not delivered',
'i have not received the product because the seller cannot invoice in the name of the company with the cnpj requested purchase cancellation',
'the company doesn t have the product to deliver and canceled the purchase but the charge came on my credit card statement and they didn t even give a satisfaction about the reversal of the charge',
'i bought a product that was not available i suggest that you review the site every hour to avoid this type of inconvenience',
'no communication was passed to me',
'i bought the charger thinking of taking it on a trip i trusted the delivery time but i was fooled because the product has not yet arrived i requested the cancellation of the purchase disappointing',
'i have not received the product',
'dear; to date the product has not been delivered to me i would like to know what steps lannisters com will take so that i don t end up at a loss it was my 1st purchase to test the store',
'top product came on time',
'i bought it and until today it has not been delivered',
'i didn t receive the product',
'not at all satisfied because we bought the products they did not arrive on the expected date we are very upset with the site we need an urgent response from you',
'it took too long to inform that the product didn t have it in stock',
'the seller did not have the ordered product canceled',
'the product has not been delivered',
'it s been a month since i bought it and so far i haven t received all the merchandise purchased',
'product unavailable after purchase approval i would not recommend a partner i was very dissatisfied',
'the purchase was canceled without me asking']
Key Observations:
Based on review messages, many orders were not delivered, but a significant number were delivered.
Orders with missing carrier handover timestamps were more frequently undelivered compared to those with missing payment approval timestamps.
Some products may have been out of stock, and sellers did not hand them over to carriers.
However, since many orders were still delivered, missing values cannot be assumed to indicate order cancellation.
Let’s analyze by customer state.
df_orders['order_delivered_carrier_dt'].explore.anomalies_by_categories(
anomaly_type='missing'
, include_columns='tmp_customer_state'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| tmp_customer_state | SP | 41746 | 888 | 2.1% | 42.0% | 49.8% | 7.8% |
| tmp_customer_state | RO | 253 | 10 | 4.0% | 0.3% | 0.6% | 0.3% |
| tmp_customer_state | PI | 495 | 11 | 2.2% | 0.5% | 0.6% | 0.1% |
| tmp_customer_state | PR | 5045 | 91 | 1.8% | 5.1% | 5.1% | 0.0% |
| tmp_customer_state | RR | 46 | 1 | 2.2% | 0.0% | 0.1% | 0.0% |
| tmp_customer_state | AP | 68 | 1 | 1.5% | 0.1% | 0.1% | -0.0% |
| tmp_customer_state | SE | 350 | 6 | 1.7% | 0.4% | 0.3% | -0.0% |
| tmp_customer_state | AL | 413 | 7 | 1.7% | 0.4% | 0.4% | -0.0% |
| tmp_customer_state | MA | 747 | 12 | 1.6% | 0.8% | 0.7% | -0.1% |
| tmp_customer_state | PB | 536 | 8 | 1.5% | 0.5% | 0.4% | -0.1% |
| tmp_customer_state | AM | 148 | 1 | 0.7% | 0.1% | 0.1% | -0.1% |
| tmp_customer_state | MS | 715 | 11 | 1.5% | 0.7% | 0.6% | -0.1% |
| tmp_customer_state | TO | 280 | 2 | 0.7% | 0.3% | 0.1% | -0.2% |
| tmp_customer_state | RN | 485 | 4 | 0.8% | 0.5% | 0.2% | -0.3% |
| tmp_customer_state | SC | 3637 | 60 | 1.6% | 3.7% | 3.4% | -0.3% |
| tmp_customer_state | GO | 2020 | 31 | 1.5% | 2.0% | 1.7% | -0.3% |
| tmp_customer_state | MG | 11635 | 203 | 1.7% | 11.7% | 11.4% | -0.3% |
| tmp_customer_state | CE | 1336 | 18 | 1.3% | 1.3% | 1.0% | -0.3% |
| tmp_customer_state | PE | 1652 | 23 | 1.4% | 1.7% | 1.3% | -0.4% |
| tmp_customer_state | BA | 3380 | 53 | 1.6% | 3.4% | 3.0% | -0.4% |
| tmp_customer_state | DF | 2140 | 30 | 1.4% | 2.2% | 1.7% | -0.5% |
| tmp_customer_state | PA | 975 | 9 | 0.9% | 1.0% | 0.5% | -0.5% |
| tmp_customer_state | MT | 907 | 6 | 0.7% | 0.9% | 0.3% | -0.6% |
| tmp_customer_state | RS | 5466 | 84 | 1.5% | 5.5% | 4.7% | -0.8% |
| tmp_customer_state | ES | 2033 | 19 | 0.9% | 2.0% | 1.1% | -1.0% |
| tmp_customer_state | RJ | 12852 | 194 | 1.5% | 12.9% | 10.9% | -2.0% |
Key Observations:
The difference in proportions is slightly higher in São Paulo compared to other states.
Missing Values in order_delivered_customer_dt
tmp_miss = df_orders[df_orders['order_delivered_customer_dt'].isna()]
Let’s examine the distribution of missing values in customer delivery time.
df_orders['order_delivered_customer_dt'].explore.anomalies_over_time(
time_column='order_purchase_dt'
, anomaly_type='missing'
, freq='W'
)
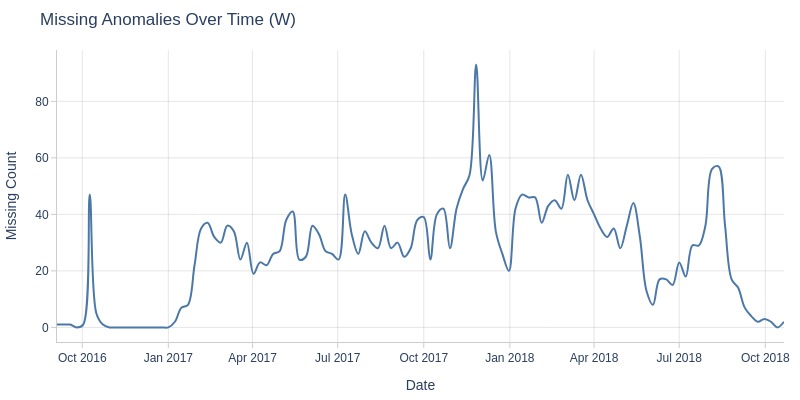
Key Observations:
In November 2017, there was a spike in orders missing customer delivery timestamps.
Let’s analyze by order status.
df_orders['order_delivered_customer_dt'].explore.anomalies_by_categories(
anomaly_type='missing'
, pct_diff_threshold=-100
, include_columns='order_status'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| order_status | Shipped | 1107 | 1107 | 100.0% | 1.1% | 37.3% | 36.2% |
| order_status | Canceled | 625 | 619 | 99.0% | 0.6% | 20.9% | 20.2% |
| order_status | Unavailable | 609 | 609 | 100.0% | 0.6% | 20.5% | 19.9% |
| order_status | Invoiced | 314 | 314 | 100.0% | 0.3% | 10.6% | 10.3% |
| order_status | Processing | 301 | 301 | 100.0% | 0.3% | 10.2% | 9.8% |
| order_status | Created | 5 | 5 | 100.0% | 0.0% | 0.2% | 0.2% |
| order_status | Approved | 2 | 2 | 100.0% | 0.0% | 0.1% | 0.1% |
| order_status | Delivered | 96478 | 8 | 0.0% | 97.0% | 0.3% | -96.8% |
Key Observations:
There are 8 orders with “delivered” status but missing delivery timestamps.
Let’s analyze by customer state.
df_orders['order_delivered_customer_dt'].explore.anomalies_by_categories(
anomaly_type='missing'
, include_columns='tmp_customer_state'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| tmp_customer_state | RJ | 12852 | 499 | 3.9% | 12.9% | 16.8% | 3.9% |
| tmp_customer_state | BA | 3380 | 124 | 3.7% | 3.4% | 4.2% | 0.8% |
| tmp_customer_state | CE | 1336 | 57 | 4.3% | 1.3% | 1.9% | 0.6% |
| tmp_customer_state | PE | 1652 | 59 | 3.6% | 1.7% | 2.0% | 0.3% |
| tmp_customer_state | MA | 747 | 30 | 4.0% | 0.8% | 1.0% | 0.3% |
| tmp_customer_state | SP | 41746 | 1251 | 3.0% | 42.0% | 42.2% | 0.2% |
| tmp_customer_state | SE | 350 | 15 | 4.3% | 0.4% | 0.5% | 0.2% |
| tmp_customer_state | PI | 495 | 19 | 3.8% | 0.5% | 0.6% | 0.1% |
| tmp_customer_state | AL | 413 | 16 | 3.9% | 0.4% | 0.5% | 0.1% |
| tmp_customer_state | RR | 46 | 5 | 10.9% | 0.0% | 0.2% | 0.1% |
| tmp_customer_state | PB | 536 | 19 | 3.5% | 0.5% | 0.6% | 0.1% |
| tmp_customer_state | GO | 2020 | 63 | 3.1% | 2.0% | 2.1% | 0.1% |
| tmp_customer_state | RO | 253 | 10 | 4.0% | 0.3% | 0.3% | 0.1% |
| tmp_customer_state | PA | 975 | 29 | 3.0% | 1.0% | 1.0% | -0.0% |
| tmp_customer_state | AP | 68 | 1 | 1.5% | 0.1% | 0.0% | -0.0% |
| tmp_customer_state | AM | 148 | 3 | 2.0% | 0.1% | 0.1% | -0.0% |
| tmp_customer_state | AC | 81 | 1 | 1.2% | 0.1% | 0.0% | -0.0% |
| tmp_customer_state | TO | 280 | 6 | 2.1% | 0.3% | 0.2% | -0.1% |
| tmp_customer_state | RN | 485 | 11 | 2.3% | 0.5% | 0.4% | -0.1% |
| tmp_customer_state | DF | 2140 | 60 | 2.8% | 2.2% | 2.0% | -0.1% |
| tmp_customer_state | MT | 907 | 21 | 2.3% | 0.9% | 0.7% | -0.2% |
| tmp_customer_state | MS | 715 | 14 | 2.0% | 0.7% | 0.5% | -0.2% |
| tmp_customer_state | SC | 3637 | 90 | 2.5% | 3.7% | 3.0% | -0.6% |
| tmp_customer_state | ES | 2033 | 38 | 1.9% | 2.0% | 1.3% | -0.8% |
| tmp_customer_state | PR | 5045 | 122 | 2.4% | 5.1% | 4.1% | -1.0% |
| tmp_customer_state | RS | 5466 | 122 | 2.2% | 5.5% | 4.1% | -1.4% |
| tmp_customer_state | MG | 11635 | 280 | 2.4% | 11.7% | 9.4% | -2.3% |
Key Observations:
The difference in proportions is slightly higher in Rio de Janeiro.
Let’s examine these 8 delivered orders.
tmp_miss[lambda x: x.order_status == 'Delivered'].merge(df_payments, on='order_id', how='left')
| order_id | customer_id | order_status | order_purchase_dt | order_approved_dt | order_delivered_carrier_dt | order_delivered_customer_dt | order_estimated_delivery_dt | tmp_avg_reviews_score | tmp_payment_types | tmp_product_categories | tmp_customer_state | tmp_order_purchase_month | tmp_order_purchase_weekday | tmp_purchase_time_of_day | tmp_is_delayed | tmp_is_delivered | payment_sequential | payment_type | payment_installments | payment_value | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2d1e2d5bf4dc7227b3bfebb81328c15f | ec05a6d8558c6455f0cbbd8a420ad34f | Delivered | 2017-11-28 17:44:07 | 2017-11-28 17:56:40 | 2017-11-30 18:12:23 | NaT | 2017-12-18 | 5 | Credit Card | automotivo | SP | November | Tuesday | Evening | Missing delivery dt | Delivered | 1 | Credit Card | 3 | 134.83 |
| 1 | f5dd62b788049ad9fc0526e3ad11a097 | 5e89028e024b381dc84a13a3570decb4 | Delivered | 2018-06-20 06:58:43 | 2018-06-20 07:19:05 | 2018-06-25 08:05:00 | NaT | 2018-07-16 | 5 | Debit Card | industria_comercio_e_negocios | SP | June | Wednesday | Morning | Missing delivery dt | Delivered | 1 | Debit Card | 1 | 354.24 |
| 2 | 2ebdfc4f15f23b91474edf87475f108e | 29f0540231702fda0cfdee0a310f11aa | Delivered | 2018-07-01 17:05:11 | 2018-07-01 17:15:12 | 2018-07-03 13:57:00 | NaT | 2018-07-30 | 5 | Credit Card | relogios_presentes | SP | July | Sunday | Evening | Missing delivery dt | Delivered | 1 | Credit Card | 3 | 158.07 |
| 3 | e69f75a717d64fc5ecdfae42b2e8e086 | cfda40ca8dd0a5d486a9635b611b398a | Delivered | 2018-07-01 22:05:55 | 2018-07-01 22:15:14 | 2018-07-03 13:57:00 | NaT | 2018-07-30 | 5 | Credit Card | relogios_presentes | SP | July | Sunday | Evening | Missing delivery dt | Delivered | 1 | Credit Card | 1 | 158.07 |
| 4 | 0d3268bad9b086af767785e3f0fc0133 | 4f1d63d35fb7c8999853b2699f5c7649 | Delivered | 2018-07-01 21:14:02 | 2018-07-01 21:29:54 | 2018-07-03 09:28:00 | NaT | 2018-07-24 | 5 | Credit Card | brinquedos | SP | July | Sunday | Evening | Missing delivery dt | Delivered | 1 | Credit Card | 4 | 204.62 |
| 5 | 2d858f451373b04fb5c984a1cc2defaf | e08caf668d499a6d643dafd7c5cc498a | Delivered | 2017-05-25 23:22:43 | 2017-05-25 23:30:16 | NaT | NaT | 2017-06-23 | 5 | Credit Card | esporte_lazer | RS | May | Thursday | Night | Missing delivery dt | Delivered | 1 | Credit Card | 4 | 194.00 |
| 6 | ab7c89dc1bf4a1ead9d6ec1ec8968a84 | dd1b84a7286eb4524d52af4256c0ba24 | Delivered | 2018-06-08 12:09:39 | 2018-06-08 12:36:39 | 2018-06-12 14:10:00 | NaT | 2018-06-26 | 1 | Credit Card | informatica_acessorios | SP | June | Friday | Afternoon | Missing delivery dt | Delivered | 1 | Credit Card | 5 | 120.12 |
| 7 | 20edc82cf5400ce95e1afacc25798b31 | 28c37425f1127d887d7337f284080a0f | Delivered | 2018-06-27 16:09:12 | 2018-06-27 16:29:30 | 2018-07-03 19:26:00 | NaT | 2018-07-19 | 5 | Credit Card | livros_interesse_geral | SP | June | Wednesday | Afternoon | Missing delivery dt | Delivered | 1 | Credit Card | 1 | 54.97 |
Key Observations:
7 out of 8 orders with missing order_delivered_customer_dt were paid via credit card, and 1 was paid via debit card.
Let’s analyze by average review score.
df_orders['order_delivered_customer_dt'].explore.anomalies_by_categories(
anomaly_type='missing'
, pct_diff_threshold=-100
, include_columns='tmp_avg_reviews_score'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| tmp_avg_reviews_score | 1 | 11756 | 2086 | 17.7% | 11.8% | 70.4% | 58.5% |
| tmp_avg_reviews_score | 2 | 3244 | 223 | 6.9% | 3.3% | 7.5% | 4.3% |
| tmp_avg_reviews_score | 3 | 8268 | 235 | 2.8% | 8.3% | 7.9% | -0.4% |
| tmp_avg_reviews_score | 4 | 19129 | 156 | 0.8% | 19.2% | 5.3% | -14.0% |
| tmp_avg_reviews_score | 5 | 57044 | 265 | 0.5% | 57.4% | 8.9% | -48.4% |
Key Observations:
The difference in proportions is significantly higher for score 1. These orders were likely not delivered.
Let’s examine a word cloud from review messages.
tmp_miss = tmp_miss.merge(df_reviews, on='order_id', how='left')
tmp_miss.viz.wordcloud('review_comment_message')
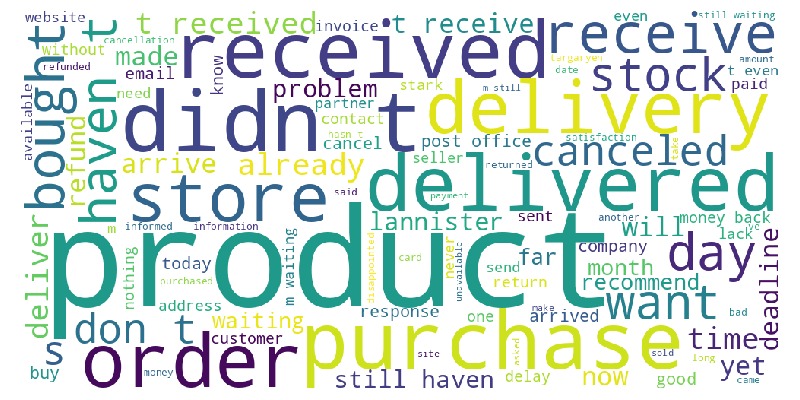
Key Observations:
Many words relate to delivery.
Let’s analyze the sentiment of the text.
tmp_miss.analysis.sentiment('review_comment_message')
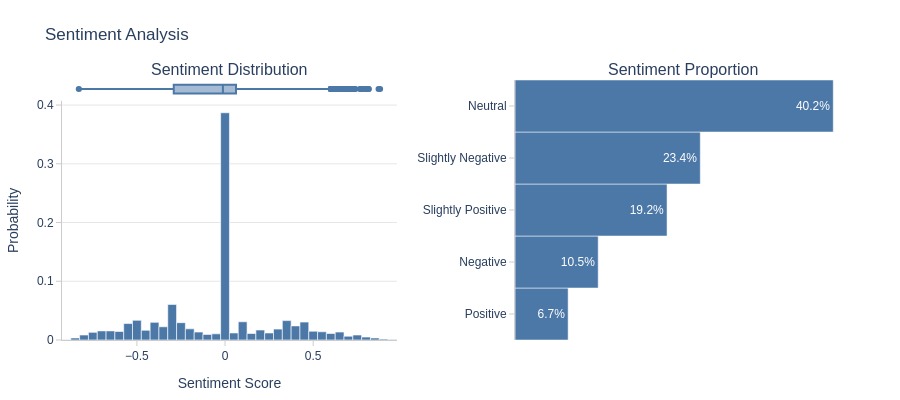
Key Observations:
Negative reviews outnumber positive ones, and the boxplot body lies mostly below 0.
Let’s randomly sample 20 review comments.
We’ll repeat this several times.
messages = (
tmp_miss['review_comment_message']
.dropna()
.sample(20)
.tolist()
)
display(messages)
['good afternoon to date i still have not received my purchase i tried to contact you and i couldn t i want the amount paid to be refunded or the merchandise urgently awaiting return',
'good morning i received my order on time but the pushing ball came dry and peeling how should i proceed to receive one in good condition awaiting vanessa',
'total neglect of the store does not receive the product and they did not contact me a long time later they sent an email to my sister and did not even leave a phone number for me to contact the store i do not recommend',
'until now i have not received my product i would like an opinion on delivery',
'i am disappointed with delay in delivery and the lack of satisfaction or explanation of the store',
'i didn t receive the product',
'i m waiting until today the product has already completed 30 days of purchase',
'they don t deliver bad store i do not recommend i want my money back',
'i have not received the product yet please help',
'they exchanged my product they sent me someone else s product',
'i do not recommend buying from this site',
'the product arrived at me diverging from what was reported on the website about how it works missing speed reducer button',
'i want the value back',
'product if you want it left to be delivered i had to buy it elsewhere',
'i have not received this product and no estimated arrival date',
'it seemed to be good at first but the delivery period has already expired and i have no information about the product',
'i am still waiting for the delivery of the product i ordered and it has already exceeded the expected delivery date i am very dissatisfied',
'i wait to receive the product',
'i didn t receive the product',
'seller still not send my order']
Key Observations:
Based on review messages, some orders were not delivered, but this is less frequent than with missing payment approval or carrier handover timestamps.
Many messages confirm order receipt. Thus, these orders cannot be assumed canceled.
del tmp_miss
Anomalies in Order Status#
We have many orders with statuses other than “delivered.” This is unusual. Let’s investigate this.
Let’s examine by status.
df_orders.order_status.value_counts()
order_status
Delivered 96478
Shipped 1107
Canceled 625
Unavailable 609
Invoiced 314
Processing 301
Created 5
Approved 2
Name: count, dtype: int64
Let’s look at missing values in the timestamps by order status.
columns = [
"order_status",
"order_purchase_dt",
"order_approved_dt",
"order_delivered_carrier_dt",
"order_delivered_customer_dt",
"order_estimated_delivery_dt",
]
(
df_orders[columns].pivot_table(
index='order_status',
aggfunc=lambda x: x.isna().sum(),
observed=True,
)
.reset_index()
[columns]
)
| order_status | order_purchase_dt | order_approved_dt | order_delivered_carrier_dt | order_delivered_customer_dt | order_estimated_delivery_dt | |
|---|---|---|---|---|---|---|
| 0 | Approved | 0 | 0 | 2 | 2 | 0 |
| 1 | Canceled | 0 | 141 | 550 | 619 | 0 |
| 2 | Created | 0 | 5 | 5 | 5 | 0 |
| 3 | Delivered | 0 | 14 | 2 | 8 | 0 |
| 4 | Invoiced | 0 | 0 | 314 | 314 | 0 |
| 5 | Processing | 0 | 0 | 301 | 301 | 0 |
| 6 | Shipped | 0 | 0 | 0 | 1107 | 0 |
| 7 | Unavailable | 0 | 0 | 609 | 609 | 0 |
Let’s look at the number of orders without the delivered status over time.
labels = dict(
order_purchase_dt = 'Date',
order_id = 'Number of Orders',
order_status = 'Order Status',
)
df_orders[lambda x: x.order_status != 'Delivered'].viz.line(
x='order_purchase_dt',
y='order_id',
color='order_status',
agg_func='nunique',
freq='ME',
labels=labels,
markers=True,
title='Number of Orders without Delivered Status by Month and Order Status',
)
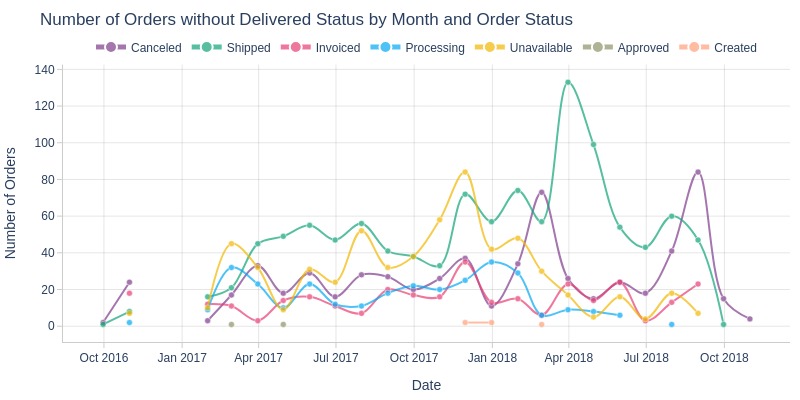
Key Observations:
In March and April 2018, there was a sharp spike in orders stuck in the “shipped” status.
In February and August 2018, there were spikes in the “canceled” status.
In November 2017, there was a spike in the “unavailable” status. This month included Black Friday.
Let’s examine each status separately.
created
Let’s look at the rows in the dataframe with orders that have the status ‘created’.
df_orders[lambda x: x.order_status == 'Created']
| order_id | customer_id | order_status | order_purchase_dt | order_approved_dt | order_delivered_carrier_dt | order_delivered_customer_dt | order_estimated_delivery_dt | tmp_avg_reviews_score | tmp_payment_types | tmp_product_categories | tmp_customer_state | tmp_order_purchase_month | tmp_order_purchase_weekday | tmp_purchase_time_of_day | tmp_is_delayed | tmp_is_delivered | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 7434 | b5359909123fa03c50bdb0cfed07f098 | 438449d4af8980d107bf04571413a8e7 | Created | 2017-12-05 01:07:52 | NaT | NaT | NaT | 2018-01-11 | 1 | Credit Card | Missing in Items | SP | December | Tuesday | Night | Missing delivery dt | Not Delivered |
| 9238 | dba5062fbda3af4fb6c33b1e040ca38f | 964a6df3d9bdf60fe3e7b8bb69ed893a | Created | 2018-02-09 17:21:04 | NaT | NaT | NaT | 2018-03-07 | 1 | Boleto | Missing in Items | DF | February | Friday | Evening | Missing delivery dt | Not Delivered |
| 21441 | 7a4df5d8cff4090e541401a20a22bb80 | 725e9c75605414b21fd8c8d5a1c2f1d6 | Created | 2017-11-25 11:10:33 | NaT | NaT | NaT | 2017-12-12 | 1 | Boleto | Missing in Items | RJ | November | Saturday | Morning | Missing delivery dt | Not Delivered |
| 55086 | 35de4050331c6c644cddc86f4f2d0d64 | 4ee64f4bfc542546f422da0aeb462853 | Created | 2017-12-05 01:07:58 | NaT | NaT | NaT | 2018-01-08 | 1 | Credit Card | Missing in Items | RS | December | Tuesday | Night | Missing delivery dt | Not Delivered |
| 58958 | 90ab3e7d52544ec7bc3363c82689965f | 7d61b9f4f216052ba664f22e9c504ef1 | Created | 2017-11-06 13:12:34 | NaT | NaT | NaT | 2017-12-01 | 5 | Credit Card | Missing in Items | PR | November | Monday | Afternoon | Missing delivery dt | Not Delivered |
Key Observations:
One order has a rating of 5, while four orders have a rating of 1.
The process stops after purchase, before payment approval.
Let’s look at the review messages.
messages = (
df_orders[lambda x: x.order_status == 'Created']
.merge(df_reviews, on='order_id', how='left')
['review_comment_message']
.tolist()
)
display(messages)
['the product has not arrived until today',
'i have not received my product i am not satisfied i am waiting to this day',
nan,
'i have been awaiting the product since december and i have not received it deceptualized with the americana because besides the delay i gave a waterway that does not fulfill the advertising delay my order',
'although the product was out of stock the company made contact to notify and canceled the order']
Key Observations:
Based on review comments, these orders were not delivered.
approved
Let’s look at the rows.
df_orders[lambda x: x.order_status == 'Approved']
| order_id | customer_id | order_status | order_purchase_dt | order_approved_dt | order_delivered_carrier_dt | order_delivered_customer_dt | order_estimated_delivery_dt | tmp_avg_reviews_score | tmp_payment_types | tmp_product_categories | tmp_customer_state | tmp_order_purchase_month | tmp_order_purchase_weekday | tmp_purchase_time_of_day | tmp_is_delayed | tmp_is_delivered | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 44897 | a2e4c44360b4a57bdff22f3a4630c173 | 8886130db0ea6e9e70ba0b03d7c0d286 | Approved | 2017-02-06 20:18:17 | 2017-02-06 20:30:19 | NaT | NaT | 2017-03-01 | 1 | Credit Card | informatica_acessorios | MG | February | Monday | Evening | Missing delivery dt | Not Delivered |
| 88457 | 132f1e724165a07f6362532bfb97486e | b2191912d8ad6eac2e4dc3b6e1459515 | Approved | 2017-04-25 01:25:34 | 2017-04-30 20:32:41 | NaT | NaT | 2017-05-22 | 4 | Credit Card | utilidades_domesticas | SP | April | Tuesday | Night | Missing delivery dt | Not Delivered |
Key Observations:
One order received a rating of 1, the other a 4.
The process stops after payment approval, before carrier handover.
Let’s look at the review messages.
messages = (
df_orders[lambda x: x.order_status == 'Approved']
.merge(df_reviews, on='order_id', how='left')
['review_comment_message']
.tolist()
)
display(messages)
[nan, nan]
Key Observations:
No comments were left for these orders.
processing
Let’s look at orders with the status ‘processing’ by month.
df_orders['order_status'].explore.anomalies_over_time(
time_column='order_purchase_dt'
, custom_mask=df_orders.order_status == 'Processing'
, freq='ME'
)
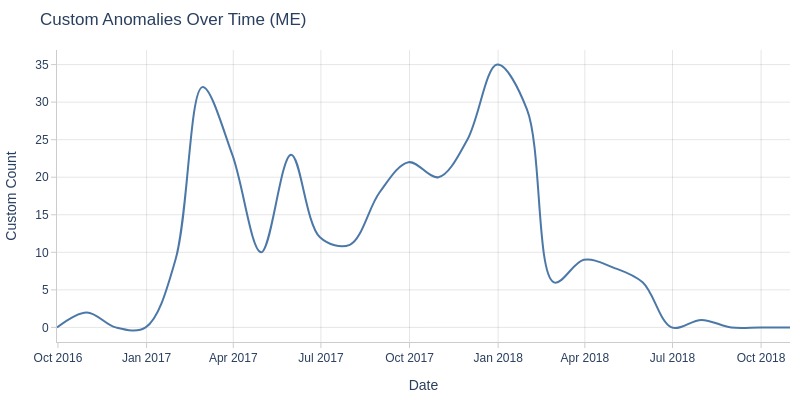
Let’s look at the count of each order status.
tmp_anomal = df_orders[lambda x: x.order_status == 'Processing']
(
tmp_anomal[['order_purchase_dt', 'order_approved_dt', 'order_delivered_carrier_dt', 'order_delivered_customer_dt', 'order_estimated_delivery_dt']]
.count()
.to_frame('count')
)
| count | |
|---|---|
| order_purchase_dt | 301 |
| order_approved_dt | 301 |
| order_delivered_carrier_dt | 0 |
| order_delivered_customer_dt | 0 |
| order_estimated_delivery_dt | 301 |
Key Observations:
The process stops after payment approval, before carrier handover.
Let’s look at it broken down by the average order rating.
df_orders['order_status'].explore.anomalies_by_categories(
custom_mask=df_orders.order_status == 'Processing'
, include_columns='tmp_avg_reviews_score'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| tmp_avg_reviews_score | 1 | 11756 | 260 | 2.2% | 11.8% | 86.4% | 74.6% |
| tmp_avg_reviews_score | 2 | 3244 | 19 | 0.6% | 3.3% | 6.3% | 3.1% |
| tmp_avg_reviews_score | 3 | 8268 | 10 | 0.1% | 8.3% | 3.3% | -5.0% |
| tmp_avg_reviews_score | 4 | 19129 | 6 | 0.0% | 19.2% | 2.0% | -17.2% |
| tmp_avg_reviews_score | 5 | 57044 | 6 | 0.0% | 57.4% | 2.0% | -55.4% |
Key Observations:
86% of orders with “processing” status have a rating of 1.
6% of orders have a rating of 2.
Customers are clearly dissatisfied.
Let’s look at it broken down by payment type.
df_orders['order_status'].explore.anomalies_by_categories(
custom_mask=df_orders.order_status == 'Processing'
, include_columns='tmp_payment_types'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| tmp_payment_types | Boleto | 19784 | 70 | 0.4% | 19.9% | 23.3% | 3.4% |
| tmp_payment_types | Voucher | 1621 | 7 | 0.4% | 1.6% | 2.3% | 0.7% |
| tmp_payment_types | Credit Card, Voucher | 1127 | 3 | 0.3% | 1.1% | 1.0% | -0.1% |
| tmp_payment_types | Voucher, Credit Card | 1118 | 1 | 0.1% | 1.1% | 0.3% | -0.8% |
| tmp_payment_types | Debit Card | 1527 | 2 | 0.1% | 1.5% | 0.7% | -0.9% |
| tmp_payment_types | Credit Card | 74259 | 218 | 0.3% | 74.7% | 72.4% | -2.3% |
Key Observations:
The “boleto” payment type has a slightly higher proportion difference.
Let’s randomly sample 20 review comments.
We’ll repeat this several times.
tmp_anomal = tmp_anomal.merge(df_reviews, on='order_id', how='left')
messages = (
tmp_anomal['review_comment_message']
.dropna()
.sample(20)
.tolist()
)
display(messages)
['i made a purchase my orders came separate so far so good but a product was missing and it has not yet been delivered and that s what i paid dearly for shipping the deadline was the 6th it s already the 8th and i m not even satisfied',
'the deadline has passed and the product has not arrived yet what happened',
'i m still waiting for my product it hasn t arrived yet',
'i always bought on this site and everything arrived correctly only in this last purchase that i had problems with the delivery of one of the products which did not arrive',
'the seller contacted me but did not complete the sale',
'i did not receive the product i wanted i am waiting for the refund the service was so bad they didn t even issue a note',
'i no longer buy from this baratheon partner for 30 days since i bought it and the invoice has not yet been issued',
'i have not received the product purchased since 12/26/17 i had no response from the store giving satisfaction about the purchase i request a refund for the purchase',
'terrible because i ordered a product i already paid it said it would arrive by 24 11 2017 and the product did not arrive on top of that it said that it was unavailable',
'i am disappointed with the late delivery',
'my product is overdue it was supposed to be delivered on 03/10',
'they did not send the product and did not give satisfaction',
'i bought it for the first time for never again deceptionedx',
'i did not receive the product they were delivering me to di 15 11 2017 and then it was for the day 25 11 2017 and nothing i am disappointed with the seller and lannister because they took the order i can not life',
'i just didn t receive the product',
'i already made purchases through baratheon and everything went well only this request presented problems and if i didn t go after it i would never know about the situation the invoice has already been paid i have not received the product and not even a satisfaction',
'i m waiting for the product to arrive',
'absurd to buy a product and it is not available',
'did not deliver',
'i buy it all the time never had a problem the shirts purchased received and returned were three dobby i am currently choosing others to use the vale']
Key Observations:
Based on review messages, orders were not delivered.
Some reviews mention items being out of stock.
Let’s examine a word cloud from review messages.
tmp_anomal.viz.wordcloud('review_comment_message')
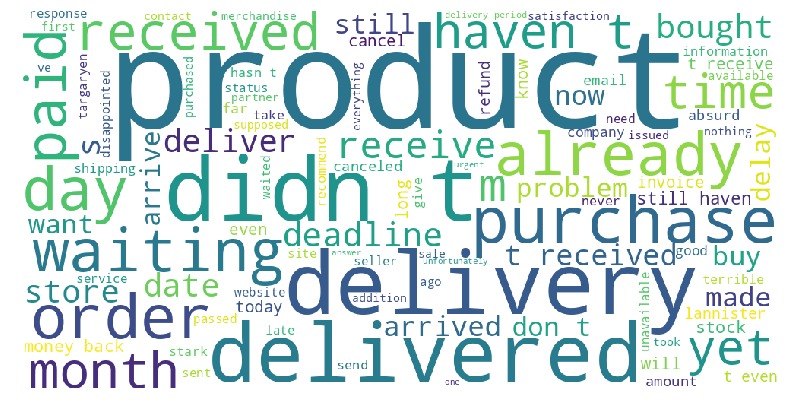
Key Observations:
Most words relate to delivery.
Let’s analyze the sentiment of the text.
tmp_anomal.analysis.sentiment('review_comment_message')
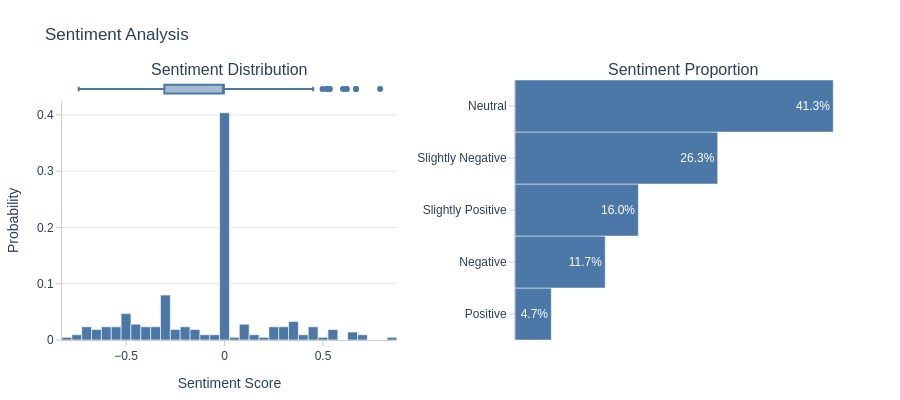
Key Observations:
Negative reviews significantly outnumber positive ones, and the boxplot lies in the negative zone.
invoiced
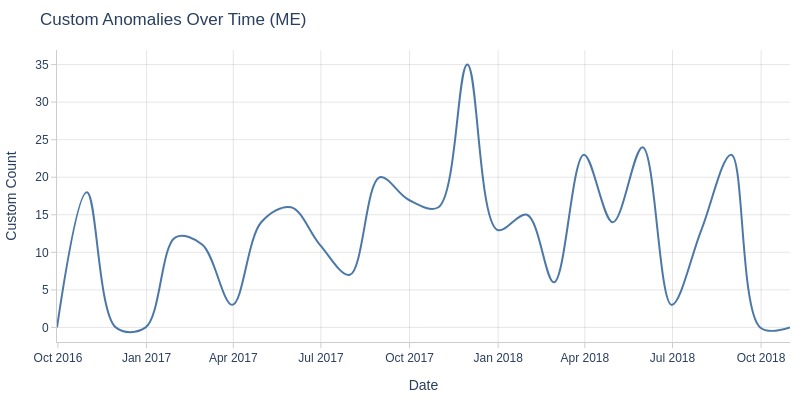
Let’s look at orders with the status ‘invoiced’ by month.
df_orders['order_status'].explore.anomalies_over_time(
time_column='order_purchase_dt'
, custom_mask=df_orders.order_status == 'Invoiced'
, freq='ME'
)
Let’s look at the count of each order status.
tmp_anomal = df_orders[lambda x: x.order_status == 'Invoiced']
(
tmp_anomal[['order_purchase_dt', 'order_approved_dt', 'order_delivered_carrier_dt', 'order_delivered_customer_dt', 'order_estimated_delivery_dt']]
.count()
.to_frame('count')
)
| count | |
|---|---|
| order_purchase_dt | 314 |
| order_approved_dt | 314 |
| order_delivered_carrier_dt | 0 |
| order_delivered_customer_dt | 0 |
| order_estimated_delivery_dt | 314 |
Key Observations:
The process stops after payment approval, before carrier handover.
Let’s look at it broken down by the average order rating.
df_orders['order_status'].explore.anomalies_by_categories(
custom_mask=df_orders.order_status == 'Invoiced'
, include_columns='tmp_avg_reviews_score'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| tmp_avg_reviews_score | 1 | 11756 | 232 | 2.0% | 11.8% | 73.9% | 62.1% |
| tmp_avg_reviews_score | 2 | 3244 | 28 | 0.9% | 3.3% | 8.9% | 5.7% |
| tmp_avg_reviews_score | 3 | 8268 | 17 | 0.2% | 8.3% | 5.4% | -2.9% |
| tmp_avg_reviews_score | 4 | 19129 | 13 | 0.1% | 19.2% | 4.1% | -15.1% |
| tmp_avg_reviews_score | 5 | 57044 | 24 | 0.0% | 57.4% | 7.6% | -49.7% |
Key Observations:
74% of orders with “invoiced” status have a rating of 1.
9% of orders have a rating of 2.
Customers are clearly dissatisfied.
Let’s randomly sample 20 review comments.
We’ll repeat this several times.
tmp_anomal = tmp_anomal.merge(df_reviews, on='order_id', how='left')
messages = (
tmp_anomal['review_comment_message']
.dropna()
.sample(20)
.tolist()
)
display(messages)
['my product did not arrive delivery time of 34 days and still not delivered i do not recommend',
'i bought it to give to my daughter for christmas i hope it arrives on time',
'good morning i purchased more than 30 days ago and i did not receive the product i requested a cancellation but i did not receive a response',
'a simple computer mouse shouldn t take so long to deliver',
'they gave me a huge deadline to send the product and on the last day they sent me an email saying they don t have the product now i have the bureaucracy to get my money back',
'i like shopping in this store',
'takes too long to deliver i hope the product still comes',
'terrible company did not deliver the product and does not respond to my cancellation requests i already paid the first installment and had no response',
'after a long time only today i received a message with the following information: good afternoon walter thanks for getting in touch we are sorry for the delay in getting back to you your order was not',
'unfortunately it happened in no other purchase of several that i have already made on lannister com i did not receive the product but this time i did not receive it a pity',
'it was the first and last time i buy from this company never',
'no information total sloppiness',
'expensive i requested the cancellation of this order on the same day that the invoice was issued i called the supplier informed in the nf and canceled the shipment of the goods i am waiting for an american refund form',
'i don t recommend this store because they sold me a backpack that they didn t have in stock',
'the product has not yet arrived it has passed and much of the deadline and no one gives me a return',
'i bought two white stools on the website to be delivered by 03/13 and so far i haven t received my house well i m waiting for action or i m going to look for my consumer rights',
'absurd they said that until the 10/04th serious delivery but so far nothing and it s been paid for my orders for a while',
'i have already bought several times on the lannister site;but this last time i made a purchase of a toner at 04 10 16 and only promised for 25 11 16 and still not i received the product',
'very disappointed with lannister s targaryen partner purchased product paid and not delivered a lot of disappointment please speed up delivery or want my money back',
'the product order was placed on 07/11 with delivery forecast for the 21st the invoice was only issued on the 22nd; it s already the 24th and the product hasn t even left for delivery']
Key Observations:
Review messages indicate orders were not delivered.
Some reviews mention items being out of stock.
Let’s examine a word cloud from review messages.
tmp_anomal.viz.wordcloud('review_comment_message')
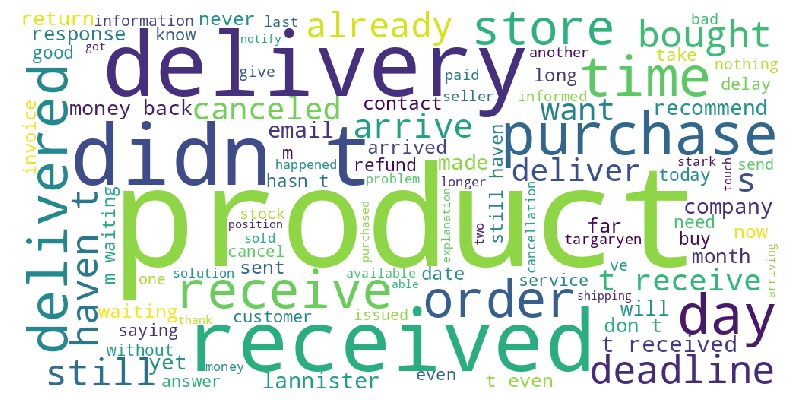
Key Observations:
Many words relate to delivery.
Let’s analyze the sentiment of the text.
tmp_anomal.analysis.sentiment('review_comment_message')
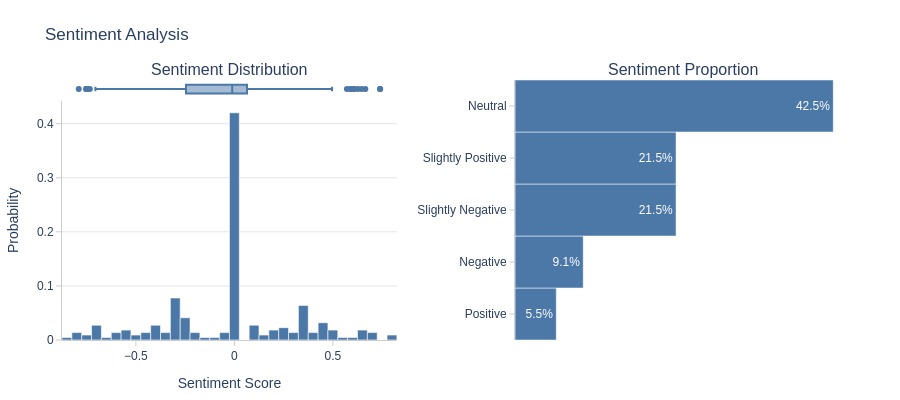
Key Observations:
Negative reviews significantly outnumber positive ones, and the boxplot mostly lies below 0.
unavailable
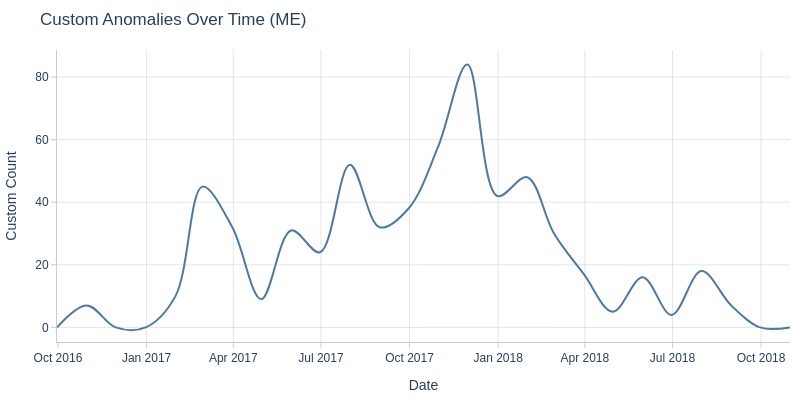
Let’s look at orders with the status ‘unavailable’ by month.
df_orders['order_status'].explore.anomalies_over_time(
time_column='order_purchase_dt'
, custom_mask=df_orders.order_status == 'Unavailable'
, freq='ME'
)
Let’s look at the count of each order status.
tmp_anomal = df_orders[lambda x: x.order_status == 'Unavailable']
(
tmp_anomal[['order_purchase_dt', 'order_approved_dt', 'order_delivered_carrier_dt', 'order_delivered_customer_dt', 'order_estimated_delivery_dt']]
.count()
.to_frame('count')
)
| count | |
|---|---|
| order_purchase_dt | 609 |
| order_approved_dt | 609 |
| order_delivered_carrier_dt | 0 |
| order_delivered_customer_dt | 0 |
| order_estimated_delivery_dt | 609 |
Key Observations:
The process stops after payment approval, before carrier handover.
Let’s look by the customer’s state.
df_orders['order_status'].explore.anomalies_by_categories(
custom_mask=df_orders.order_status == 'Unavailable'
, pct_diff_threshold=1
, include_columns='tmp_customer_state'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| tmp_customer_state | SP | 41746 | 292 | 0.7% | 42.0% | 47.9% | 6.0% |
| tmp_customer_state | PR | 5045 | 40 | 0.8% | 5.1% | 6.6% | 1.5% |
Key Observations:
The proportion of missing values in São Paulo is higher than in the full dataset.
Let’s look by product category.
df_orders['order_status'].explore.anomalies_by_categories(
custom_mask=df_orders.order_status == 'Unavailable'
, pct_diff_threshold=0
, include_columns='tmp_product_categories'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| tmp_product_categories | Missing in Items | 775 | 603 | 77.8% | 0.8% | 99.0% | 98.2% |
Key Observations:
99% of orders lack a category, meaning they are not in the items table.
Let’s look at it broken down by payment type.
df_orders['order_status'].explore.anomalies_by_categories(
custom_mask=df_orders.order_status == 'Unavailable'
, pct_diff_threshold=0
, include_columns='tmp_payment_types'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| tmp_payment_types | Boleto | 19784 | 150 | 0.8% | 19.9% | 24.6% | 4.7% |
| tmp_payment_types | Voucher, Credit Card | 1118 | 9 | 0.8% | 1.1% | 1.5% | 0.4% |
| tmp_payment_types | Credit Card, Voucher | 1127 | 8 | 0.7% | 1.1% | 1.3% | 0.2% |
| tmp_payment_types | Voucher | 1621 | 10 | 0.6% | 1.6% | 1.6% | 0.0% |
Key Observations:
The “boleto” payment type has a slightly higher proportion difference.
Let’s look at it broken down by the average order rating.
df_orders['order_status'].explore.anomalies_by_categories(
custom_mask=df_orders.order_status == 'Unavailable'
, pct_diff_threshold=0
, include_columns='tmp_avg_reviews_score'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| tmp_avg_reviews_score | 1 | 11756 | 472 | 4.0% | 11.8% | 77.5% | 65.7% |
| tmp_avg_reviews_score | 2 | 3244 | 46 | 1.4% | 3.3% | 7.6% | 4.3% |
Key Observations:
The difference in proportions is much higher for a rating of 1.
78% of orders with “unavailable” status have a rating of 1.
8% of orders have a rating of 2.
Customers are clearly dissatisfied.
Let’s randomly sample 20 review comments.
We’ll repeat this several times.
tmp_anomal = tmp_anomal.merge(df_reviews, on='order_id', how='left')
messages = (
tmp_anomal['review_comment_message']
.dropna()
.sample(20)
.tolist()
)
display(messages)
['i m waiting until today the product has already completed 30 days of purchase',
'almost a month ago the watch was ordered and paid via boleem if you want to and so far nothing i sent two emails and they didn t even give me satisfaction; oslit stores for me is out lannister without prestige',
'allowed to complete the purchase but did not have the product in stock greater fatigue to get the money back',
'total dissatisfaction with this store sells a product is not delivery tremendous lack of respect',
'i was outraged why it sold',
'i still haven t received the product the deadlines have passed and so far no response now bear the headache to resolve',
'product did not arrive within the time listed',
'in 2 months of waiting i did not receive the product i divided it into two times paid both times and did not receive the product a shame i m going to the procon because baratheon doesn t answer the phone shame',
'i m super dissatisfied i needed the material urgently and i only bought it because lannister stores never had any problems since the supplier doesn t say the same there was no commitment',
'you sold something you didn t have in stock this procedure is problematic my daughter is still waiting for the doll i bought christmas passed and nothing comes the new year tomorrow it s nothing i want the product',
'i didn t receive my product i was already charged in cartaxo',
'shame on such a partner he sold the product confirmed it deducted the amount from the card and now wants to cancel the order because he claims not to have it in stock that s a crime and the stark follows in silence',
'i would not recommend it because i made my purchase made the payment and after a few days i received an email that the partners would not deliver in my region',
'i didn t receive the product',
'i bought a skate through the store and the delivery was scheduled for 05/01/18 until the present date i have not received it',
'didn t give me any satisfaction',
'the scheduled days passed',
'lack of respect for the consumer after everything is finalized they make excuses not to deliver never again the lannister website cannot have a link with this type of seller',
'i am filing a complaint with the procon i can t talk to anyone in this loha',
'deadline for delivery 22/12 two days before the store warned that it does not have the product and does not even know when it will be available so i had to go looking for the skate to deliver for christmas to my grandson i want a refund']
Key Observations:
Review messages indicate orders were not delivered.
Some reviews mention items being out of stock.
Let’s examine a word cloud from review messages.
tmp_anomal.viz.wordcloud('review_comment_message')
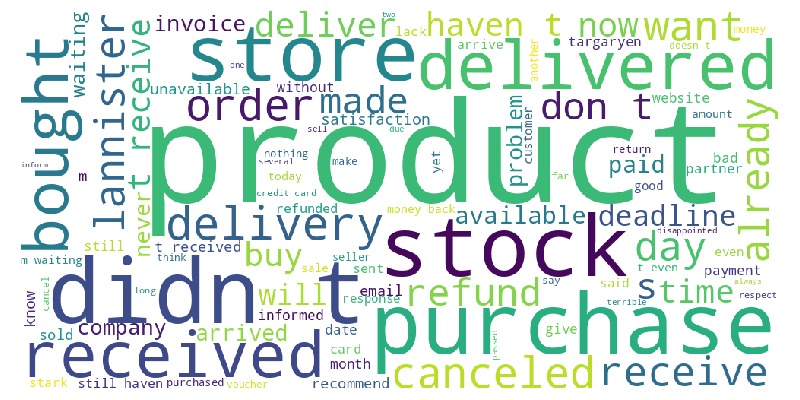
Key Observations:
Many words relate to delivery.
Let’s analyze the sentiment of the text.
tmp_anomal.analysis.sentiment('review_comment_message')
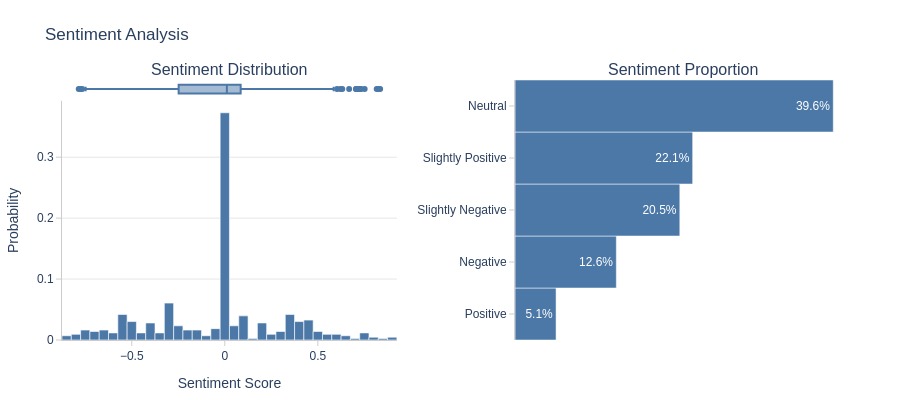
Key Observations:
Negative reviews outnumber positive ones, and the boxplot mostly lies below 0.
canceled
Let’s look at orders with the status ‘canceled’ by month.
df_orders['order_status'].explore.anomalies_over_time(
time_column='order_purchase_dt'
, custom_mask=df_orders.order_status == 'Canceled'
, freq='ME'
)
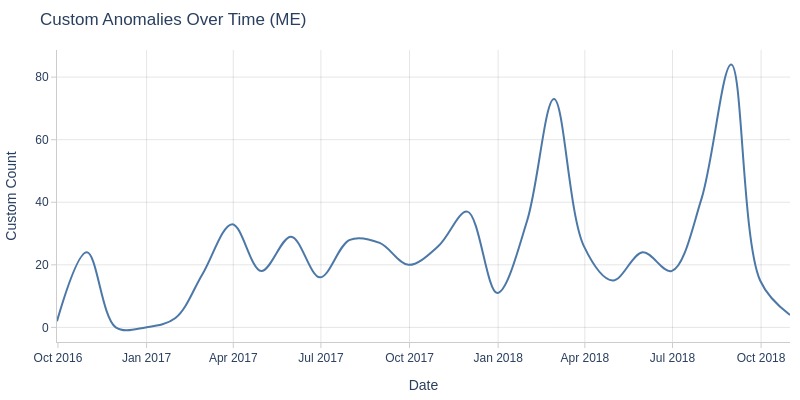
Order cancellation can occur at different stages, so there may be missing values at various points.
Let’s look at the missing values.
tmp_anomal = df_orders[lambda x: x.order_status == 'Canceled']
tmp_anomal.explore.detect_anomalies()
| Count | Percent | |
|---|---|---|
| order_approved_dt | 141 | 22.56% |
| order_delivered_carrier_dt | 550 | 88.00% |
| order_delivered_customer_dt | 619 | 99.04% |
Conversion at different stages
Let’s look at the count of different order status timestamps.
Let’s check if there are any missing values between the dates.
mask = tmp_anomal['order_delivered_carrier_dt'].isna() & tmp_anomal['order_delivered_customer_dt'].notna()
tmp_anomal.loc[mask, 'order_delivered_carrier_dt']
SeriesOn([], Name: order_delivered_carrier_dt, dtype: datetime64[ns])
mask = tmp_anomal['order_approved_dt'].isna() & tmp_anomal['order_delivered_carrier_dt'].notna()
tmp_anomal.loc[mask, 'order_approved_dt']
SeriesOn([], Name: order_approved_dt, dtype: datetime64[ns])
All good.
tmp_funnel = (
tmp_anomal[['order_purchase_dt', 'order_approved_dt', 'order_delivered_carrier_dt', 'order_delivered_customer_dt']]
.count()
.to_frame('count')
.assign(share = lambda x: (x['count']*100 / x['count']['order_purchase_dt']).round(1).astype(str) + '%')
.reset_index(names='stage')
)
px.funnel(
tmp_funnel,
x='count',
y='stage',
text='share',
width=600,
title='Conversion of Different Order Stages with "Canceled" Status'
)
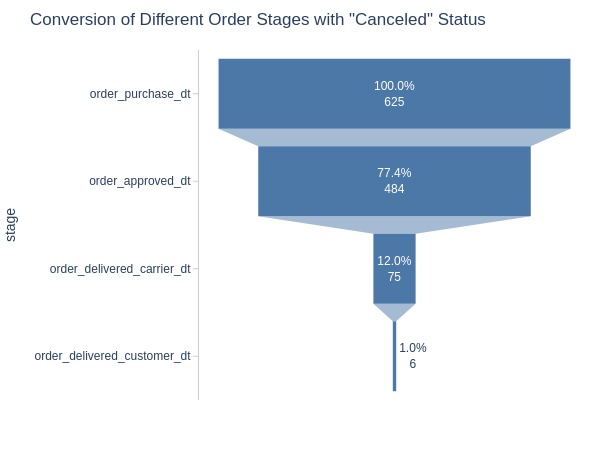
Key Observations:
The process stops at different stages, most often between payment approval and carrier handover.
Let’s look at the conversion at each stage by month.
For this, we will count the number of canceled orders with specific timestamps in each period and divide by the number of canceled orders at the time of purchase.
tmp_res_df = (
tmp_anomal.resample('ME', on='order_purchase_dt')
.agg(
purchase = ('order_id', 'count')
, approved = ('order_approved_dt', 'count')
, delivered_carrier = ('order_delivered_carrier_dt', 'count')
, delivered_customer = ('order_delivered_customer_dt', 'count')
)
)
tmp_res_df = tmp_res_df.div(tmp_res_df['purchase'], axis=0)
tmp_res_df = (
tmp_res_df.reset_index(names='date')
.melt(id_vars='date', var_name='date_type', value_name='count')
)
Let’s look at the non-normalized values. That is, divide each value (count with a specific timestamp) by the total value for the period.
labels = dict(
date = 'Date',
date_type = 'Date Type',
count = 'Conversion'
)
tmp_res_df.viz.line(
x='date'
, y='count'
, color='date_type'
, labels=labels
, title='Conversion of Different Order Stages with "Canceled" Status by Month'
)
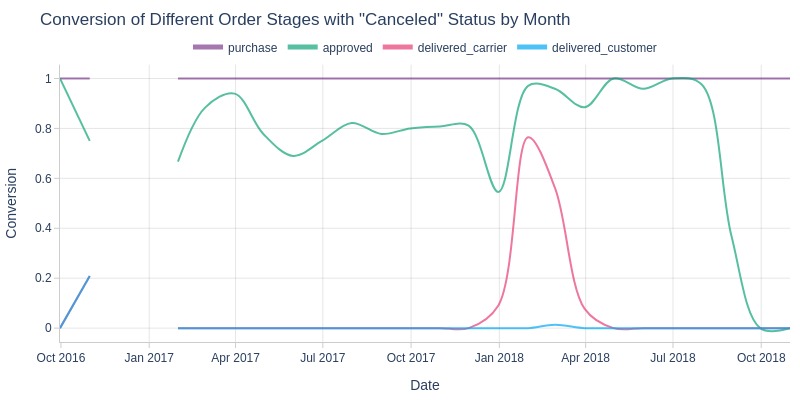
Key Observations:
Canceled orders almost never have delivery timestamps, which is logical.
From December 2017 to March 2018, there was a significant spike in canceled orders that had carrier handover timestamps but no delivery timestamps, indicating delivery issues during this period.
About 80% of canceled orders have payment approval timestamps, but this proportion increased significantly starting January 2018, approaching 100%.
Number of Last Stages
Let’s look at the last stage to which orders with the status ‘canceled’ reach over time.
For this:
transform the wide table into a long one, making the name of the time variable a category;
remove missing values in the time (this will be the variable with the value after melt);
convert these categories into a categorical type in pandas and specify the order;
group by order;
take the first time in each group (all entries in the group will have the same time);
take the maximum stage (since we specified the order, this will be the last stage of the order).
tmp_df_orders_canceled = df_orders[lambda x: x.order_status == 'Canceled']
tmp_df_orders_canceled['tmp_date'] = tmp_df_orders_canceled['order_purchase_dt']
tmp_df_orders_canceled = (
tmp_df_orders_canceled.rename(
columns={
'order_purchase_dt': 'purchase'
, 'order_approved_dt': 'approved'
, 'order_delivered_carrier_dt': 'delivered_carrier'
, 'order_delivered_customer_dt': 'delivered_customer'
}
)
.melt(
id_vars=['tmp_date', 'order_id']
, value_vars=['purchase', 'approved', 'delivered_carrier', 'delivered_customer']
, var_name='date_stage'
)
.dropna(subset='value')
.drop('value', axis=1)
)
date_stage_order = ['purchase', 'approved', 'delivered_carrier', 'delivered_customer']
tmp_df_orders_canceled['date_stage'] = (
tmp_df_orders_canceled['date_stage']
.astype('category')
.cat.reorder_categories(date_stage_order, ordered=True)
)
tmp_df_orders_canceled = (
tmp_df_orders_canceled.groupby('order_id', as_index=False)
.agg(
tmp_date = ('tmp_date', 'first')
, last_date_stage = ('date_stage', 'max')
)
)
Let’s look at it over time.
labels = dict(
date = 'Date',
order_id = 'Number of Orders',
last_date_stage = 'Last Stage'
)
tmp_df_orders_canceled.viz.line(
x='tmp_date'
, y='order_id'
, color='last_date_stage'
, agg_func='nunique'
, freq='ME'
, labels=labels
, markers=True
, title='Number of Orders by Month and Last Stage'
)
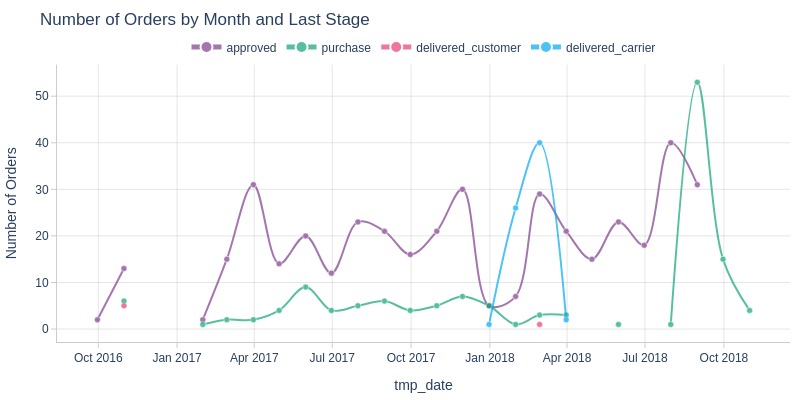
Key Observations:
In most months, the process stops after payment approval.
From December 2017 to March 2018, there was a spike in orders that stopped after carrier handover.
In August 2018, there was a sharp peak in orders that stopped immediately after purchase.
Let’s look by the customer’s state.
tmp_anomal = df_orders[lambda x: x.order_status == 'Canceled']
df_orders['order_status'].explore.anomalies_by_categories(
custom_mask=df_orders.order_status == 'Canceled'
, pct_diff_threshold=0
, include_columns='tmp_customer_state'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| tmp_customer_state | SP | 41746 | 327 | 0.8% | 42.0% | 52.3% | 10.3% |
| tmp_customer_state | RJ | 12852 | 86 | 0.7% | 12.9% | 13.8% | 0.8% |
| tmp_customer_state | RO | 253 | 3 | 1.2% | 0.3% | 0.5% | 0.2% |
| tmp_customer_state | PI | 495 | 4 | 0.8% | 0.5% | 0.6% | 0.1% |
| tmp_customer_state | RR | 46 | 1 | 2.2% | 0.0% | 0.2% | 0.1% |
| tmp_customer_state | GO | 2020 | 13 | 0.6% | 2.0% | 2.1% | 0.0% |
Key Observations:
The proportion of missing values in São Paulo is significantly higher than in the full dataset.
Let’s look by product category.
df_orders['order_status'].explore.anomalies_by_categories(
custom_mask=df_orders.order_status == 'Canceled'
, pct_diff_threshold=1
, include_columns='tmp_product_categories'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| tmp_product_categories | Missing in Items | 775 | 164 | 21.2% | 0.8% | 26.2% | 25.5% |
| tmp_product_categories | brinquedos | 3835 | 31 | 0.8% | 3.9% | 5.0% | 1.1% |
Key Observations:
Missing product categories have a much higher proportion difference, possibly due to items being out of stock.
Let’s look at it broken down by payment type.
df_orders['order_status'].explore.anomalies_by_categories(
custom_mask=df_orders.order_status == 'Canceled'
, pct_diff_threshold=0
, include_columns='tmp_payment_types'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| tmp_payment_types | Voucher | 1621 | 76 | 4.7% | 1.6% | 12.2% | 10.5% |
| tmp_payment_types | Voucher, Credit Card | 1118 | 12 | 1.1% | 1.1% | 1.9% | 0.8% |
| tmp_payment_types | Not Defined | 3 | 3 | 100.0% | 0.0% | 0.5% | 0.5% |
Key Observations:
The “voucher” payment type has a noticeably higher proportion difference.
Let’s look at it broken down by the average order rating.
df_orders['order_status'].explore.anomalies_by_categories(
custom_mask=df_orders.order_status == 'Canceled'
, pct_diff_threshold=0
, include_columns='tmp_avg_reviews_score'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| tmp_avg_reviews_score | 1 | 11756 | 434 | 3.7% | 11.8% | 69.4% | 57.6% |
| tmp_avg_reviews_score | 2 | 3244 | 45 | 1.4% | 3.3% | 7.2% | 3.9% |
Key Observations:
69% of orders with “canceled” status have a rating of 1.
7% of orders have a rating of 2.
Customers are clearly dissatisfied.
Let’s randomly sample 20 review comments.
We’ll repeat this several times.
tmp_anomal = tmp_anomal.merge(df_reviews, on='order_id', how='left')
messages = (
tmp_anomal['review_comment_message']
.dropna()
.sample(20)
.tolist()
)
display(messages)
['the delivery date has passed and the product has not arrived',
'i haven t received anything so far',
'i didn t send my order',
'i received the product it s of great quality only the padlock that came with the product that came with a defect',
'i did not receive the product or contact the supplier i already sent an email via the lannister website and nothing happened i m waiting for a return because i don t want to give up the purchase i want the product',
'my order was canceled without my request on the 20/11th and so far they have not refunded my money it was a gift there was a lot of lack of professionalism',
'not received',
'i no longer recommend this store i lost credibility with you',
'until now i have not received the product',
'easy to assemble',
'they gave me a period of 26 days for delivery and with 4 remaining they inform me that it would not be possible to deliver my product simply ridiculous',
'good morning my products arrived but the iron was missing and i have urgently to receive it protocol 2517102738811 thanks',
'i bought a 110v grinder and they sent me a 220v i haven t had a response so far',
'good quality product',
'i always buy from lannister stores and i ve never had any problems i think it s safe',
'there was a problem with the delivery the post office did not deliver it to the person at the agency even with the tracking code and document they informed that the product was not in the unit',
'i canceled the order 02 672741651 but is being charged',
'fake and with scratches on the screen',
'i still haven t received the product can i cancel the parcel of the order and try to buy another one',
'i received the product full of defects i already requested a refund i m waiting for a refund']
Key Observations:
Review messages indicate orders were not delivered.
Some reviews mention items being out of stock.
Let’s examine a word cloud from review messages.
tmp_anomal.viz.wordcloud('review_comment_message')

Key Observations:
Many words relate to delivery.
Let’s analyze the sentiment of the text.
tmp_anomal.analysis.sentiment('review_comment_message')
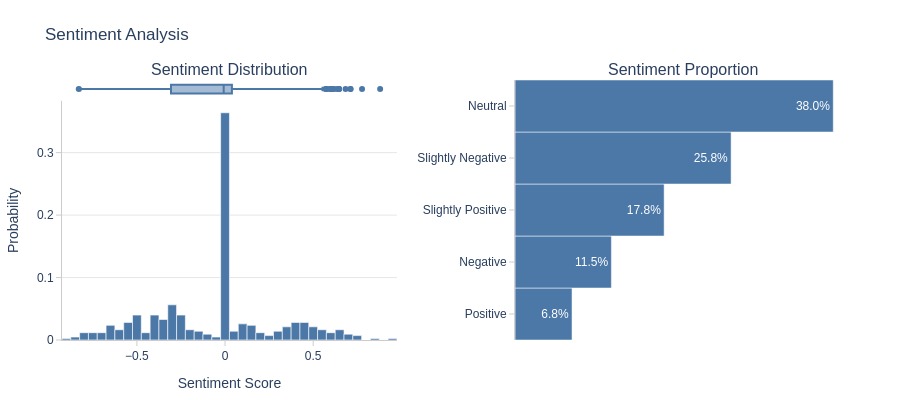
Key Observations:
Negative messages significantly outnumber positive ones, and the boxplot lies below 0.
shipped
Let’s look at the number of orders with the status ‘delivered’ by month.
df_orders['order_status'].explore.anomalies_over_time(
time_column='order_purchase_dt'
, custom_mask=df_orders.order_status == 'Shipped'
, freq='ME'
)
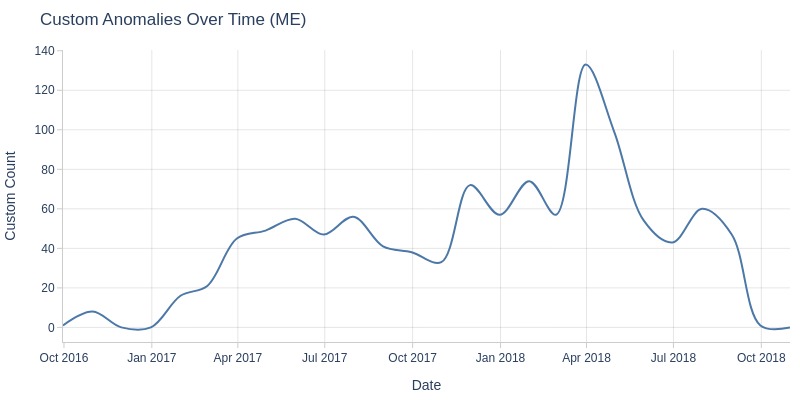
Let’s look at the count of each order status.
tmp_anomal = df_orders[lambda x: x.order_status == 'Shipped']
(
tmp_anomal[['order_purchase_dt', 'order_approved_dt', 'order_delivered_carrier_dt', 'order_delivered_customer_dt', 'order_estimated_delivery_dt']]
.count()
.to_frame('count')
)
| count | |
|---|---|
| order_purchase_dt | 1107 |
| order_approved_dt | 1107 |
| order_delivered_carrier_dt | 1107 |
| order_delivered_customer_dt | 0 |
| order_estimated_delivery_dt | 1107 |
Key Observations:
The process stops after carrier handover, before customer delivery.
Let’s look by the customer’s state.
df_orders['order_status'].explore.anomalies_by_categories(
custom_mask=df_orders.order_status == 'Shipped'
, pct_diff_threshold=1
, include_columns='tmp_customer_state'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| tmp_customer_state | RJ | 12852 | 289 | 2.2% | 12.9% | 26.1% | 13.2% |
| tmp_customer_state | BA | 3380 | 68 | 2.0% | 3.4% | 6.1% | 2.7% |
| tmp_customer_state | CE | 1336 | 38 | 2.8% | 1.3% | 3.4% | 2.1% |
| tmp_customer_state | PE | 1652 | 35 | 2.1% | 1.7% | 3.2% | 1.5% |
Key Observations:
The proportion of missing values in Rio de Janeiro is significantly higher than in the full dataset.
Let’s look at it broken down by the average order rating.
df_orders['order_status'].explore.anomalies_by_categories(
custom_mask=df_orders.order_status == 'Shipped'
, pct_diff_threshold=1
, include_columns='tmp_avg_reviews_score'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| tmp_avg_reviews_score | 1 | 11756 | 686 | 5.8% | 11.8% | 62.0% | 50.1% |
| tmp_avg_reviews_score | 2 | 3244 | 85 | 2.6% | 3.3% | 7.7% | 4.4% |
| tmp_avg_reviews_score | 3 | 8268 | 123 | 1.5% | 8.3% | 11.1% | 2.8% |
Key Observations:
62% of orders with “shipped” status have a rating of 1.
8% of orders have a rating of 2.
Customers are clearly dissatisfied.
Let’s randomly sample 20 review comments.
We’ll repeat this several times.
tmp_anomal = tmp_anomal.merge(df_reviews, on='order_id', how='left')
messages = (
tmp_anomal['review_comment_message']
.dropna()
.sample(20)
.tolist()
)
display(messages)
['does not deliver order on time',
'1 month delay in delivery last purchase i make',
'did not arrive',
'i always bought it at lannister but this time their partner did not deliver the product he said it was a risk area he left it in the mail when the notice arrived on friday afternoon there was no time to pick it up',
'my product was not delivered how am i going to do it now',
'the product has not been delivered yet',
'not received',
'the product has not arrived',
'i don t know if i recommend it the product was marked on the website for a type of cell phone but when it arrived it did not fit the cell phone',
'i didn t like it i made the purchase paid for shipping and the product is at the post office far from my residence i want my reversal',
'i canceled that order but i received the tv panel i loved it',
'i bought the product but heard a return because it was not what i wanted i asked to cancel the purchase',
'i have not received the product so far and no contact advising the reason',
'the product was stolen in possession of the post office but i don t blame the store',
'merchandise burned at the distribution center in fortaleza ce i canceled the purchase to refund the amount paid',
'i am dissatisfied with the lack of attention to the customer it was asked at the beginning to cancel the order in which i was not answered i don t intend to buy more anytime soon around here',
'awaiting solution',
'i receive deliveries at my house and at my service but i could not receive this one targaryen',
'i would like to know how to proceed to receive the product because i still want it',
'it is very good to buy in this store except that the post office did not send a notice for the object to be removed']
Key Observations:
Review messages indicate most orders were not delivered.
Let’s examine a word cloud from review messages.
tmp_anomal.viz.wordcloud('review_comment_message')
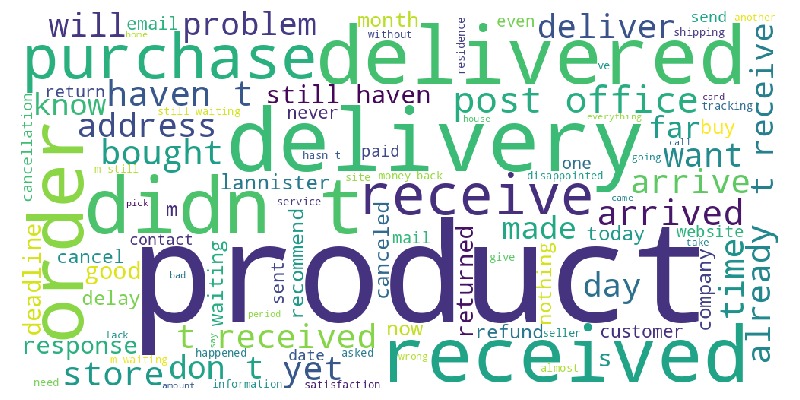
Key Observations:
Many words relate to delivery.
Let’s analyze the sentiment of the text.
tmp_anomal.analysis.sentiment('review_comment_message')
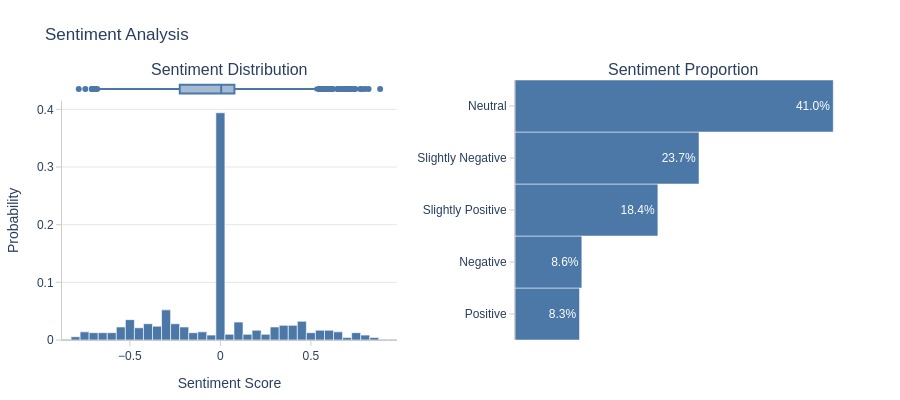
Key Observations:
Negative messages outnumber positive ones, and the boxplot mostly lies below 0.
Status and Delivery Mismatches#
Delivery status missing but delivery timestamp present
Let’s check if there are orders without “delivered” status that still have a delivery timestamp.
df_orders[lambda x: (x.order_status != 'Delivered') & ~x.order_delivered_customer_dt.isna()]
| order_id | customer_id | order_status | order_purchase_dt | order_approved_dt | order_delivered_carrier_dt | order_delivered_customer_dt | order_estimated_delivery_dt | tmp_avg_reviews_score | tmp_payment_types | tmp_product_categories | tmp_customer_state | tmp_order_purchase_month | tmp_order_purchase_weekday | tmp_purchase_time_of_day | tmp_is_delayed | tmp_is_delivered | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2921 | 1950d777989f6a877539f53795b4c3c3 | 1bccb206de9f0f25adc6871a1bcf77b2 | Canceled | 2018-02-19 19:48:52 | 2018-02-19 20:56:05 | 2018-02-20 19:57:13 | 2018-03-21 22:03:51 | 2018-03-09 | 3 | Credit Card | beleza_saude | MG | February | Monday | Evening | Delayed | Not Delivered |
| 8791 | dabf2b0e35b423f94618bf965fcb7514 | 5cdec0bb8cbdf53ffc8fdc212cd247c6 | Canceled | 2016-10-09 00:56:52 | 2016-10-09 13:36:58 | 2016-10-13 13:36:59 | 2016-10-16 14:36:59 | 2016-11-30 | 5 | Credit Card | perfumaria, beleza_saude | SP | October | Sunday | Night | Not Delayed | Not Delivered |
| 58266 | 770d331c84e5b214bd9dc70a10b829d0 | 6c57e6119369185e575b36712766b0ef | Canceled | 2016-10-07 14:52:30 | 2016-10-07 15:07:10 | 2016-10-11 15:07:11 | 2016-10-14 15:07:11 | 2016-11-29 | 1 | Credit Card | perfumaria | RJ | October | Friday | Afternoon | Not Delayed | Not Delivered |
| 59332 | 8beb59392e21af5eb9547ae1a9938d06 | bf609b5741f71697f65ce3852c5d2623 | Canceled | 2016-10-08 20:17:50 | 2016-10-09 14:34:30 | 2016-10-14 22:45:26 | 2016-10-19 18:47:43 | 2016-11-30 | 1 | Credit Card | brinquedos | RJ | October | Saturday | Evening | Not Delayed | Not Delivered |
| 92636 | 65d1e226dfaeb8cdc42f665422522d14 | 70fc57eeae292675927697fe03ad3ff5 | Canceled | 2016-10-03 21:01:41 | 2016-10-04 10:18:57 | 2016-10-25 12:14:28 | 2016-11-08 10:58:34 | 2016-11-25 | 1 | Credit Card | esporte_lazer | RJ | October | Monday | Evening | Not Delayed | Not Delivered |
| 94399 | 2c45c33d2f9cb8ff8b1c86cc28c11c30 | de4caa97afa80c8eeac2ff4c8da5b72e | Canceled | 2016-10-09 15:39:56 | 2016-10-10 10:40:49 | 2016-10-14 10:40:50 | 2016-11-09 14:53:50 | 2016-12-08 | 1 | Credit Card | fashion_bolsas_e_acessorios | SC | October | Sunday | Afternoon | Not Delayed | Not Delivered |
Key Observations:
There are orders without “delivered” status that have delivery timestamps. Most likely these orders were canceled after delivery.
Let’s examine their reviews
messages = (
df_orders[lambda x: (x.order_status != 'Delivered') & ~x.order_delivered_customer_dt.isna()]
.merge(df_reviews, on='order_id', how='left')
['review_comment_message']
.dropna()
.tolist()
)
display(messages)
['the product was not shipped because i made a mistake typing my home number',
'i would buy again because they meet the delivery deadline and the products are super packed',
'the product is fake ridiculous',
'the product was not delivered no invoice was sent telephone for complaint does not work',
'the product was purchased on 10/10/2016 it has not arrived and now i receive this review asking what i thought very dissatisfied',
'it says that my order was delivered but it did not arrive is it possible to inform the signature of the person who received it on the spot']
Key Observations:
Review messages indicate these orders were not delivered.
Status is “delivered” but delivery timestamp is missing
Let’s check if there are orders with “delivered” status but missing delivery timestamps.
df_orders[lambda x: x.order_status.isin(['Delivered']) & x.order_delivered_customer_dt.isna()]
| order_id | customer_id | order_status | order_purchase_dt | order_approved_dt | order_delivered_carrier_dt | order_delivered_customer_dt | order_estimated_delivery_dt | tmp_avg_reviews_score | tmp_payment_types | tmp_product_categories | tmp_customer_state | tmp_order_purchase_month | tmp_order_purchase_weekday | tmp_purchase_time_of_day | tmp_is_delayed | tmp_is_delivered | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3002 | 2d1e2d5bf4dc7227b3bfebb81328c15f | ec05a6d8558c6455f0cbbd8a420ad34f | Delivered | 2017-11-28 17:44:07 | 2017-11-28 17:56:40 | 2017-11-30 18:12:23 | NaT | 2017-12-18 | 5 | Credit Card | automotivo | SP | November | Tuesday | Evening | Missing delivery dt | Delivered |
| 20618 | f5dd62b788049ad9fc0526e3ad11a097 | 5e89028e024b381dc84a13a3570decb4 | Delivered | 2018-06-20 06:58:43 | 2018-06-20 07:19:05 | 2018-06-25 08:05:00 | NaT | 2018-07-16 | 5 | Debit Card | industria_comercio_e_negocios | SP | June | Wednesday | Morning | Missing delivery dt | Delivered |
| 43834 | 2ebdfc4f15f23b91474edf87475f108e | 29f0540231702fda0cfdee0a310f11aa | Delivered | 2018-07-01 17:05:11 | 2018-07-01 17:15:12 | 2018-07-03 13:57:00 | NaT | 2018-07-30 | 5 | Credit Card | relogios_presentes | SP | July | Sunday | Evening | Missing delivery dt | Delivered |
| 79263 | e69f75a717d64fc5ecdfae42b2e8e086 | cfda40ca8dd0a5d486a9635b611b398a | Delivered | 2018-07-01 22:05:55 | 2018-07-01 22:15:14 | 2018-07-03 13:57:00 | NaT | 2018-07-30 | 5 | Credit Card | relogios_presentes | SP | July | Sunday | Evening | Missing delivery dt | Delivered |
| 82868 | 0d3268bad9b086af767785e3f0fc0133 | 4f1d63d35fb7c8999853b2699f5c7649 | Delivered | 2018-07-01 21:14:02 | 2018-07-01 21:29:54 | 2018-07-03 09:28:00 | NaT | 2018-07-24 | 5 | Credit Card | brinquedos | SP | July | Sunday | Evening | Missing delivery dt | Delivered |
| 92643 | 2d858f451373b04fb5c984a1cc2defaf | e08caf668d499a6d643dafd7c5cc498a | Delivered | 2017-05-25 23:22:43 | 2017-05-25 23:30:16 | NaT | NaT | 2017-06-23 | 5 | Credit Card | esporte_lazer | RS | May | Thursday | Night | Missing delivery dt | Delivered |
| 97647 | ab7c89dc1bf4a1ead9d6ec1ec8968a84 | dd1b84a7286eb4524d52af4256c0ba24 | Delivered | 2018-06-08 12:09:39 | 2018-06-08 12:36:39 | 2018-06-12 14:10:00 | NaT | 2018-06-26 | 1 | Credit Card | informatica_acessorios | SP | June | Friday | Afternoon | Missing delivery dt | Delivered |
| 98038 | 20edc82cf5400ce95e1afacc25798b31 | 28c37425f1127d887d7337f284080a0f | Delivered | 2018-06-27 16:09:12 | 2018-06-27 16:29:30 | 2018-07-03 19:26:00 | NaT | 2018-07-19 | 5 | Credit Card | livros_interesse_geral | SP | June | Wednesday | Afternoon | Missing delivery dt | Delivered |
Key Observations:
The dataset contains 8 orders with “delivered” status but missing delivery timestamps.
Let’s examine their reviews
messages = (
df_orders[lambda x: x.order_status.isin(['Delivered']) & x.order_delivered_customer_dt.isna()]
.merge(df_reviews, on='order_id', how='left')
['review_comment_message']
.dropna()
.tolist()
)
display(messages)
['arrived quickly everything ok',
'new product very good',
'the product arrived much earlier than expected came in great condition and very well packaged i recommend',
'i bought a product from a brand and received another inferior to what i bought not to mention that they charged me shipping and i had to pick it up at the post office',
'i loved']
Key Observations:
Review messages suggest the products were actually delivered.
Order canceled or unavailable but has delivery timestamp
Let’s check if there are orders with “canceled” or “unavailable” status that still have delivery timestamps.
df_orders[lambda x: x.order_status.isin(['Canceled', 'Unavailable']) & ~x.order_delivered_customer_dt.isna()]
| order_id | customer_id | order_status | order_purchase_dt | order_approved_dt | order_delivered_carrier_dt | order_delivered_customer_dt | order_estimated_delivery_dt | tmp_avg_reviews_score | tmp_payment_types | tmp_product_categories | tmp_customer_state | tmp_order_purchase_month | tmp_order_purchase_weekday | tmp_purchase_time_of_day | tmp_is_delayed | tmp_is_delivered | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2921 | 1950d777989f6a877539f53795b4c3c3 | 1bccb206de9f0f25adc6871a1bcf77b2 | Canceled | 2018-02-19 19:48:52 | 2018-02-19 20:56:05 | 2018-02-20 19:57:13 | 2018-03-21 22:03:51 | 2018-03-09 | 3 | Credit Card | beleza_saude | MG | February | Monday | Evening | Delayed | Not Delivered |
| 8791 | dabf2b0e35b423f94618bf965fcb7514 | 5cdec0bb8cbdf53ffc8fdc212cd247c6 | Canceled | 2016-10-09 00:56:52 | 2016-10-09 13:36:58 | 2016-10-13 13:36:59 | 2016-10-16 14:36:59 | 2016-11-30 | 5 | Credit Card | perfumaria, beleza_saude | SP | October | Sunday | Night | Not Delayed | Not Delivered |
| 58266 | 770d331c84e5b214bd9dc70a10b829d0 | 6c57e6119369185e575b36712766b0ef | Canceled | 2016-10-07 14:52:30 | 2016-10-07 15:07:10 | 2016-10-11 15:07:11 | 2016-10-14 15:07:11 | 2016-11-29 | 1 | Credit Card | perfumaria | RJ | October | Friday | Afternoon | Not Delayed | Not Delivered |
| 59332 | 8beb59392e21af5eb9547ae1a9938d06 | bf609b5741f71697f65ce3852c5d2623 | Canceled | 2016-10-08 20:17:50 | 2016-10-09 14:34:30 | 2016-10-14 22:45:26 | 2016-10-19 18:47:43 | 2016-11-30 | 1 | Credit Card | brinquedos | RJ | October | Saturday | Evening | Not Delayed | Not Delivered |
| 92636 | 65d1e226dfaeb8cdc42f665422522d14 | 70fc57eeae292675927697fe03ad3ff5 | Canceled | 2016-10-03 21:01:41 | 2016-10-04 10:18:57 | 2016-10-25 12:14:28 | 2016-11-08 10:58:34 | 2016-11-25 | 1 | Credit Card | esporte_lazer | RJ | October | Monday | Evening | Not Delayed | Not Delivered |
| 94399 | 2c45c33d2f9cb8ff8b1c86cc28c11c30 | de4caa97afa80c8eeac2ff4c8da5b72e | Canceled | 2016-10-09 15:39:56 | 2016-10-10 10:40:49 | 2016-10-14 10:40:50 | 2016-11-09 14:53:50 | 2016-12-08 | 1 | Credit Card | fashion_bolsas_e_acessorios | SC | October | Sunday | Afternoon | Not Delayed | Not Delivered |
Key Observations:
The dataset contains 6 orders with “canceled” status that have customer delivery timestamps
Let’s examine their reviews
messages = (
df_orders[lambda x: x.order_status.isin(['Canceled', 'Unavailable']) & ~x.order_delivered_customer_dt.isna()]
.merge(df_reviews, on='order_id', how='left')
['review_comment_message']
.dropna()
.tolist()
)
display(messages)
['the product was not shipped because i made a mistake typing my home number',
'i would buy again because they meet the delivery deadline and the products are super packed',
'the product is fake ridiculous',
'the product was not delivered no invoice was sent telephone for complaint does not work',
'the product was purchased on 10/10/2016 it has not arrived and now i receive this review asking what i thought very dissatisfied',
'it says that my order was delivered but it did not arrive is it possible to inform the signature of the person who received it on the spot']
Key Observations:
Review messages indicate some items were delivered while others were not.
Date Inconsistencies#
order_purchase_dt
Let’s check if there are timestamps earlier than purchase dates.
for col_dt in ['order_approved_dt', 'order_delivered_carrier_dt', 'order_delivered_customer_dt']:
rows_cnt = df_orders[~(df_orders['order_purchase_dt'].isna() | df_orders[col_dt].isna()
| (df_orders['order_purchase_dt'] <= df_orders[col_dt]))].shape[0]
if rows_cnt:
print(f'{col_dt} < order_purchase_dt, rows count: {rows_cnt}')
order_delivered_carrier_dt < order_purchase_dt, rows count: 166
Key Observations:
There are 166 orders where carrier handover time is earlier than purchase time. This is unusual.
Let’s examine the dataframe
tmp_mask = ~(df_orders['order_purchase_dt'].isna() | df_orders['order_delivered_carrier_dt'].isna()
| (df_orders['order_purchase_dt'] <= df_orders['order_delivered_carrier_dt']))
tmp_df_orders = df_orders[tmp_mask]
print(f'rows: {tmp_df_orders.shape[0]}')
display(tmp_df_orders.head(5))
rows: 166
| order_id | customer_id | order_status | order_purchase_dt | order_approved_dt | order_delivered_carrier_dt | order_delivered_customer_dt | order_estimated_delivery_dt | tmp_avg_reviews_score | tmp_payment_types | tmp_product_categories | tmp_customer_state | tmp_order_purchase_month | tmp_order_purchase_weekday | tmp_purchase_time_of_day | tmp_is_delayed | tmp_is_delivered | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 615 | b9afddbdcfadc9a87b41a83271c3e888 | 85c6af75161b8b2b1af98e82b5a6a5a5 | Delivered | 2018-08-16 13:50:48 | 2018-08-16 14:05:13 | 2018-08-16 13:27:00 | 2018-08-24 14:58:37 | 2018-09-04 | 5 | Credit Card | cama_mesa_banho | RJ | August | Thursday | Afternoon | Not Delayed | Delivered |
| 1111 | ad133696906f6a78826daa0911b7daec | e6f5b234bb0d847f10eebd70130c5d49 | Delivered | 2018-06-15 15:41:22 | 2018-06-15 16:19:23 | 2018-06-15 14:52:00 | 2018-06-22 18:09:37 | 2018-07-18 | 5 | Credit Card | beleza_saude | SC | June | Friday | Afternoon | Not Delayed | Delivered |
| 1329 | 74e033208dc13a7b8127eb8e73d09b76 | 72fcbb1145f2889eddcba6d6c1d6c090 | Delivered | 2018-05-02 10:48:44 | 2018-05-02 11:13:45 | 2018-05-02 09:49:00 | 2018-05-07 23:06:36 | 2018-05-29 | 5 | Credit Card | beleza_saude | PR | May | Wednesday | Morning | Not Delayed | Delivered |
| 1372 | a6b58794fd2ba533359a76c08df576e3 | ccd8e3459ad58ae538c9d2cf35532ba4 | Delivered | 2018-05-14 15:18:23 | 2018-05-14 15:33:35 | 2018-05-14 13:46:00 | 2018-05-19 19:33:32 | 2018-06-08 | 4 | Credit Card | cama_mesa_banho | RS | May | Monday | Afternoon | Not Delayed | Delivered |
| 1864 | 5792e0b1c8c8a2bf53af468c9a422c88 | 5c427f06e7fcf902e309743516e2c580 | Delivered | 2018-07-26 13:25:14 | 2018-07-26 13:35:14 | 2018-07-26 12:42:00 | 2018-07-30 14:45:02 | 2018-08-09 | 5 | Credit Card | relogios_presentes | SP | July | Thursday | Afternoon | Not Delayed | Delivered |
Let’s analyze by day
tmp_df_orders.explore.anomalies_over_time(
time_column='order_purchase_dt'
, custom_mask=tmp_mask
, freq='D'
)
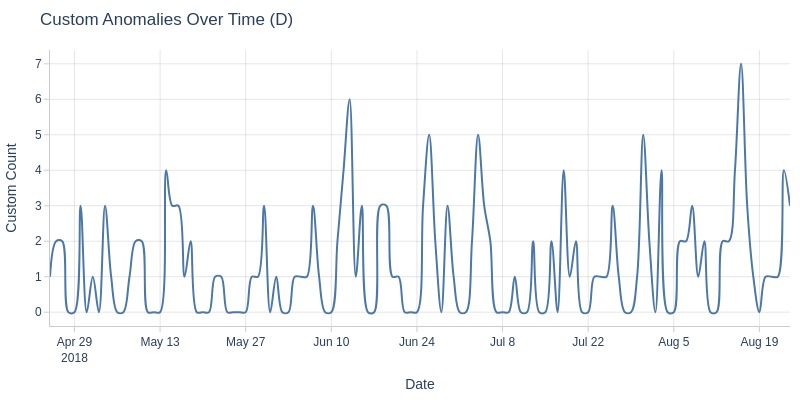
Key Observations:
These anomalies only occurred between 25 April and 24 August 2018.
Let’s analyze by order status
df_orders.explore.anomalies_by_categories(
custom_mask=tmp_mask
, pct_diff_threshold=-100
, include_columns='order_status'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| order_status | Delivered | 96478 | 165 | 0.2% | 97.0% | 99.4% | 2.4% |
| order_status | Shipped | 1107 | 1 | 0.1% | 1.1% | 0.6% | -0.5% |
Let’s look at it broken down by payment type.
df_orders.explore.anomalies_by_categories(
custom_mask=tmp_mask
, pct_diff_threshold=-100
, include_columns='tmp_payment_types'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| tmp_payment_types | Credit Card | 74259 | 155 | 0.2% | 74.7% | 93.4% | 18.7% |
| tmp_payment_types | Debit Card | 1527 | 5 | 0.3% | 1.5% | 3.0% | 1.5% |
| tmp_payment_types | Voucher | 1621 | 3 | 0.2% | 1.6% | 1.8% | 0.2% |
| tmp_payment_types | Boleto | 19784 | 3 | 0.0% | 19.9% | 1.8% | -18.1% |
Key Observations:
Over 90% of anomalous orders were paid by credit card.
Let’s analyze by time of day
df_orders.explore.anomalies_by_categories(
custom_mask=tmp_mask
, pct_diff_threshold=-100
, include_columns='tmp_purchase_time_of_day'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| tmp_purchase_time_of_day | Afternoon | 32211 | 136 | 0.4% | 32.4% | 81.9% | 49.5% |
| tmp_purchase_time_of_day | Morning | 22634 | 28 | 0.1% | 22.8% | 16.9% | -5.9% |
| tmp_purchase_time_of_day | Evening | 36127 | 2 | 0.0% | 36.3% | 1.2% | -35.1% |
Key Observations:
Most anomalies occurred in the afternoon.
Let’s examine their reviews
messages = (
tmp_df_orders.merge(df_reviews, on='order_id', how='left')
['review_comment_message']
.dropna()
.sample(20)
.tolist()
)
display(messages)
['kidnaps',
'very good product and fast delivery',
'beautiful just like the photo',
'i haven t tested the product yet but apparently it looks good after i test complete my curriculum mentarium',
'product as photo and specifications very good',
'i thought it was good and it was delivered well before the deadline',
'all well satisfied',
'i don t have the product in hand',
'i really liked the product i highly recommend it',
'very good',
'the product is very good it delivers what it promises',
'arrived before the deadline established everything perfect',
'i m testing the product i hope it s good',
'i really liked great quality',
'request answered correctly grateful',
'they should only put the watch in suitable packaging came wrapped in plastic',
'i loved the table what a pity that i got confused in the color i bought it thinking it would be white but it is nude but it s ok very beautiful it s worth it',
'is in the process of returning the printer did not accept the cartridge',
'the product is much smaller than what it shows in the photo this type of product testifies against the american with',
'delivery was ahead of schedule i recommend']
Key Observations:
Nothing unusual found.
order_approved_dt
Let’s check if there are timestamps that should occur after approval but appear earlier.
for col_dt in ['order_delivered_carrier_dt', 'order_delivered_customer_dt']:
rows_cnt = df_orders[~(df_orders['order_approved_dt'].isna() | df_orders[col_dt].isna()
| (df_orders['order_approved_dt'] <= df_orders[col_dt]))].shape[0]
if rows_cnt:
print(f'{col_dt} < order_approved_dt, rows count: {rows_cnt}')
order_delivered_carrier_dt < order_approved_dt, rows count: 1359
order_delivered_customer_dt < order_approved_dt, rows count: 61
Key Observations:
There are 1,359 orders where carrier handover time is earlier than payment approval time.
There are 61 orders where delivery time is earlier than payment approval time.
Let’s examine each one separately.
order_delivered_carrier_dt < order_approved_dt
Let’s examine the dataframe
tmp_mask = ~(df_orders['order_approved_dt'].isna() | df_orders['order_delivered_carrier_dt'].isna()
| (df_orders['order_approved_dt'] <= df_orders['order_delivered_carrier_dt']))
tmp_df_orders = df_orders[tmp_mask]
print(f'rows: {tmp_df_orders.shape[0]}')
display(tmp_df_orders.head(5))
rows: 1359
| order_id | customer_id | order_status | order_purchase_dt | order_approved_dt | order_delivered_carrier_dt | order_delivered_customer_dt | order_estimated_delivery_dt | tmp_avg_reviews_score | tmp_payment_types | tmp_product_categories | tmp_customer_state | tmp_order_purchase_month | tmp_order_purchase_weekday | tmp_purchase_time_of_day | tmp_is_delayed | tmp_is_delivered | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 15 | dcb36b511fcac050b97cd5c05de84dc3 | 3b6828a50ffe546942b7a473d70ac0fc | Delivered | 2018-06-07 19:03:12 | 2018-06-12 23:31:02 | 2018-06-11 14:54:00 | 2018-06-21 15:34:32 | 2018-07-04 | 5 | Credit Card | perfumaria | GO | June | Thursday | Evening | Not Delayed | Delivered |
| 64 | 688052146432ef8253587b930b01a06d | 81e08b08e5ed4472008030d70327c71f | Delivered | 2018-04-22 08:48:13 | 2018-04-24 18:25:22 | 2018-04-23 19:19:14 | 2018-04-24 19:31:58 | 2018-05-15 | 4 | Credit Card | informatica_acessorios, malas_acessorios | MG | April | Sunday | Morning | Not Delayed | Delivered |
| 199 | 58d4c4747ee059eeeb865b349b41f53a | 1755fad7863475346bc6c3773fe055d3 | Delivered | 2018-07-21 12:49:32 | 2018-07-26 23:31:53 | 2018-07-24 12:57:00 | 2018-07-25 23:58:19 | 2018-07-31 | 5 | Boleto | automotivo | SP | July | Saturday | Afternoon | Not Delayed | Delivered |
| 210 | 412fccb2b44a99b36714bca3fef8ad7b | c6865c523687cb3f235aa599afef1710 | Delivered | 2018-07-22 22:30:05 | 2018-07-23 12:31:53 | 2018-07-23 12:24:00 | 2018-07-24 19:26:42 | 2018-07-31 | 5 | Credit Card | industria_comercio_e_negocios | SP | July | Sunday | Evening | Not Delayed | Delivered |
| 415 | 56a4ac10a4a8f2ba7693523bb439eede | 78438ba6ace7d2cb023dbbc81b083562 | Delivered | 2018-07-22 13:04:47 | 2018-07-27 23:31:09 | 2018-07-24 14:03:00 | 2018-07-28 00:05:39 | 2018-08-06 | 5 | Boleto | eletronicos | SP | July | Sunday | Afternoon | Not Delayed | Delivered |
Let’s examine by days
tmp_df_orders.explore.anomalies_over_time(
time_column='order_purchase_dt'
, custom_mask=tmp_mask
, freq='D'
)
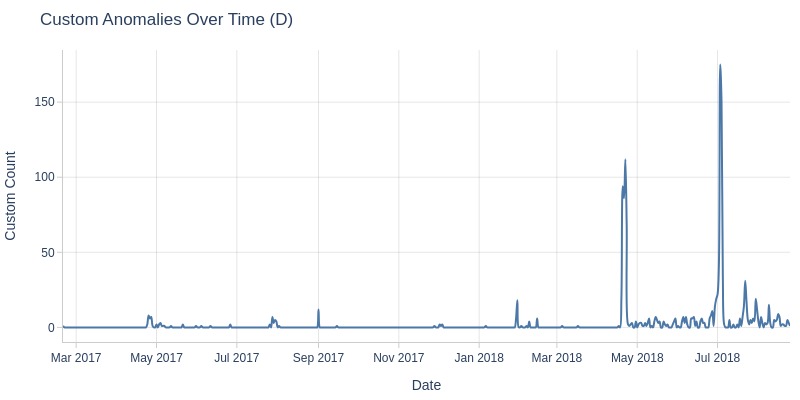
Key Observations:
Days with most anomalies:
19-23 April 2018
3-4 July 2018
Possible system issues caused delayed payment approvals.
Let’s analyze by order status
df_orders.explore.anomalies_by_categories(
custom_mask=tmp_mask
, pct_diff_threshold=-100
, include_columns='order_status'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| order_status | Delivered | 96478 | 1350 | 1.4% | 97.0% | 99.3% | 2.3% |
| order_status | Shipped | 1107 | 9 | 0.8% | 1.1% | 0.7% | -0.5% |
Key Observations:
Nearly all orders were eventually delivered.
Let’s analyze by time of day
df_orders.explore.anomalies_by_categories(
custom_mask=tmp_mask
, pct_diff_threshold=-100
, include_columns='tmp_purchase_time_of_day'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| tmp_purchase_time_of_day | Afternoon | 32211 | 555 | 1.7% | 32.4% | 40.8% | 8.4% |
| tmp_purchase_time_of_day | Morning | 22634 | 326 | 1.4% | 22.8% | 24.0% | 1.2% |
| tmp_purchase_time_of_day | Night | 8469 | 94 | 1.1% | 8.5% | 6.9% | -1.6% |
| tmp_purchase_time_of_day | Evening | 36127 | 384 | 1.1% | 36.3% | 28.3% | -8.1% |
Key Observations:
More anomalies occurred in the afternoon.
order_delivered_customer_dt < order_approved_dt
tmp_mask = ~(df_orders['order_approved_dt'].isna() | df_orders['order_delivered_customer_dt'].isna()
| (df_orders['order_approved_dt'] <= df_orders['order_delivered_customer_dt']))
tmp_df_orders = df_orders[tmp_mask]
Let’s examine by days
tmp_df_orders.explore.anomalies_over_time(
time_column='order_purchase_dt'
, custom_mask=tmp_mask
, freq='D'
)
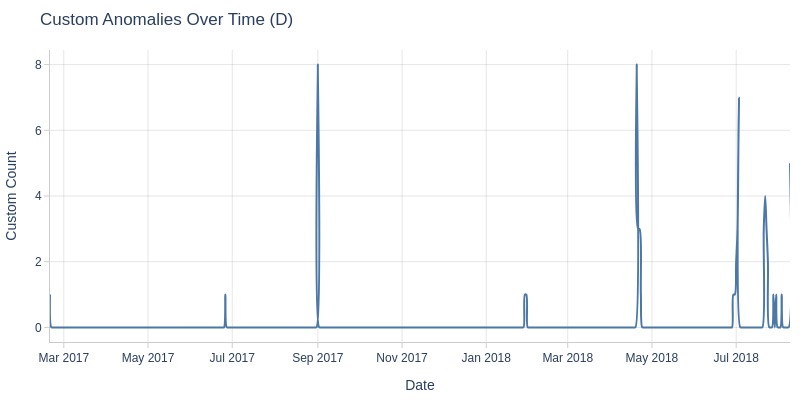
Key Observations:
Anomalies occurred sporadically on specific dates.
Let’s look at it broken down by payment type.
df_orders.explore.anomalies_by_categories(
custom_mask=tmp_mask
, pct_diff_threshold=-100
, include_columns='tmp_payment_types'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| tmp_payment_types | Boleto | 19784 | 21 | 0.1% | 19.9% | 34.4% | 14.5% |
| tmp_payment_types | Debit Card | 1527 | 7 | 0.5% | 1.5% | 11.5% | 9.9% |
| tmp_payment_types | Credit Card, Voucher | 1127 | 1 | 0.1% | 1.1% | 1.6% | 0.5% |
| tmp_payment_types | Voucher | 1621 | 1 | 0.1% | 1.6% | 1.6% | 0.0% |
| tmp_payment_types | Credit Card | 74259 | 31 | 0.0% | 74.7% | 50.8% | -23.9% |
Key Observations:
“Boleto” payments had significantly more anomalies.
Let’s analyze by customer state
df_orders.explore.anomalies_by_categories(
custom_mask=tmp_mask
, pct_diff_threshold=-100
, include_columns='tmp_customer_state'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| tmp_customer_state | SP | 41746 | 53 | 0.1% | 42.0% | 86.9% | 44.9% |
| tmp_customer_state | CE | 1336 | 1 | 0.1% | 1.3% | 1.6% | 0.3% |
| tmp_customer_state | PR | 5045 | 3 | 0.1% | 5.1% | 4.9% | -0.2% |
| tmp_customer_state | MG | 11635 | 2 | 0.0% | 11.7% | 3.3% | -8.4% |
| tmp_customer_state | RJ | 12852 | 2 | 0.0% | 12.9% | 3.3% | -9.6% |
Key Observations:
Most anomalies occurred in São Paulo.
order_delivered_carrier_dt
Let’s check if there are timestamps that should occur after carrier handover but appear earlier.
tmp_mask = ~(df_orders['order_delivered_carrier_dt'].isna() | df_orders['order_delivered_customer_dt'].isna()
| (df_orders['order_delivered_carrier_dt'] <= df_orders['order_delivered_customer_dt']))
rows_cnt = df_orders[tmp_mask].shape[0]
if rows_cnt:
print(f'order_delivered_customer_dt < order_delivered_carrier_dt, rows count: {rows_cnt}')
order_delivered_customer_dt < order_delivered_carrier_dt, rows count: 23
Key Observations:
There are 23 orders where delivery time is earlier than carrier handover time.
review_creation_dt < order_purchase_dt
We have order creation time and review creation time. Let’s check if any reviews were created before their corresponding orders.
temp_df = df_orders.merge(df_reviews, on='order_id', how='left')
temp_df = temp_df[lambda x: x.order_purchase_dt.dt.date > x.review_creation_dt]
temp_df.shape[0]
65
The dataset contains 65 orders where reviews were created before the orders themselves.
Let’s examine them
temp_df.head()
| order_id | customer_id | order_status | order_purchase_dt | order_approved_dt | order_delivered_carrier_dt | order_delivered_customer_dt | order_estimated_delivery_dt | tmp_avg_reviews_score | tmp_payment_types | tmp_product_categories | tmp_customer_state | tmp_order_purchase_month | tmp_order_purchase_weekday | tmp_purchase_time_of_day | tmp_is_delayed | tmp_is_delivered | review_id | review_score | review_comment_title | review_comment_message | review_creation_dt | review_answer_dt | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1811 | ed3efbd3a87bea76c2812c66a0b32219 | 191984a8ba4cbb2145acb4fe35b69664 | Canceled | 2018-09-20 13:54:16 | NaT | NaT | NaT | 2018-10-17 | 2 | Voucher | Missing in Items | MG | September | Thursday | Afternoon | Missing delivery dt | Not Delivered | 6e4344680dbd30c75f78394e0dcfffdf | 2 | NaN | the product came with a defect it does not tur... | 2018-07-28 | 2018-07-30 11:06:16 |
| 2040 | 8d4c637f1accf7a88a4555f02741e606 | b1dd715db389a2077f43174e7a675d07 | Canceled | 2018-08-29 16:27:49 | NaT | NaT | NaT | 2018-09-13 | 5 | Voucher | Missing in Items | SP | August | Wednesday | Afternoon | Missing delivery dt | Not Delivered | 0f54fea9e89c2a9398b2bd56e3880eda | 5 | i loved | NaN | 2018-08-26 | 2018-08-26 20:21:38 |
| 3110 | 5290c34bd38a8a095b885f13958db1e1 | 92af427e290117f39d9ff908566072e0 | Canceled | 2018-08-21 10:25:18 | NaT | NaT | NaT | 2018-09-06 | 3 | Voucher | Missing in Items | SP | August | Tuesday | Morning | Missing delivery dt | Not Delivered | 3a5a10d592a6e639cdb9330c9e6d2a87 | 3 | 3 | NaN | 2018-08-18 | 2018-08-21 00:47:13 |
| 3702 | 03310aa823a66056268a3bab36e827fb | 25dbbf0c477fd4ae0880aaffbb12e8b3 | Canceled | 2018-08-07 16:33:59 | NaT | NaT | NaT | 2018-09-04 | 1 | Voucher | Missing in Items | SC | August | Tuesday | Afternoon | Missing delivery dt | Not Delivered | 08528f70f579f0c830189efc523d2182 | 1 | wrong product | delivery of the product different from the one... | 2018-08-03 | 2018-08-06 00:09:52 |
| 4396 | 4c8b9947280829d0a8b7e81cc249b875 | 403c35c4d8813bf67b3d396b91ca1619 | Canceled | 2018-08-09 14:54:47 | NaT | NaT | NaT | 2018-08-21 | 1 | Voucher | Missing in Items | SP | August | Thursday | Afternoon | Missing delivery dt | Not Delivered | 18071cb247f057c348988037fa94a0cd | 1 | ambiguous ad goes wrong | contact lenses are positive for farsightedness... | 2018-08-02 | 2018-08-03 01:34:51 |
Let’s look at how many orders do not have an approval payment date.
temp_df.order_approved_dt.isna().sum()
np.int64(57)
Let’s look at how many orders do not have a delivery date.
temp_df.order_approved_dt.isna().sum()
np.int64(57)
Let’s look at how many of them were canceled.
temp_df.order_status.value_counts()
order_status
Canceled 58
Delivered 6
Shipped 1
Approved 0
Created 0
Invoiced 0
Processing 0
Unavailable 0
Name: count, dtype: int64
Key Observations:
The dataset contains 65 orders where reviews were created before the orders themselves. 58 orders were canceled. 6 were delivered. 1 was in delivery process.
Let’s examine the 6 delivered orders
temp_df[temp_df.order_status=='Delivered']
| order_id | customer_id | order_status | order_purchase_dt | order_approved_dt | order_delivered_carrier_dt | order_delivered_customer_dt | order_estimated_delivery_dt | tmp_avg_reviews_score | tmp_payment_types | tmp_product_categories | tmp_customer_state | tmp_order_purchase_month | tmp_order_purchase_weekday | tmp_purchase_time_of_day | tmp_is_delayed | tmp_is_delivered | review_id | review_score | review_comment_title | review_comment_message | review_creation_dt | review_answer_dt | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 32582 | ebc94658c583ab37ad4f8e9091c4bef2 | 92dbb92ac5c6b1822c3aa951d33e61d0 | Delivered | 2018-04-14 08:22:43 | 2018-04-24 18:04:50 | 2018-04-26 15:57:00 | 2018-04-30 20:39:01 | 2018-05-03 | 2 | Voucher | utilidades_domesticas | MG | April | Saturday | Morning | Not Delayed | Delivered | d25026282e14fc531f0711246e121cc2 | 2 | NaN | it was delivered on time but the product with ... | 2018-03-30 | 2018-04-02 00:32:35 |
| 44345 | 82fd1196a459f594fb1d66e667fc74c4 | ef9b9b1cb4921466d4190e3116fe248e | Delivered | 2018-04-10 21:09:18 | 2018-04-11 09:30:27 | 2018-04-17 16:04:51 | 2018-04-21 00:51:34 | 2018-05-02 | 2 | Voucher | cama_mesa_banho | SP | April | Tuesday | Evening | Not Delayed | Delivered | 19194f53840fc6c2857dd8809972a209 | 4 | NaN | NaN | 2018-01-23 | 2018-01-24 12:43:58 |
| 50153 | 4bb9c2002502ca416276dc1ff5efb1b3 | e0e553d46d86daa33b733b1fd2687731 | Delivered | 2018-06-23 14:53:03 | 2018-06-27 14:20:08 | 2018-06-29 15:30:00 | 2018-07-17 17:08:47 | 2018-07-27 | 1 | Voucher | audio | BA | June | Saturday | Afternoon | Not Delayed | Delivered | 0857872f03ef22e3dbe8391c4dd331f6 | 1 | was not delivered | NaN | 2018-05-18 | 2018-05-21 18:15:06 |
| 70100 | 4a62fb19d5fa08fb514619dfcc617b3d | 4d1bb9a4d16191ced3d0d1c473ccbc97 | Delivered | 2018-05-09 19:23:46 | 2018-05-10 14:32:42 | 2018-05-11 14:44:00 | 2018-05-15 18:12:35 | 2018-05-25 | 3 | Voucher | relogios_presentes | SP | May | Wednesday | Evening | Not Delayed | Delivered | a935b3d67f406bac4853776d80a05220 | 3 | finishing | i m trying to get in touch with stark to check... | 2018-05-05 | 2018-05-08 02:06:50 |
| 70219 | 450c49623c365a4edcf0c5a2c93aa7c9 | 5a1739996fb7a15067fa38c3a0a1097e | Delivered | 2017-03-01 08:08:10 | 2017-03-02 15:32:28 | 2017-03-03 13:42:55 | 2017-03-08 10:26:04 | 2017-03-29 | 3 | Voucher | papelaria | MG | March | Wednesday | Morning | Not Delayed | Delivered | 778826f9af6467ff6268bbcf436cd3c5 | 1 | NaN | the product was sent defective | 2017-02-22 | 2017-02-22 14:05:09 |
| 90334 | 96f5be02bc9ffc589f3274500a64a7e2 | 5396ffb28b2d1cbea8d6ec46201f06ba | Delivered | 2018-04-23 14:31:55 | 2018-04-27 16:11:21 | 2018-05-11 12:26:00 | 2018-05-16 18:19:00 | 2018-06-01 | 2 | Voucher | moveis_escritorio | RJ | April | Monday | Afternoon | Not Delayed | Delivered | e2fc0692ed820a5802c1505a77cf7870 | 1 | NaN | the product delivered was not the product purc... | 2018-04-04 | 2018-04-05 03:20:55 |
We previously determined that one order can have multiple reviews and one review can cover multiple orders.
Let’s check for duplicates in these orders and reviews.
temp_unque_orders = temp_df.order_id.unique()
temp_unque_reviews = temp_df.review_id.unique()
df_reviews[df_reviews.review_id.isin(temp_unque_reviews)].merge(df_orders, on='order_id', how='left').sort_values('review_id').head()
| review_id | order_id | review_score | review_comment_title | review_comment_message | review_creation_dt | review_answer_dt | customer_id | order_status | order_purchase_dt | order_approved_dt | order_delivered_carrier_dt | order_delivered_customer_dt | order_estimated_delivery_dt | tmp_avg_reviews_score | tmp_payment_types | tmp_product_categories | tmp_customer_state | tmp_order_purchase_month | tmp_order_purchase_weekday | tmp_purchase_time_of_day | tmp_is_delayed | tmp_is_delivered | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 41 | 047fd109ced39e02296f6aeb74f6a6f1 | 236e6ec6171c1870d4bcf4ccfad87f49 | 4 | NaN | NaN | 2018-07-31 | 2018-08-02 15:11:49 | 0fa12cb295663a40f53876e73aa7c460 | Canceled | 2018-08-21 15:12:31 | NaT | NaT | NaT | 2018-09-11 | 4 | Voucher | Missing in Items | SP | August | Tuesday | Afternoon | Missing delivery dt | Not Delivered |
| 10 | 047fd109ced39e02296f6aeb74f6a6f1 | a89abace0dcc01eeb267a9660b5ac126 | 4 | NaN | NaN | 2018-07-31 | 2018-08-02 15:11:49 | 2f0524a7b1b3845a1a57fcf3910c4333 | Canceled | 2018-09-06 18:45:47 | NaT | NaT | NaT | 2018-09-27 | 4 | Voucher | Missing in Items | SP | September | Thursday | Evening | Missing delivery dt | Not Delivered |
| 31 | 08528f70f579f0c830189efc523d2182 | 03310aa823a66056268a3bab36e827fb | 1 | wrong product | delivery of the product different from the one... | 2018-08-03 | 2018-08-06 00:09:52 | 25dbbf0c477fd4ae0880aaffbb12e8b3 | Canceled | 2018-08-07 16:33:59 | NaT | NaT | NaT | 2018-09-04 | 1 | Voucher | Missing in Items | SC | August | Tuesday | Afternoon | Missing delivery dt | Not Delivered |
| 65 | 08528f70f579f0c830189efc523d2182 | 53c71d3953507c6239ff73917ed358c9 | 1 | wrong product | delivery of the product different from the one... | 2018-08-03 | 2018-08-06 00:09:52 | 26dcb450c4b5b390e79e6d5d0f2c6535 | Delivered | 2018-07-24 20:41:01 | 2018-07-24 20:55:31 | 2018-07-27 15:24:00 | 2018-08-02 18:41:16 | 2018-08-21 | 1 | Credit Card | cool_stuff | SC | July | Tuesday | Evening | Not Delayed | Delivered |
| 2 | 08528f70f579f0c830189efc523d2182 | 7813842ae95e8c497fc0233232ae815a | 1 | wrong product | delivery of the product different from the one... | 2018-08-03 | 2018-08-06 00:09:52 | 040d94f8ba8ca26014bd6f7e8a6e0c0d | Canceled | 2018-08-17 20:06:36 | NaT | NaT | NaT | 2018-09-17 | 1 | Voucher | Missing in Items | SC | August | Friday | Evening | Missing delivery dt | Not Delivered |
Even accounting for duplicates, both orders show review creation dates preceding order dates.
Let’s check if any review responses were created before the reviews themselves:
df_reviews[lambda x: x.review_creation_dt >=x.review_answer_dt]
| review_id | order_id | review_score | review_comment_title | review_comment_message | review_creation_dt | review_answer_dt |
|---|
No such cases found.
Table df_payments#
Let’s look at the information about the dataframe.
df_payments.explore.info()
| Summary | Column Types | |||
|---|---|---|---|---|
| Rows | 103.89k | Text | 1 | |
| Features | 5 | Categorical | 1 | |
| Missing cells | --- | Int | 2 | |
| Exact Duplicates | --- | Float | 1 | |
| Fuzzy Duplicates | --- | Datetime | 0 | |
| Memory Usage (Mb) | 11 | |||
Initial Column Analysis#
We will examine each column individually.
order_id
df_payments['order_id'].explore.info(plot=False)
| Summary | Text Metrics | |||
|---|---|---|---|---|
| Total Values | 103.89k (100%) | Avg Word Count | 1.0 | |
| Missing Values | --- | Max Length (chars) | 32.0 | |
| Empty Strings | --- | Avg Length (chars) | 32.0 | |
| Distinct Values | 99.44k (96%) | Median Length (chars) | 32.0 | |
| Non-Duplicates | 96.48k (93%) | Min Length (chars) | 32.0 | |
| Exact Duplicates | 4.45k (4%) | Most Common Length | 32 (100.0%) | |
| Fuzzy Duplicates | 4.45k (4%) | Avg Digit Ratio | 0.63 | |
| Values with Duplicates | 2.96k (3%) | |||
| Memory Usage | 8 | |||
Key Observations:
All is well.
payment_sequential
df_payments['payment_sequential'].explore.info(plot=False)
| Summary | Percentiles | Detailed Stats | Value Counts | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Total | 103.89k (100%) | Max | 29 | Mean | 1.09 | 1 | 99.36k (96%) | |||
| Missing | --- | 99% | 3 | Trimmed Mean (10%) | 1 | 2 | 3.04k (3%) | |||
| Distinct | 29 (<1%) | 95% | 1 | Mode | 1 | 3 | 581 (<1%) | |||
| Non-Duplicate | 3 (<1%) | 75% | 1 | Range | 28 | 4 | 278 (<1%) | |||
| Duplicates | 103.86k (99%) | 50% | 1 | IQR | 0 | 5 | 170 (<1%) | |||
| Dup. Values | 26 (<1%) | 25% | 1 | Std | 0.71 | 6 | 118 (<1%) | |||
| Zeros | --- | 5% | 1 | MAD | 0 | 7 | 82 (<1%) | |||
| Negative | --- | 1% | 1 | Kurt | 370.59 | 8 | 54 (<1%) | |||
| Memory Usage | 1 | Min | 1 | Skew | 16.18 | 9 | 43 (<1%) | |||
Key Observations:
The maximum number of payment methods for a single order is 29.
payment_type
df_payments['payment_type'].explore.info(plot=True)
| Summary | Text Metrics | Value Counts | |||||
|---|---|---|---|---|---|---|---|
| Total Values | 103.89k (100%) | Avg Word Count | 1.8 | Credit Card | 76.80k (74%) | ||
| Missing Values | --- | Max Length (chars) | 11.0 | Boleto | 19.78k (19%) | ||
| Empty Strings | --- | Avg Length (chars) | 9.8 | Voucher | 5.78k (6%) | ||
| Distinct Values | 5 (<1%) | Median Length (chars) | 11.0 | Debit Card | 1.53k (1%) | ||
| Non-Duplicates | --- | Min Length (chars) | 6.0 | Not Defined | 3 (<1%) | ||
| Exact Duplicates | 103.88k (99%) | Most Common Length | 11 (73.9%) | ||||
| Fuzzy Duplicates | 103.88k (99%) | Avg Digit Ratio | 0.00 | ||||
| Values with Duplicates | 5 (<1%) | ||||||
| Memory Usage | <1 Mb | ||||||
Key Observations:
74% of payments were made using credit cards.
The payment_type field contains undefined payment types (<1%).
payment_installments
df_payments['payment_installments'].explore.info()
| Summary | Percentiles | Detailed Stats | Value Counts | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Total | 103.89k (100%) | Max | 24 | Mean | 2.85 | 1 | 52.55k (51%) | |||
| Missing | --- | 99% | 10 | Trimmed Mean (10%) | 2.28 | 2 | 12.41k (12%) | |||
| Distinct | 24 (<1%) | 95% | 10 | Mode | 1 | 3 | 10.46k (10%) | |||
| Non-Duplicate | 2 (<1%) | 75% | 4 | Range | 24 | 4 | 7.10k (7%) | |||
| Duplicates | 103.86k (99%) | 50% | 1 | IQR | 3 | 10 | 5.33k (5%) | |||
| Dup. Values | 22 (<1%) | 25% | 1 | Std | 2.69 | 5 | 5.24k (5%) | |||
| Zeros | 2 (<1%) | 5% | 1 | MAD | 0 | 8 | 4.27k (4%) | |||
| Negative | --- | 1% | 1 | Kurt | 2.55 | 6 | 3.92k (4%) | |||
| Memory Usage | 1 | Min | 0 | Skew | 1.66 | 7 | 1.63k (2%) | |||
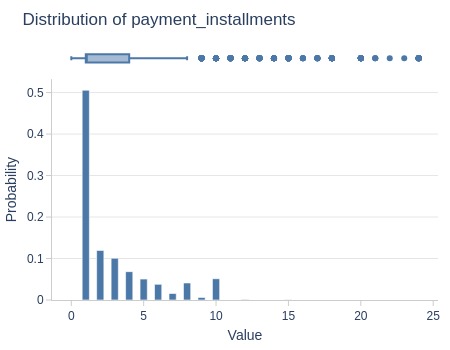
Key Observations:
The maximum number of installments for a product payment is 24.
The median number of payment installments is 1.
75% of orders have installment plans with 4 or fewer payments.
There are 2 orders with a value of 0 in payment_installments.
payment_value
df_payments['payment_value'].explore.info()
| Summary | Percentiles | Detailed Stats | Value Counts | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Total | 103.89k (100%) | Max | 13.66k | Mean | 154.10 | 50 | 324 (<1%) | |||
| Missing | --- | 99% | 1.04k | Trimmed Mean (10%) | 114.85 | 20 | 274 (<1%) | |||
| Distinct | 29.08k (28%) | 95% | 437.63 | Mode | 50 | 100 | 255 (<1%) | |||
| Non-Duplicate | 13.10k (13%) | 75% | 171.84 | Range | 13.66k | 77.57 | 250 (<1%) | |||
| Duplicates | 74.81k (72%) | 50% | 100 | IQR | 115.05 | 35 | 165 (<1%) | |||
| Dup. Values | 15.98k (15%) | 25% | 56.79 | Std | 217.49 | 73.34 | 160 (<1%) | |||
| Zeros | 9 (<1%) | 5% | 26.11 | MAD | 76.43 | 30 | 133 (<1%) | |||
| Negative | --- | 1% | 6.69 | Kurt | 241.83 | 116.94 | 131 (<1%) | |||
| Memory Usage | 1 | Min | 0 | Skew | 9.25 | 56.78 | 122 (<1%) | |||
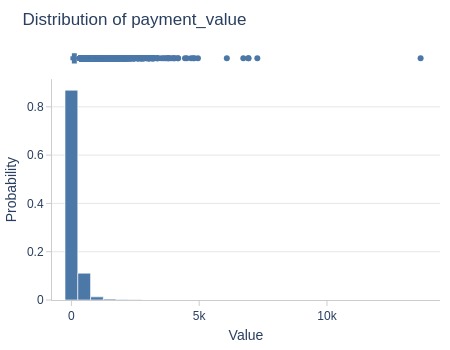
Key Observations:
There are 9 zero-value payments in payment_value.
The maximum payment is 13.66k. The median payment is 100.
The 13.66k payment is clearly an outlier.
Exploring Outliers#
df_payments.explore.anomalies_report(
anomaly_type='outlier'
)
| Count | Percent | |
|---|---|---|
| payment_sequential | 4526 | 4.4% |
| payment_installments | 343 | 0.3% |
| payment_value | 10390 | 10.0% |
| payment_sequential | payment_installments | payment_value | |
|---|---|---|---|
| payment_sequential | |||
| payment_installments | < under 1% / ^ under 1% | ||
| payment_value | < 19.7% / ^ 45.1% | < under 1% / ^ 21.9% |
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| payment_type | Voucher | 5775 | 4485 | 77.7% | 5.6% | 34.1% | 28.6% |
| order_id | payment_sequential | payment_type | payment_installments | payment_value | |
|---|---|---|---|---|---|
| 58222 | 242c9821e1036401ddc1d061ffcb034c | 1 | Credit Card | 1 | 11.57 |
| 16695 | 4b73f647e26dc08ed1ac8602a80ca3ee | 1 | Boleto | 1 | 741.44 |
| 53766 | 350508df3bad3da1cf8a3ac50f8c0406 | 1 | Credit Card | 8 | 565.91 |
| 32758 | cec3185bcfe3a9c60e73df2ae9bfa4ac | 3 | Voucher | 1 | 63.45 |
| 96404 | 7d0ed38550fa692c0dff9a4d0eddb8e7 | 1 | Credit Card | 1 | 8.39 |
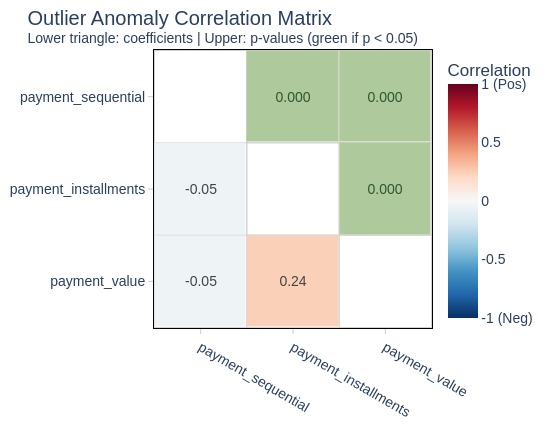
Let’s examine payments exceeding 5,000.
df_payments[df_payments.payment_value > 5_000]
| order_id | payment_sequential | payment_type | payment_installments | payment_value | |
|---|---|---|---|---|---|
| 34370 | 736e1922ae60d0d6a89247b851902527 | 1 | Boleto | 1 | 7,274.88 |
| 41419 | 0812eb902a67711a1cb742b3cdaa65ae | 1 | Credit Card | 8 | 6,929.31 |
| 49581 | fefacc66af859508bf1a7934eab1e97f | 1 | Boleto | 1 | 6,922.21 |
| 52107 | 03caa2c082116e1d31e67e9ae3700499 | 1 | Credit Card | 1 | 13,664.08 |
| 62409 | 2cc9089445046817a7539d90805e6e5a | 1 | Boleto | 1 | 6,081.54 |
| 85539 | f5136e38d1a14a4dbd87dff67da82701 | 1 | Boleto | 1 | 6,726.66 |
Let’s check for outliers in total order amounts per user.
(
df_customers.merge(df_orders, on='customer_id', how='left')
.merge(df_payments, on='order_id', how='left')
.groupby('customer_unique_id')['payment_value']
.sum()
.sort_values(ascending=False)
.to_frame()
.head(10)
)
| payment_value | |
|---|---|
| customer_unique_id | |
| 0a0a92112bd4c708ca5fde585afaa872 | 13,664.08 |
| 46450c74a0d8c5ca9395da1daac6c120 | 9,553.02 |
| da122df9eeddfedc1dc1f5349a1a690c | 7,571.63 |
| 763c8b1c9c68a0229c42c9fc6f662b93 | 7,274.88 |
| dc4802a71eae9be1dd28f5d788ceb526 | 6,929.31 |
| 459bef486812aa25204be022145caa62 | 6,922.21 |
| ff4159b92c40ebe40454e3e6a7c35ed6 | 6,726.66 |
| 4007669dec559734d6f53e029e360987 | 6,081.54 |
| 5d0a2980b292d049061542014e8960bf | 4,809.44 |
| eebb5dda148d3893cdaf5b5ca3040ccb | 4,764.34 |
Key Observations:
One user made orders totaling 13,664. This clearly stands out from the rest.
There are also several users who made purchases totaling 6,000 or more.
Let’s identify outliers using quantiles.
We’ll consider values outside the 5th and 95th percentiles as outliers.
df_payments.explore.detect_anomalies(
anomaly_type='outlier'
, method='quantile'
, threshold=0.05
)
| Count | Percent | |
|---|---|---|
| payment_sequential | 4526 | 4.36% |
| payment_installments | 343 | 0.33% |
| payment_value | 10390 | 10.00% |
Key Observations:
10% of payment values are outliers. This exceeds the typical norm (5%) but isn’t critical.
For payment installments, outliers account for less than 1%, which is normal.
payment_value
Let’s examine the distribution of payment value outliers over time.
tmp_outl = df_payments.merge(df_orders, on='order_id', how='left')
tmp_outl['payment_value'].explore.anomalies_over_time(
time_column='order_purchase_dt'
, anomaly_type='outlier'
, freq='D'
)
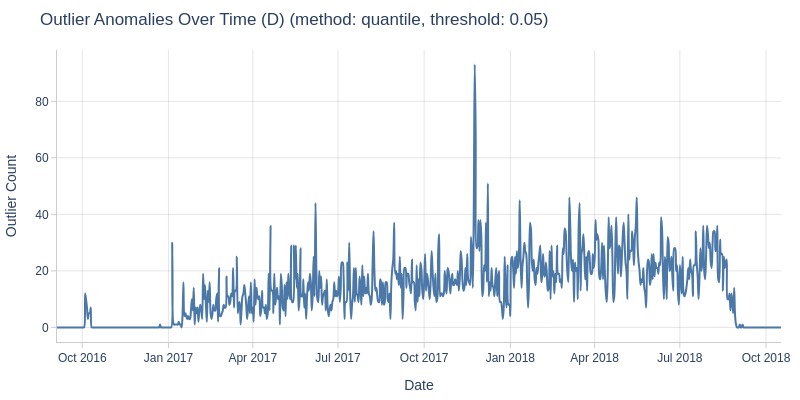
Key Observations:
Many payment outliers occurred between November 20-26, 2017, likely related to Black Friday.
del tmp_outl
Exploring Other Anomalies#
Let’s explore zero values.
df_payments.explore.anomalies_report(
anomaly_type='zero'
, sample_size=20
)
| Count | Percent | |
|---|---|---|
| payment_installments | 2 | 0.0% |
| payment_value | 9 | 0.0% |
| payment_installments | payment_value | |
|---|---|---|
| payment_installments | ||
| payment_value | 0 |
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| payment_type | Voucher | 5775 | 6 | 0.1% | 5.6% | 54.5% | 49.0% |
| payment_type | Not Defined | 3 | 3 | 100.0% | 0.0% | 27.3% | 27.3% |
| order_id | payment_sequential | payment_type | payment_installments | payment_value | |
|---|---|---|---|---|---|
| 77885 | fa65dad1b0e818e3ccc5cb0e39231352 | 13 | Voucher | 1 | 0.0 |
| 36822 | fa65dad1b0e818e3ccc5cb0e39231352 | 14 | Voucher | 1 | 0.0 |
| 62674 | 45ed6e85398a87c253db47c2d9f48216 | 3 | Voucher | 1 | 0.0 |
| 100766 | b23878b3e8eb4d25a158f57d96331b18 | 4 | Voucher | 1 | 0.0 |
| 43744 | 6ccb433e00daae1283ccc956189c82ae | 4 | Voucher | 1 | 0.0 |
| 79014 | 1a57108394169c0b47d8f876acc9ba2d | 2 | Credit Card | 0 | 129.94 |
| 46982 | 744bade1fcf9ff3f31d860ace076d422 | 2 | Credit Card | 0 | 58.69 |
| 51280 | 4637ca194b6387e2d538dc89b124b0ee | 1 | Not Defined | 1 | 0.0 |
| 94427 | c8c528189310eaa44a745b8d9d26908b | 1 | Not Defined | 1 | 0.0 |
| 57411 | 00b1cb0320190ca0daa2c88b35206009 | 1 | Not Defined | 1 | 0.0 |
| 19922 | 8bcbe01d44d147f901cd3192671144db | 4 | Voucher | 1 | 0.0 |
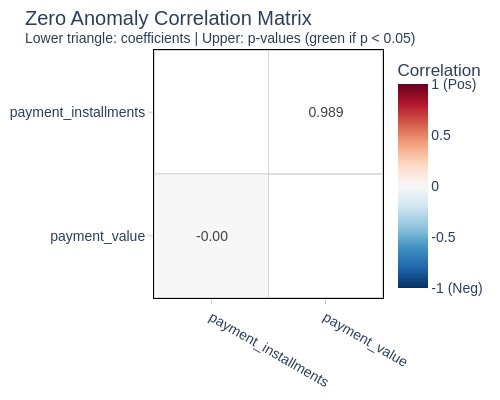
Key Observations:
Orders with zero payment amounts have either “voucher” or “not_defined” as their payment type.
Let’s examine zeros in each column separately.
Zeros in payment_installments
df_payments[df_payments.payment_installments == 0]
| order_id | payment_sequential | payment_type | payment_installments | payment_value | |
|---|---|---|---|---|---|
| 46982 | 744bade1fcf9ff3f31d860ace076d422 | 2 | Credit Card | 0 | 58.69 |
| 79014 | 1a57108394169c0b47d8f876acc9ba2d | 2 | Credit Card | 0 | 129.94 |
Since payment_sequential shows 2, there should have been another payment. Let’s examine these orders.
df_payments[df_payments.order_id == '744bade1fcf9ff3f31d860ace076d422']
| order_id | payment_sequential | payment_type | payment_installments | payment_value | |
|---|---|---|---|---|---|
| 46982 | 744bade1fcf9ff3f31d860ace076d422 | 2 | Credit Card | 0 | 58.69 |
df_payments[df_payments.order_id == '1a57108394169c0b47d8f876acc9ba2d']
| order_id | payment_sequential | payment_type | payment_installments | payment_value | |
|---|---|---|---|---|---|
| 79014 | 1a57108394169c0b47d8f876acc9ba2d | 2 | Credit Card | 0 | 129.94 |
Let’s check these orders in df_items.
df_items[df_items.order_id == '744bade1fcf9ff3f31d860ace076d422']
| order_id | order_item_id | product_id | seller_id | shipping_limit_dt | price | freight_value | |
|---|---|---|---|---|---|---|---|
| 51167 | 744bade1fcf9ff3f31d860ace076d422 | 1 | 0cf573090c66bb30ac5e53c82bdb0403 | 7202e2ba20579a9bd1acb29e61fe71f6 | 2018-04-26 12:31:06 | 45.90 | 12.79 |
df_items[df_items.order_id == '1a57108394169c0b47d8f876acc9ba2d']
| order_id | order_item_id | product_id | seller_id | shipping_limit_dt | price | freight_value | |
|---|---|---|---|---|---|---|---|
| 11589 | 1a57108394169c0b47d8f876acc9ba2d | 1 | db35a562fb6ba63e19fa42a15349dc04 | 282f23a9769b2690c5dda22e316f9941 | 2018-05-18 16:31:54 | 41.69 | 23.28 |
| 11590 | 1a57108394169c0b47d8f876acc9ba2d | 2 | db35a562fb6ba63e19fa42a15349dc04 | 282f23a9769b2690c5dda22e316f9941 | 2018-05-18 16:31:54 | 41.69 | 23.28 |
As we can see, the order wasn’t fully recorded in df_payments. The first payment is missing.
Zeros in payment_value
df_payments[df_payments.payment_value == 0]
| order_id | payment_sequential | payment_type | payment_installments | payment_value | |
|---|---|---|---|---|---|
| 19922 | 8bcbe01d44d147f901cd3192671144db | 4 | Voucher | 1 | 0.00 |
| 36822 | fa65dad1b0e818e3ccc5cb0e39231352 | 14 | Voucher | 1 | 0.00 |
| 43744 | 6ccb433e00daae1283ccc956189c82ae | 4 | Voucher | 1 | 0.00 |
| 51280 | 4637ca194b6387e2d538dc89b124b0ee | 1 | Not Defined | 1 | 0.00 |
| 57411 | 00b1cb0320190ca0daa2c88b35206009 | 1 | Not Defined | 1 | 0.00 |
| 62674 | 45ed6e85398a87c253db47c2d9f48216 | 3 | Voucher | 1 | 0.00 |
| 77885 | fa65dad1b0e818e3ccc5cb0e39231352 | 13 | Voucher | 1 | 0.00 |
| 94427 | c8c528189310eaa44a745b8d9d26908b | 1 | Not Defined | 1 | 0.00 |
| 100766 | b23878b3e8eb4d25a158f57d96331b18 | 4 | Voucher | 1 | 0.00 |
Let’s look at other payments for order fa65dad1b0e818e3ccc5cb0e39231352.
df_payments[df_payments.order_id == '8bcbe01d44d147f901cd3192671144db']
| order_id | payment_sequential | payment_type | payment_installments | payment_value | |
|---|---|---|---|---|---|
| 5163 | 8bcbe01d44d147f901cd3192671144db | 3 | Voucher | 1 | 6.25 |
| 19922 | 8bcbe01d44d147f901cd3192671144db | 4 | Voucher | 1 | 0.00 |
| 20963 | 8bcbe01d44d147f901cd3192671144db | 1 | Credit Card | 1 | 36.21 |
| 63762 | 8bcbe01d44d147f901cd3192671144db | 2 | Voucher | 1 | 31.70 |
Key Observations:
One payment was processed as zero, and it was the last payment.-
Moreover, all zero payments have either “voucher” or “not_defined” as their type.-
There might be some specific payment logic here.-
It’s better not to modify these zeros.
Table df_items#
Let’s look at the information about the dataframe.
df_items.explore.info()
| Summary | Column Types | |||
|---|---|---|---|---|
| Rows | 112.65k | Text | 2 | |
| Features | 7 | Categorical | 1 | |
| Missing cells | --- | Int | 1 | |
| Exact Duplicates | --- | Float | 2 | |
| Fuzzy Duplicates | --- | Datetime | 1 | |
| Memory Usage (Mb) | 30 | |||
Initial Column Analysis#
We will examine each column individually.
order_id
df_items['order_id'].explore.info(plot=False)
| Summary | Text Metrics | |||
|---|---|---|---|---|
| Total Values | 112.65k (100%) | Avg Word Count | 1.0 | |
| Missing Values | --- | Max Length (chars) | 32.0 | |
| Empty Strings | --- | Avg Length (chars) | 32.0 | |
| Distinct Values | 98.67k (88%) | Median Length (chars) | 32.0 | |
| Non-Duplicates | 88.86k (79%) | Min Length (chars) | 32.0 | |
| Exact Duplicates | 13.98k (12%) | Most Common Length | 32 (100.0%) | |
| Fuzzy Duplicates | 13.98k (12%) | Avg Digit Ratio | 0.62 | |
| Values with Duplicates | 9.80k (9%) | |||
| Memory Usage | 9 | |||
order_item_id
df_items['order_item_id'].explore.info()
| Summary | Percentiles | Detailed Stats | Value Counts | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Total | 112.65k (100%) | Max | 21 | Mean | 1.20 | 1 | 98.67k (88%) | |||
| Missing | --- | 99% | 4 | Trimmed Mean (10%) | 1.03 | 2 | 9.80k (9%) | |||
| Distinct | 21 (<1%) | 95% | 2 | Mode | 1 | 3 | 2.29k (2%) | |||
| Non-Duplicate | 1 (<1%) | 75% | 1 | Range | 20 | 4 | 965 (<1%) | |||
| Duplicates | 112.63k (99%) | 50% | 1 | IQR | 0 | 5 | 460 (<1%) | |||
| Dup. Values | 20 (<1%) | 25% | 1 | Std | 0.71 | 6 | 256 (<1%) | |||
| Zeros | --- | 5% | 1 | MAD | 0 | 7 | 58 (<1%) | |||
| Negative | --- | 1% | 1 | Kurt | 103.86 | 8 | 36 (<1%) | |||
| Memory Usage | 1 | Min | 1 | Skew | 7.58 | 9 | 28 (<1%) | |||
Key Observations:
The maximum quantity of items in a single order is 21.
product_id
df_items['product_id'].explore.info(plot=False)
| Summary | Text Metrics | |||
|---|---|---|---|---|
| Total Values | 112.65k (100%) | Avg Word Count | 1.0 | |
| Missing Values | --- | Max Length (chars) | 32.0 | |
| Empty Strings | --- | Avg Length (chars) | 32.0 | |
| Distinct Values | 32.95k (29%) | Median Length (chars) | 32.0 | |
| Non-Duplicates | 18.12k (16%) | Min Length (chars) | 32.0 | |
| Exact Duplicates | 79.70k (71%) | Most Common Length | 32 (100.0%) | |
| Fuzzy Duplicates | 79.70k (71%) | Avg Digit Ratio | 0.63 | |
| Values with Duplicates | 14.83k (13%) | |||
| Memory Usage | 9 | |||
seller_id
df_items['seller_id'].explore.info(plot=False)
| Summary | Text Metrics | Value Counts | |||||
|---|---|---|---|---|---|---|---|
| Total Values | 112.65k (100%) | Avg Word Count | 1.0 | 6560211a19b47992c3666cc44a7e94c0 | 2.03k (2%) | ||
| Missing Values | --- | Max Length (chars) | 32.0 | 4a3ca9315b744ce9f8e9374361493884 | 1.99k (2%) | ||
| Empty Strings | --- | Avg Length (chars) | 32.0 | 1f50f920176fa81dab994f9023523100 | 1.93k (2%) | ||
| Distinct Values | 3.10k (3%) | Median Length (chars) | 32.0 | cc419e0650a3c5ba77189a1882b7556a | 1.77k (2%) | ||
| Non-Duplicates | 509 (<1%) | Min Length (chars) | 32.0 | da8622b14eb17ae2831f4ac5b9dab84a | 1.55k (1%) | ||
| Exact Duplicates | 109.56k (97%) | Most Common Length | 32 (100.0%) | 955fee9216a65b617aa5c0531780ce60 | 1.50k (1%) | ||
| Fuzzy Duplicates | 109.56k (97%) | Avg Digit Ratio | 0.63 | 1025f0e2d44d7041d6cf58b6550e0bfa | 1.43k (1%) | ||
| Values with Duplicates | 2.59k (2%) | 7c67e1448b00f6e969d365cea6b010ab | 1.36k (1%) | ||||
| Memory Usage | 9 | ea8482cd71df3c1969d7b9473ff13abc | 1.20k (1%) | ||||
shipping_limit_dt
df_items['shipping_limit_dt'].explore.info()
| Summary | Data Quality Stats | Temporal Stats | |||||
|---|---|---|---|---|---|---|---|
| First date | 2016-09-19 | Values | 112.65k (100%) | Missing Years | 1 (20%) | ||
| Last date | 2020-04-09 | Zeros | --- | Missing Months | 18 (41%) | ||
| Avg Days Frequency | 0.01 | Missings | --- | Missing Weeks | 88 (47%) | ||
| Min Days Interval | 0 | Distinct | 93.32k (83%) | Missing Days | 744 (57%) | ||
| Max Days Interval | 502 | Duplicates | 19.33k (17%) | Weekend Percentage | 2.9% | ||
| Memory Usage | 1 | Dup. Values | 13.48k (12%) | Most Common Weekday | Thursday | ||
Key Observations:
In shipping_limit_dt: 20% missing years, 41% missing months, 47% missing weeks, 57% missing days.
The maximum date in shipping_limit_dt is 2020-04-09.
price
df_items['price'].explore.info()
| Summary | Percentiles | Detailed Stats | Value Counts | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Total | 112.65k (100%) | Max | 6.74k | Mean | 120.65 | 59.90 | 2.48k (2%) | |||
| Missing | --- | 99% | 890 | Trimmed Mean (10%) | 87.19 | 69.90 | 1.99k (2%) | |||
| Distinct | 5.97k (5%) | 95% | 349.90 | Mode | 59.90 | 49.90 | 1.95k (2%) | |||
| Non-Duplicate | 2.34k (2%) | 75% | 134.90 | Range | 6.73k | 89.90 | 1.55k (1%) | |||
| Duplicates | 106.68k (95%) | 50% | 74.99 | IQR | 95 | 99.90 | 1.43k (1%) | |||
| Dup. Values | 3.63k (3%) | 25% | 39.90 | Std | 183.63 | 39.90 | 1.34k (1%) | |||
| Zeros | --- | 5% | 17 | MAD | 62.40 | 29.90 | 1.32k (1%) | |||
| Negative | --- | 1% | 9.99 | Kurt | 120.83 | 79.90 | 1.21k (1%) | |||
| Memory Usage | 1 | Min | 0.85 | Skew | 7.92 | 19.90 | 1.20k (1%) | |||
Key Observations:
Most products are priced between 39.9 and 134.9.
The median product price is 74.99.
freight_value
df_items['freight_value'].explore.info()
| Summary | Percentiles | Detailed Stats | Value Counts | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Total | 112.65k (100%) | Max | 409.68 | Mean | 19.99 | 15.10 | 3.71k (3%) | |||
| Missing | --- | 99% | 84.52 | Trimmed Mean (10%) | 17.22 | 7.78 | 2.26k (2%) | |||
| Distinct | 7.00k (6%) | 95% | 45.12 | Mode | 15.10 | 14.10 | 1.88k (2%) | |||
| Non-Duplicate | 2.08k (2%) | 75% | 21.15 | Range | 409.68 | 11.85 | 1.85k (2%) | |||
| Duplicates | 105.65k (94%) | 50% | 16.26 | IQR | 8.07 | 18.23 | 1.57k (1%) | |||
| Dup. Values | 4.92k (4%) | 25% | 13.08 | Std | 15.81 | 7.39 | 1.52k (1%) | |||
| Zeros | 383 (<1%) | 5% | 7.78 | MAD | 5.35 | 16.11 | 1.15k (1%) | |||
| Negative | --- | 1% | 4.42 | Kurt | 59.79 | 15.23 | 1.01k (<1%) | |||
| Memory Usage | 1 | Min | 0 | Skew | 5.64 | 8.72 | 921 (<1%) | |||
Key Observations:
There are zero values in freight_value.
Exploring Outliers#
df_items.explore.anomalies_report(
anomaly_type='outlier'
, exclude_columns='seller_id'
)
| Count | Percent | |
|---|---|---|
| order_item_id | 4181 | 3.7% |
| price | 11076 | 9.8% |
| freight_value | 10239 | 9.1% |
| order_item_id | price | freight_value | |
|---|---|---|---|
| order_item_id | |||
| price | < 5.3% / ^ 14.0% | ||
| freight_value | < 6.5% / ^ 16.0% | < 23.2% / ^ 21.4% |
| order_id | order_item_id | product_id | seller_id | shipping_limit_dt | price | freight_value | |
|---|---|---|---|---|---|---|---|
| 2311 | 0540bf9189ef17aab470c4942f760e78 | 3 | 44d958961868395bfe852e70d48081f4 | 1ca7077d890b907f89be8c954a02686a | 2018-03-21 22:28:08 | 45.99 | 7.39 |
| 1074 | 027e4543814c3b3509bbe890c569a841 | 1 | e940125d0a3c309f58f41cd21e39af06 | 6039e27294dc75811c0d8a39069f52c0 | 2018-04-20 15:10:30 | 329.0 | 54.12 |
| 7207 | 1052fc490084f258baac0395a94fa58d | 1 | 6047d1b3d3841a528e860a939daa2035 | 11bfa66332777660bd0640ee84d47006 | 2018-05-28 15:55:25 | 15.0 | 12.79 |
| 158 | 006127b8b9a1681a982313ed7129c3c0 | 1 | f819f0c84a64f02d3a5606ca95edd272 | 7d13fca15225358621be4086e1eb0964 | 2018-03-15 02:30:23 | 540.0 | 16.22 |
| 32118 | 48c5decbdf6fcf15cdf335a81ef879c0 | 1 | bc3d15dd90a6794ea7710f1642aae319 | 6b89abe95848c850399130d149a39b63 | 2018-04-12 21:29:27 | 145.9 | 55.28 |
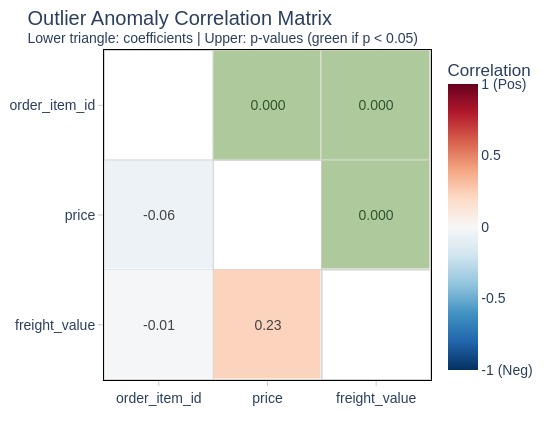
Key Observations:
About 10% outliers exist in product prices and shipping costs. This exceeds the typical norm (usually 5%) but isn’t critical.
Product Sales Inconsistencies#
Checking if any products in the items table have multiple sellers:
df_items.groupby('product_id')['seller_id'].nunique().sort_values(ascending=False).head(10).to_frame('sellers_cnt')
| sellers_cnt | |
|---|---|
| product_id | |
| d285360f29ac7fd97640bf0baef03de0 | 8 |
| 69455f41626a745aea9ee9164cb9eafd | 8 |
| 4298b7e67dc399c200662b569563a2b2 | 7 |
| 36f60d45225e60c7da4558b070ce4b60 | 7 |
| 656e0eca68dcecf6a31b8ececfabe3e8 | 7 |
| dbb67791e405873b259e4656bf971246 | 6 |
| 7dd3fec3502f7ef333da2a73e00db394 | 5 |
| 461f43be3bdf8844e65b62d9ac2c7a5a | 5 |
| d04e48982547095af81c231c3d581cb6 | 5 |
| e0d64dcfaa3b6db5c54ca298ae101d05 | 5 |
Key Observations:
Some product IDs were sold by different sellers.
df_items.groupby('product_id')['seller_id'].nunique().value_counts().to_frame('products_cnt')
| products_cnt | |
|---|---|
| seller_id | |
| 1 | 31726 |
| 2 | 1030 |
| 3 | 147 |
| 4 | 32 |
| 5 | 10 |
| 7 | 3 |
| 8 | 2 |
| 6 | 1 |
Key Observations:
Over 1,000 products have more than 2 sellers.
Examining product d285360f29ac7fd97640bf0baef03de0
df_products[lambda x: x.product_id == 'd285360f29ac7fd97640bf0baef03de0']
| product_id | product_category_name | product_name_lenght | product_description_lenght | product_photos_qty | product_weight_g | product_length_cm | product_height_cm | product_width_cm | |
|---|---|---|---|---|---|---|---|---|---|
| 24426 | d285360f29ac7fd97640bf0baef03de0 | relogios_presentes | 46.00 | 501.00 | 4.00 | 363.00 | 18.00 | 13.00 | 13.00 |
tmp_df_res = (df_items[lambda x: x.product_id == 'd285360f29ac7fd97640bf0baef03de0']
[['shipping_limit_dt', 'price', 'freight_value', 'seller_id']]
.merge(df_sellers, on='seller_id', how='left')
)
tmp_df_res.seller_id.unique()
array(['2eb70248d66e0e3ef83659f71b244378',
'4869f7a5dfa277a7dca6462dcf3b52b2',
'd650b663c3b5f6fb392b6326366efa9a',
'b33e7c55446eabf8fe1a42d037ac7d6d',
'fa1c13f2614d7b5c4749cbc52fecda94',
'7d13fca15225358621be4086e1eb0964',
'7e93a43ef30c4f03f38b393420bc753a',
'01ed254b9ff8407dfb9d99ba1e17d923'], dtype=object)
tmp_df_res.seller_state.unique()
['SP']
Categories (23, object): ['AC', 'AM', 'BA', 'CE', ..., 'RS', 'SC', 'SE', 'SP']
tmp_df_res.seller_city.unique()
['Campinas', 'Guariba', 'Cotia', 'Pradopolis', 'Sumare', 'Ribeirao Preto', 'Barueri', 'Mogi Das Cruzes']
Categories (605, object): ['04482255', 'Abadia De Goias', 'Afonso Claudio', 'Aguas Claras Df', ..., 'Votorantim', 'Votuporanga', 'Xanxere', 'Xaxim']
Key Observations:
Sellers are located in different cities.
This might not be an anomaly - different sellers could legitimately sell identical products with matching IDs.
Checking if any products were sold across different seller states
(df_items.merge(df_sellers, on='seller_id', how='left')
.groupby('product_id')['seller_state'].nunique().sort_values(ascending=False).head(10).to_frame('states_cnt')
)
| states_cnt | |
|---|---|
| product_id | |
| 46292acbc08d49b95138891146f7287b | 4 |
| da051bd767b7457572d55aba23fd846a | 3 |
| 64315bd8c0c47303179dd2e25b579d00 | 3 |
| 04df667e73ca2fab4b9a97c86466b699 | 3 |
| ab328a14d2698a726fe1ed2695f5f43c | 3 |
| b5c9804aab5c4cfd555ebfbc609de43d | 3 |
| 09982590713913e225d3ce5ccb670688 | 3 |
| 8215db96a612d69839c27866feabf350 | 3 |
| 027cdd14a677a5834bc67a9789db5021 | 3 |
| d41d8cd98f00b204e9800998ecf8427e | 3 |
Key Observations:
Some products were sold by sellers in different states.
Verifying city consistency for customer_id in the customers table (as this is our join key)
(df_customers.groupby('customer_id')[['customer_state', 'customer_city']].nunique() > 1).sum()
customer_state 0
customer_city 0
dtype: int64
All is well…
Date Inconsistencies#
shipping_limit_dt
Analyzing anomalous shipping_limit_dt values
df_items[df_items.shipping_limit_dt > '2018-12-31'].merge(df_orders, on='order_id', how='left')
| order_id | order_item_id | product_id | seller_id | shipping_limit_dt | price | freight_value | customer_id | order_status | order_purchase_dt | order_approved_dt | order_delivered_carrier_dt | order_delivered_customer_dt | order_estimated_delivery_dt | tmp_avg_reviews_score | tmp_payment_types | tmp_product_categories | tmp_customer_state | tmp_order_purchase_month | tmp_order_purchase_weekday | tmp_purchase_time_of_day | tmp_is_delayed | tmp_is_delivered | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 13bdf405f961a6deec817d817f5c6624 | 1 | 96ea060e41bdecc64e2de00b97068975 | 7a241947449cc45dbfda4f9d0798d9d0 | 2020-02-05 03:30:51 | 69.99 | 14.66 | b279a1d441c73c1974d7a63618855aa0 | Canceled | 2017-03-16 02:30:51 | 2017-03-16 02:30:51 | NaT | NaT | 2017-08-08 | 1 | Boleto | utilidades_domesticas | RJ | March | Thursday | Night | Missing delivery dt | Not Delivered |
| 1 | 9c94a4ea2f7876660fa6f1b59b69c8e6 | 1 | 282b126b2354516c5f400154398f616d | 7a241947449cc45dbfda4f9d0798d9d0 | 2020-02-03 20:23:22 | 75.99 | 14.70 | 22e922696a7d1ab9a19c6b702fedc387 | Shipped | 2017-03-14 19:23:22 | 2017-03-14 19:23:22 | 2017-03-16 14:31:15 | NaT | 2017-08-04 | 1 | Boleto | utilidades_domesticas | DF | March | Tuesday | Evening | Missing delivery dt | Not Delivered |
| 2 | c2bb89b5c1dd978d507284be78a04cb2 | 1 | 87b92e06b320e803d334ac23966c80b1 | 7a241947449cc45dbfda4f9d0798d9d0 | 2020-04-09 22:35:08 | 99.99 | 61.44 | 6357fffb5704244d552615bbfcea1442 | Delivered | 2017-05-23 22:28:36 | 2017-05-24 22:35:08 | 2017-05-29 02:03:28 | 2017-06-09 13:35:54 | 2017-10-11 | 5 | Credit Card | utilidades_domesticas | SP | May | Tuesday | Evening | Not Delayed | Delivered |
| 3 | c2bb89b5c1dd978d507284be78a04cb2 | 2 | 87b92e06b320e803d334ac23966c80b1 | 7a241947449cc45dbfda4f9d0798d9d0 | 2020-04-09 22:35:08 | 99.99 | 61.44 | 6357fffb5704244d552615bbfcea1442 | Delivered | 2017-05-23 22:28:36 | 2017-05-24 22:35:08 | 2017-05-29 02:03:28 | 2017-06-09 13:35:54 | 2017-10-11 | 5 | Credit Card | utilidades_domesticas | SP | May | Tuesday | Evening | Not Delayed | Delivered |
Key Observations:
Found 4 orders with abnormally large shipping_limit_dt values, despite having normal estimated delivery times.
Exploring Other Anomalies#
Examining zero values
tmp_zeros = df_items.explore.detect_anomalies(
anomaly_type='zero'
, return_mode='by_column'
)['freight_value']
| Count | Percent | |
|---|---|---|
| freight_value | 383 | 0.34% |
Key Observations:
Zero freight values may indicate free shipping.
Examing rows
tmp_zeros.sample(5)
| order_id | order_item_id | product_id | seller_id | shipping_limit_dt | price | freight_value | |
|---|---|---|---|---|---|---|---|
| 58418 | 84f89b4f4b956843277c6b990bd06b2f | 5 | 53b36df67ebb7c41585e8d54d6772e08 | 7d13fca15225358621be4086e1eb0964 | 2018-05-01 23:35:09 | 99.90 | 0.00 |
| 37202 | 546fb5e88f96553369c04bd920b9becf | 1 | 422879e10f46682990de24d770e7f83d | 1f50f920176fa81dab994f9023523100 | 2018-05-07 02:15:24 | 53.90 | 0.00 |
| 97216 | dc8c9fb3edc11055d2fa5198744dff2b | 1 | 7a10781637204d8d10485c71a6108a2e | 4869f7a5dfa277a7dca6462dcf3b52b2 | 2018-05-15 02:54:17 | 199.00 | 0.00 |
| 58271 | 84a649c5b7af51c49e0041fb5e3486d8 | 1 | 53b36df67ebb7c41585e8d54d6772e08 | 7d13fca15225358621be4086e1eb0964 | 2018-05-14 07:55:13 | 99.90 | 0.00 |
| 40807 | 5ced629739c2b3247b4fcd4f0498c3bb | 1 | 53b36df67ebb7c41585e8d54d6772e08 | 4869f7a5dfa277a7dca6462dcf3b52b2 | 2018-04-26 19:30:44 | 106.90 | 0.00 |
Reviewing zero-value over time
df_items.freight_value.explore.anomalies_over_time(
time_column='shipping_limit_dt'
, anomaly_type='zero'
, freq='W'
)
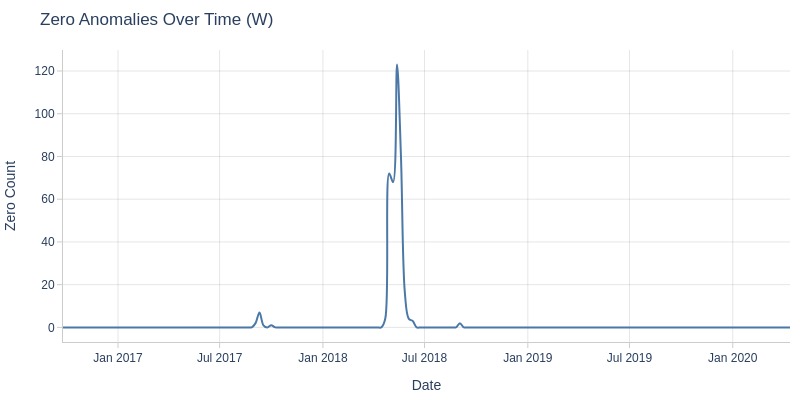
Key Observations:
Most zero shipping costs occurred between April-July 2018.
Table df_customers#
Let’s look at the information about the dataframe.
df_customers.explore.info()
| Summary | Column Types | |||
|---|---|---|---|---|
| Rows | 99.44k | Text | 2 | |
| Features | 5 | Categorical | 2 | |
| Missing cells | --- | Int | 1 | |
| Exact Duplicates | --- | Float | 0 | |
| Fuzzy Duplicates | --- | Datetime | 0 | |
| Memory Usage (Mb) | 17 | |||
Initial Column Analysis#
We will examine each column individually.
customer_id
df_customers['customer_id'].explore.info(plot=False)
| Summary | Text Metrics | |||
|---|---|---|---|---|
| Total Values | 99.44k (100%) | Avg Word Count | 1.0 | |
| Missing Values | --- | Max Length (chars) | 32.0 | |
| Empty Strings | --- | Avg Length (chars) | 32.0 | |
| Distinct Values | 99.44k (100%) | Median Length (chars) | 32.0 | |
| Non-Duplicates | 99.44k (100%) | Min Length (chars) | 32.0 | |
| Exact Duplicates | --- | Most Common Length | 32 (100.0%) | |
| Fuzzy Duplicates | --- | Avg Digit Ratio | 0.62 | |
| Values with Duplicates | --- | |||
| Memory Usage | 8 | |||
customer_unique_id
df_customers['customer_unique_id'].explore.info(plot=False)
| Summary | Text Metrics | |||
|---|---|---|---|---|
| Total Values | 99.44k (100%) | Avg Word Count | 1.0 | |
| Missing Values | --- | Max Length (chars) | 32.0 | |
| Empty Strings | --- | Avg Length (chars) | 32.0 | |
| Distinct Values | 96.10k (97%) | Median Length (chars) | 32.0 | |
| Non-Duplicates | 93.10k (94%) | Min Length (chars) | 32.0 | |
| Exact Duplicates | 3.35k (3%) | Most Common Length | 32 (100.0%) | |
| Fuzzy Duplicates | 3.35k (3%) | Avg Digit Ratio | 0.63 | |
| Values with Duplicates | 3.00k (3%) | |||
| Memory Usage | 8 | |||
Key Observations:
customer_unique_id has 3% duplicates - acceptable as this field doesn’t require uniqueness in this table.
customer_zip_code_prefix
df_customers['customer_zip_code_prefix'].explore.info(plot=False)
| Summary | Percentiles | Detailed Stats | Value Counts | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Total | 99.44k (100%) | Max | 99.99k | Mean | 35.14k | 22790 | 142 (<1%) | |||
| Missing | --- | 99% | 97.51k | Trimmed Mean (10%) | 32.04k | 24220 | 124 (<1%) | |||
| Distinct | 14.99k (15%) | 95% | 90.55k | Mode | 22790 | 22793 | 121 (<1%) | |||
| Non-Duplicate | 3.01k (3%) | 75% | 58.90k | Range | 98987 | 24230 | 117 (<1%) | |||
| Duplicates | 84.45k (85%) | 50% | 24.42k | IQR | 47.55k | 22775 | 110 (<1%) | |||
| Dup. Values | 11.98k (12%) | 25% | 11.35k | Std | 29.80k | 29101 | 101 (<1%) | |||
| Zeros | --- | 5% | 3.31k | MAD | 24.29k | 13212 | 95 (<1%) | |||
| Negative | --- | 1% | 1.33k | Kurt | -0.79 | 35162 | 93 (<1%) | |||
| Memory Usage | 1 | Min | 1.00k | Skew | 0.78 | 22631 | 89 (<1%) | |||
customer_city
df_customers['customer_city'].explore.info()
| Summary | Text Metrics | Value Counts | |||||
|---|---|---|---|---|---|---|---|
| Total Values | 99.44k (100%) | Avg Word Count | 1.8 | Sao Paulo | 15.54k (16%) | ||
| Missing Values | --- | Max Length (chars) | 32.0 | Rio De Janeiro | 6.88k (7%) | ||
| Empty Strings | --- | Avg Length (chars) | 10.3 | Belo Horizonte | 2.77k (3%) | ||
| Distinct Values | 4.11k (4%) | Median Length (chars) | 9.0 | Brasilia | 2.13k (2%) | ||
| Non-Duplicates | 1.14k (1%) | Min Length (chars) | 3.0 | Curitiba | 1.52k (2%) | ||
| Exact Duplicates | 95.33k (96%) | Most Common Length | 9 (22.4%) | Campinas | 1.44k (1%) | ||
| Fuzzy Duplicates | 95.33k (96%) | Avg Digit Ratio | 0.00 | Porto Alegre | 1.38k (1%) | ||
| Values with Duplicates | 2.97k (3%) | Salvador | 1.25k (1%) | ||||
| Memory Usage | 1 | Guarulhos | 1.19k (1%) | ||||
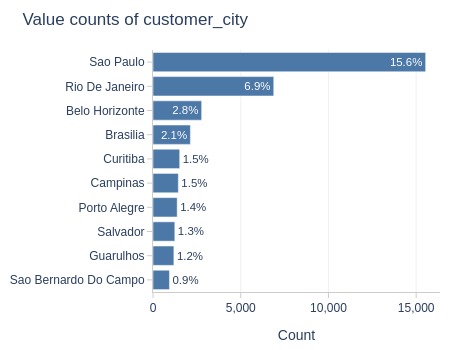
Key Observations:
Most customers are from São Paulo city (16%).
customer_state
df_customers['customer_state'].explore.info()
| Summary | Text Metrics | Value Counts | |||||
|---|---|---|---|---|---|---|---|
| Total Values | 99.44k (100%) | Avg Word Count | 1.0 | SP | 41.75k (42%) | ||
| Missing Values | --- | Max Length (chars) | 2.0 | RJ | 12.85k (13%) | ||
| Empty Strings | --- | Avg Length (chars) | 2.0 | MG | 11.63k (12%) | ||
| Distinct Values | 27 (<1%) | Median Length (chars) | 2.0 | RS | 5.47k (5%) | ||
| Non-Duplicates | --- | Min Length (chars) | 2.0 | PR | 5.04k (5%) | ||
| Exact Duplicates | 99.41k (99%) | Most Common Length | 2 (100.0%) | SC | 3.64k (4%) | ||
| Fuzzy Duplicates | 99.41k (99%) | Avg Digit Ratio | 0.00 | BA | 3.38k (3%) | ||
| Values with Duplicates | 27 (<1%) | DF | 2.14k (2%) | ||||
| Memory Usage | <1 Mb | ES | 2.03k (2%) | ||||
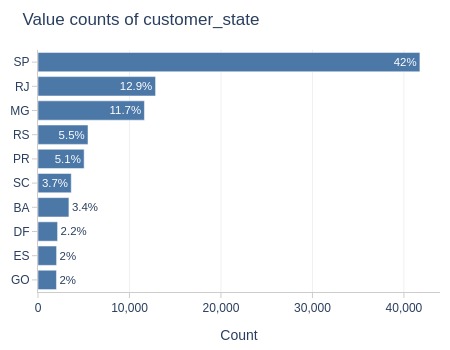
Key Observations:
Most customers are from SP state (42%).
Table df_reviews#
Let’s look at the information about the dataframe.
df_reviews.explore.info()
| Summary | Column Types | |||
|---|---|---|---|---|
| Rows | 100.00k | Text | 3 | |
| Features | 7 | Categorical | 1 | |
| Missing cells | 146.56k (21%) | Int | 1 | |
| Exact Duplicates | --- | Float | 0 | |
| Fuzzy Duplicates | --- | Datetime | 2 | |
| Memory Usage (Mb) | 28 | |||
Initial Column Analysis#
We will examine each column individually.
review_id
df_reviews['review_id'].explore.info(plot=False)
| Summary | Text Metrics | |||
|---|---|---|---|---|
| Total Values | 100.00k (100%) | Avg Word Count | 1.0 | |
| Missing Values | --- | Max Length (chars) | 32.0 | |
| Empty Strings | --- | Avg Length (chars) | 32.0 | |
| Distinct Values | 99.17k (99%) | Median Length (chars) | 32.0 | |
| Non-Duplicates | 98.37k (98%) | Min Length (chars) | 32.0 | |
| Exact Duplicates | 827 (<1%) | Most Common Length | 32 (100.0%) | |
| Fuzzy Duplicates | 827 (<1%) | Avg Digit Ratio | 0.62 | |
| Values with Duplicates | 802 (<1%) | |||
| Memory Usage | 8 | |||
Key Observations:
review_id contains 827 duplicates.
order_id
df_reviews['order_id'].explore.info(plot=False)
| Summary | Text Metrics | |||
|---|---|---|---|---|
| Total Values | 100.00k (100%) | Avg Word Count | 1.0 | |
| Missing Values | --- | Max Length (chars) | 32.0 | |
| Empty Strings | --- | Avg Length (chars) | 32.0 | |
| Distinct Values | 99.44k (99%) | Median Length (chars) | 32.0 | |
| Non-Duplicates | 98.89k (99%) | Min Length (chars) | 32.0 | |
| Exact Duplicates | 559 (<1%) | Most Common Length | 32 (100.0%) | |
| Fuzzy Duplicates | 559 (<1%) | Avg Digit Ratio | 0.63 | |
| Values with Duplicates | 555 (<1%) | |||
| Memory Usage | 8 | |||
Key Observations:
order_reviews table has 559 duplicate order_ids.
review_score
df_reviews['review_score'].explore.info(column_type='categorical')
| Summary | Text Metrics | Value Counts | |||||
|---|---|---|---|---|---|---|---|
| Total Values | 100.00k (100%) | Avg Word Count | 1.0 | 5 | 57.42k (57%) | ||
| Missing Values | --- | Max Length (chars) | 1.0 | 4 | 19.20k (19%) | ||
| Empty Strings | --- | Avg Length (chars) | 1.0 | 1 | 11.86k (12%) | ||
| Distinct Values | 5 (<1%) | Median Length (chars) | 1.0 | 3 | 8.29k (8%) | ||
| Non-Duplicates | --- | Min Length (chars) | 1.0 | 2 | 3.23k (3%) | ||
| Exact Duplicates | 100.00k (99%) | Most Common Length | 1 (100.0%) | ||||
| Fuzzy Duplicates | 100.00k (99%) | Avg Digit Ratio | 1.00 | ||||
| Values with Duplicates | 5 (<1%) | ||||||
| Memory Usage | 5 | ||||||
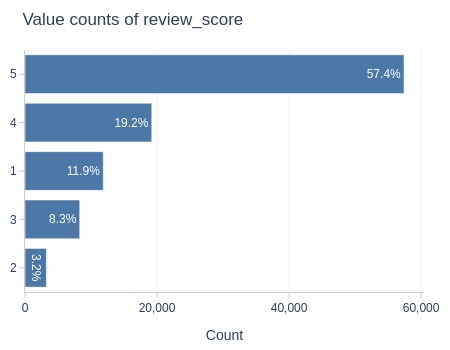
Key Observations:
Over half of reviews (57%) give maximum 5-star ratings.
review_comment_title
df_reviews['review_comment_title'].explore.info(column_type='text')
| Summary | Text Metrics | |||
|---|---|---|---|---|
| Total Values | 100.00k (100%) | Avg Word Count | 2.1 | |
| Missing Values | 88.29k (88%) | Max Length (chars) | 43.0 | |
| Empty Strings | 30 (<1%) | Avg Length (chars) | 12.3 | |
| Distinct Values | 2.98k (3%) | Median Length (chars) | 11.0 | |
| Non-Duplicates | 2.39k (2%) | Min Length (chars) | 0.0 | |
| Exact Duplicates | 97.02k (97%) | Most Common Length | 9 (1.9%) | |
| Fuzzy Duplicates | 97.03k (97%) | Avg Digit Ratio | 0.03 | |
| Values with Duplicates | 585 (<1%) | |||
| Memory Usage | 5 | |||

Key Observations:
88% of review titles are missing.
Most common review title (8%) is ‘recomendo’.
review_comment_message
df_reviews['review_comment_message'].explore.info()
| Summary | Text Metrics | |||
|---|---|---|---|---|
| Total Values | 100.00k (100%) | Avg Word Count | 13.3 | |
| Missing Values | 58.27k (58%) | Max Length (chars) | 347.0 | |
| Empty Strings | 114 (<1%) | Avg Length (chars) | 71.3 | |
| Distinct Values | 33.49k (33%) | Median Length (chars) | 54.0 | |
| Non-Duplicates | 32.03k (32%) | Min Length (chars) | 0.0 | |
| Exact Duplicates | 66.51k (67%) | Most Common Length | 9 (1.4%) | |
| Fuzzy Duplicates | 66.53k (67%) | Avg Digit Ratio | 0.01 | |
| Values with Duplicates | 1.46k (1%) | |||
| Memory Usage | 8 | |||
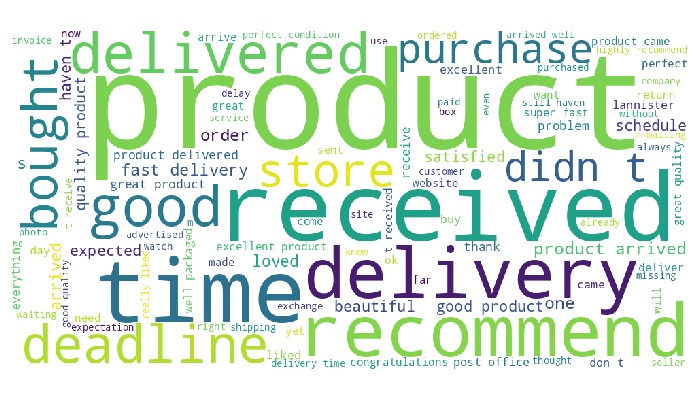
Key Observations:
58% of orders lack review messages.
Only 36% of review comments are unique.
Most frequent comment (1%) contains “muito bom”.
review_creation_dt
df_reviews['review_creation_dt'].explore.info()
| Summary | Data Quality Stats | Temporal Stats | |||||
|---|---|---|---|---|---|---|---|
| First date | 2016-10-02 | Values | 100.00k (100%) | Missing Years | --- | ||
| Last date | 2018-08-31 | Zeros | --- | Missing Months | --- | ||
| Avg Days Frequency | 0.01 | Missings | --- | Missing Weeks | --- | ||
| Min Days Interval | 0 | Distinct | 637 (<1%) | Missing Days | 62 (9%) | ||
| Max Days Interval | 9 | Duplicates | 99.36k (99%) | Weekend Percentage | 24.5% | ||
| Memory Usage | 1 | Dup. Values | 608 (<1%) | Most Common Weekday | Wednesday | ||
Key Observations:
review_creation_dt has 9% missing days.
review_answer_dt
df_reviews['review_answer_dt'].explore.info()
| Summary | Data Quality Stats | Temporal Stats | |||||
|---|---|---|---|---|---|---|---|
| First date | 2016-10-07 | Values | 100.00k (100%) | Missing Years | --- | ||
| Last date | 2018-10-29 | Zeros | --- | Missing Months | --- | ||
| Avg Days Frequency | 0.01 | Missings | --- | Missing Weeks | --- | ||
| Min Days Interval | 0 | Distinct | 99.01k (99%) | Missing Days | 37 (5%) | ||
| Max Days Interval | 6 | Duplicates | 990 (<1%) | Weekend Percentage | 25.5% | ||
| Memory Usage | 1 | Dup. Values | 959 (<1%) | Most Common Weekday | Friday | ||
Key Observations:
review_answer_dt has 5% missing days.
Exploring Missing Values#
Checking columns with missing values:
df_reviews.explore.anomalies_report(
anomaly_type='missing'
, pct_diff_threshold=10
, show_by_categories=False
, show_sample=False
, width=600
)
| Count | Percent | |
|---|---|---|
| review_comment_title | 88289 | 88.3% |
| review_comment_message | 58275 | 58.3% |
| review_comment_title | review_comment_message | |
|---|---|---|
| review_comment_title | ||
| review_comment_message | < 97.0% / ^ 64.0% |
Key Observations:
Missing review titles/messages aren’t anomalies - they were simply not provided.
Exploring Duplicates#
Examining duplicates in order_id and review_id:
df_reviews[['order_id', 'review_id']].duplicated().sum()
np.int64(0)
No instances where both order_id and review_id are duplicated simultaneously.
Theoretical possibility: one order could have multiple reviews, but multiple orders sharing one review is unusual.
Analyzing order_id and review_id duplicates separately
review_id
tmp_dupl = df_reviews[df_reviews.review_id.duplicated()]
Reviewing review_id duplicate distribution over time
df_reviews.review_id.explore.anomalies_over_time(
time_column='review_creation_dt'
, anomaly_type='duplicate'
, freq='W'
)
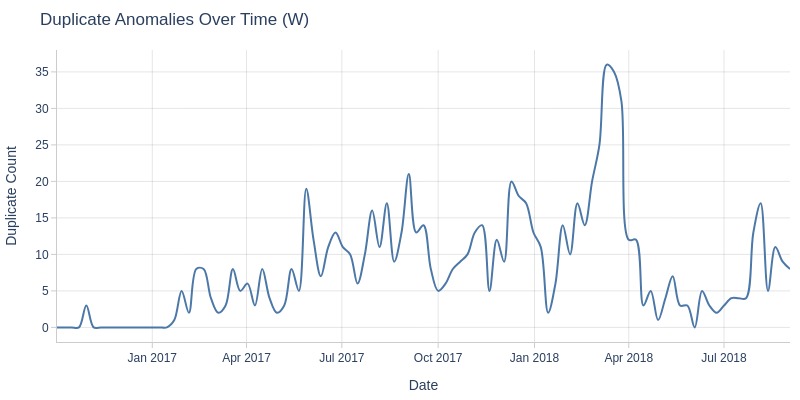
Key Observations:
March 2018 saw a significant spike in duplicate review_ids (one review applied to multiple orders).
Checking for duplicates with different customers
tmp_dupl = (
tmp_dupl.merge(df_orders, on='order_id', how='left')
.merge(df_customers, on='customer_id', how='left')
)
tmp_dupl.groupby('review_id')['customer_unique_id'].nunique().value_counts()
customer_unique_id
1 802
Name: count, dtype: int64
Key Observations:
No duplicates with different customers.
Examining product quantities in these orders
(
tmp_dupl.merge(df_items, on='order_id', how='left')
.groupby('order_id')['product_id']
.nunique()
.value_counts()
)
product_id
1 700
2 41
0 33
3 5
4 3
Name: count, dtype: int64
Key Observations:
Most orders contain one product.
Some orders show no products (due to missing records in the items table).
tmp_dupl = (tmp_dupl.merge(df_payments, on='order_id', how='left')
.merge(df_items, on='order_id', how='left')
)
tmp_dupl = tmp_dupl[['review_id', 'order_id', 'review_score', 'review_comment_title', 'review_comment_message'
, 'review_creation_dt', 'order_delivered_customer_dt', 'order_status', 'payment_type'
, 'payment_value', 'product_id', 'price', 'freight_value']].sort_values('review_id').drop_duplicates()
tmp_dupl.head()
| review_id | order_id | review_score | review_comment_title | review_comment_message | review_creation_dt | order_delivered_customer_dt | order_status | payment_type | payment_value | product_id | price | freight_value | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 214 | 00130cbe1f9d422698c812ed8ded1919 | dfcdfc43867d1c1381bfaf62d6b9c195 | 1 | NaN | the original hp 60xl cartridge is not recogniz... | 2018-03-07 | 2018-02-26 18:18:45 | Delivered | Credit Card | 115.05 | 36f60d45225e60c7da4558b070ce4b60 | 89.15 | 25.90 |
| 827 | 0115633a9c298b6a98bcbe4eee75345f | 78a4201f58af3463bdab842eea4bc801 | 5 | NaN | NaN | 2017-09-21 | 2017-09-20 22:24:03 | Delivered | Credit Card | 325.41 | 7814c273ab16783d73a9863ebfa8b141 | 229.00 | 96.41 |
| 865 | 0174caf0ee5964646040cd94e15ac95e | f93a732712407c02dce5dd5088d0f47b | 1 | NaN | product delivered in the supplier s packaging ... | 2018-03-07 | 2018-03-06 21:39:06 | Delivered | Credit Card | 73.43 | aed5efaf7a7554165f61fd016846916f | 61.50 | 11.93 |
| 979 | 017808d29fd1f942d97e50184dfb4c13 | b1461c8882153b5fe68307c46a506e39 | 5 | NaN | NaN | 2018-03-02 | 2018-03-01 17:52:00 | Delivered | Credit Card | 45.17 | d5d9e871a07a5ba84cef719ad92f0ab9 | 35.90 | 9.27 |
| 930 | 0254bd905dc677a6078990aad3331a36 | 331b367bdd766f3d1cf518777317b5d9 | 1 | NaN | the order consists of 2 products and so far i ... | 2017-09-09 | 2017-09-14 20:22:47 | Delivered | Credit Card | 283.20 | 7814c273ab16783d73a9863ebfa8b141 | 229.00 | 54.20 |
Comparing duplicate values across columns (replacing missing values with na):
(tmp_dupl.fillna({'review_comment_message': '__na__'})
.groupby('review_id')
[['review_comment_message', 'review_score', 'order_status', 'payment_type', 'payment_value', 'product_id', 'price']]
.nunique()
.apply(pd.Series.value_counts)
)
| review_comment_message | review_score | order_status | payment_type | payment_value | product_id | price | |
|---|---|---|---|---|---|---|---|
| 0 | NaN | NaN | NaN | NaN | NaN | 26.00 | 26.00 |
| 1 | 802.00 | 802.00 | 796.00 | 784.00 | 771.00 | 712.00 | 724.00 |
| 2 | NaN | NaN | 6.00 | 18.00 | 23.00 | 55.00 | 48.00 |
| 3 | NaN | NaN | NaN | NaN | 4.00 | 5.00 | 4.00 |
| 4 | NaN | NaN | NaN | NaN | 3.00 | 4.00 | NaN |
| 7 | NaN | NaN | NaN | NaN | 1.00 | NaN | NaN |
Key Observations:
Identical reviews were left for different orders with matching ratings and descriptions, but varying products/prices.-
This is unusual - could indicate bulk reviews for multiple orders or data collection errors.
order_id
Analyzing order_id duplicate distribution over time
tmp_dupl = df_reviews[df_reviews.order_id.duplicated()]
df_reviews.order_id.explore.anomalies_over_time(
time_column='review_creation_dt'
, anomaly_type='duplicate'
, freq='W'
)
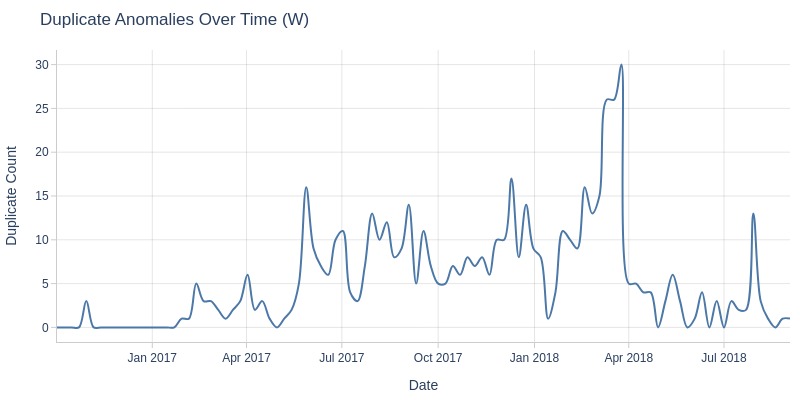
Key Observations:
March 2018 showed a spike in order_id duplicates (multiple reviews for single orders).
tmp_dupl = (tmp_dupl.merge(df_orders, on='order_id', how='left')
.merge(df_customers, on='customer_id', how='left')
)
tmp_dupl = tmp_dupl[['order_id', 'review_id', 'review_score', 'review_comment_title', 'review_comment_message'
, 'review_creation_dt', 'order_delivered_customer_dt', 'order_status']].sort_values('order_id').drop_duplicates()
tmp_dupl.head(10)
| order_id | review_id | review_score | review_comment_title | review_comment_message | review_creation_dt | order_delivered_customer_dt | order_status | |
|---|---|---|---|---|---|---|---|---|
| 34 | 0035246a40f520710769010f752e7507 | 89a02c45c340aeeb1354a24e7d4b2c1e | 5 | NaN | NaN | 2017-08-29 | 2017-08-28 19:14:03 | Delivered |
| 251 | 013056cfe49763c6f66bda03396c5ee3 | 73413b847f63e02bc752b364f6d05ee9 | 4 | NaN | NaN | 2018-03-04 | 2018-03-03 12:09:00 | Delivered |
| 377 | 0176a6846bcb3b0d3aa3116a9a768597 | d8e8c42271c8fb67b9dad95d98c8ff80 | 5 | NaN | NaN | 2017-12-30 | 2017-12-29 21:22:35 | Delivered |
| 446 | 02355020fd0a40a0d56df9f6ff060413 | 0c8e7347f1cdd2aede37371543e3d163 | 3 | NaN | one of the products delivery02 purchased in th... | 2018-03-21 | 2018-04-10 14:48:49 | Delivered |
| 159 | 029863af4b968de1e5d6a82782e662f5 | 61fe4e7d1ae801bbe169eb67b86c6eda | 4 | NaN | NaN | 2017-07-19 | 2017-07-13 20:42:36 | Delivered |
| 65 | 02e0b68852217f5715fb9cc885829454 | fa493ead9b093fb0fa6f7d4905b0ef3b | 4 | NaN | i liked it and delivered quickly | 2017-12-01 | 2017-11-30 18:19:22 | Delivered |
| 92 | 02e723e8edb4a123d414f56cc9c4665e | 39b4603793c1c7f5f36d809b4a218664 | 5 | NaN | excellent | 2017-09-01 | NaT | Canceled |
| 128 | 03515a836bb855b03f7df9dee520a8fc | 5e1ee2e924a1dd10d80b99555383c0a7 | 5 | NaN | NaN | 2018-01-31 | 2018-02-05 14:33:00 | Delivered |
| 134 | 03c939fd7fd3b38f8485a0f95798f1f6 | f4bb9d6dd4fb6dcc2298f0e7b17b8e1e | 4 | NaN | NaN | 2018-03-29 | 2018-03-19 21:48:52 | Delivered |
| 254 | 03c939fd7fd3b38f8485a0f95798f1f6 | 405eb2ea45e1dbe2662541ae5b47e2aa | 3 | NaN | it would be great if they had delivered the 3 ... | 2018-03-06 | 2018-03-19 21:48:52 | Delivered |
Key Observations:
Customers sometimes left multiple reviews per order (e.g., one pre-delivery and one post-delivery) - not necessarily anomalous.
Let’s examine how many duplicates share identical values across different columns.
For description fields, we’ll replace missing values with na.
(tmp_dupl.fillna({'review_comment_message': '__na__'})
.groupby('order_id')
[['review_comment_message', 'review_score', 'order_status']]
.nunique()
.apply(pd.Series.value_counts)
)
| review_comment_message | review_score | order_status | |
|---|---|---|---|
| 1 | 553 | 554 | 555.00 |
| 2 | 2 | 1 | NaN |
Secondary Review Rating Comparison
We’ll analyze whether follow-up reviews for the same order had higher or lower ratings:
Compare average ratings with initial ratings
If initial rating was lower, subsequent ratings were either equal or higher
(tmp_dupl.sort_values(['order_id', 'review_creation_dt'])
.groupby('order_id')
.agg(
first_review_score = ('review_score', 'first')
, mean_review_score = ('review_score', 'mean')
)
.assign(
is_first_less_mean = lambda x: x.first_review_score < x.mean_review_score
)
['is_first_less_mean']
.value_counts()
)
is_first_less_mean
False 554
True 1
Name: count, dtype: int64
Key Observations:
Subsequent reviews for the same order typically received lower ratings than the initial review.
del tmp_dupl
Table df_products#
Let’s look at the information about the dataframe.
df_products.explore.info()
| Summary | Column Types | |||
|---|---|---|---|---|
| Rows | 32.95k | Text | 1 | |
| Features | 9 | Categorical | 1 | |
| Missing cells | 2.45k (<1%) | Int | 7 | |
| Exact Duplicates | --- | Float | 0 | |
| Fuzzy Duplicates | --- | Datetime | 0 | |
| Memory Usage (Mb) | 4 | |||
Initial Column Analysis#
We will examine each column individually.
product_id
df_products['product_id'].explore.info(plot=False)
| Summary | Text Metrics | |||
|---|---|---|---|---|
| Total Values | 32.95k (100%) | Avg Word Count | 1.0 | |
| Missing Values | --- | Max Length (chars) | 32.0 | |
| Empty Strings | --- | Avg Length (chars) | 32.0 | |
| Distinct Values | 32.95k (100%) | Median Length (chars) | 32.0 | |
| Non-Duplicates | 32.95k (100%) | Min Length (chars) | 32.0 | |
| Exact Duplicates | --- | Most Common Length | 32 (100.0%) | |
| Fuzzy Duplicates | --- | Avg Digit Ratio | 0.63 | |
| Values with Duplicates | --- | |||
| Memory Usage | 3 | |||
product_category_name
df_products['product_category_name'].explore.info()
| Summary | Text Metrics | Value Counts | |||||
|---|---|---|---|---|---|---|---|
| Total Values | 32.95k (100%) | Avg Word Count | 1.0 | cama_mesa_banho | 3.03k (9%) | ||
| Missing Values | 610 (2%) | Max Length (chars) | 46.0 | esporte_lazer | 2.87k (9%) | ||
| Empty Strings | --- | Avg Length (chars) | 15.0 | moveis_decoracao | 2.66k (8%) | ||
| Distinct Values | 73 (<1%) | Median Length (chars) | 15.0 | beleza_saude | 2.44k (7%) | ||
| Non-Duplicates | 1 (<1%) | Min Length (chars) | 3.0 | utilidades_domesticas | 2.33k (7%) | ||
| Exact Duplicates | 32.88k (99%) | Most Common Length | 10.0 (15.1%) | automotivo | 1.90k (6%) | ||
| Fuzzy Duplicates | 32.88k (99%) | Avg Digit Ratio | 0.00 | informatica_acessorios | 1.64k (5%) | ||
| Values with Duplicates | 72 (<1%) | brinquedos | 1.41k (4%) | ||||
| Memory Usage | <1 Mb | relogios_presentes | 1.33k (4%) | ||||
Key Observations:
product_category_name contains 2% missing values
Dataset contains 73 unique product categories
product_name_lenght
df_products['product_name_lenght'].explore.info()
| Summary | Percentiles | Detailed Stats | Value Counts | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Total | 32.34k (98%) | Max | 76 | Mean | 48.48 | 60 | 2.18k (7%) | |||
| Missing | 610 (2%) | 99% | 63 | Trimmed Mean (10%) | 49.63 | 59 | 2.02k (6%) | |||
| Distinct | 66 (<1%) | 95% | 60 | Mode | 60 | 58 | 1.89k (6%) | |||
| Non-Duplicate | 7 (<1%) | 75% | 57 | Range | 71 | 57 | 1.72k (5%) | |||
| Duplicates | 32.88k (99%) | 50% | 51 | IQR | 15 | 55 | 1.68k (5%) | |||
| Dup. Values | 59 (<1%) | 25% | 42 | Std | 10.25 | 56 | 1.68k (5%) | |||
| Zeros | --- | 5% | 29 | MAD | 10.38 | 54 | 1.44k (4%) | |||
| Negative | --- | 1% | 20 | Kurt | 0.19 | 53 | 1.33k (4%) | |||
| Memory Usage | <1 Mb | Min | 5 | Skew | -0.90 | 52 | 1.26k (4%) | |||
Key Observations:
product_name_lenght has 2% missing values
Maximum product name length: 76 characters
product_description_lenght
df_products['product_description_lenght'].explore.info()
| Summary | Percentiles | Detailed Stats | Value Counts | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Total | 32.34k (98%) | Max | 3.99k | Mean | 771.50 | 404 | 94 (<1%) | |||
| Missing | 610 (2%) | 99% | 3.29k | Trimmed Mean (10%) | 662.91 | 729 | 86 (<1%) | |||
| Distinct | 2.96k (9%) | 95% | 2.06k | Mode | 404 | 651 | 66 (<1%) | |||
| Non-Duplicate | 669 (2%) | 75% | 972 | Range | 3.99k | 703 | 66 (<1%) | |||
| Duplicates | 29.99k (91%) | 50% | 595 | IQR | 633 | 236 | 65 (<1%) | |||
| Dup. Values | 2.29k (7%) | 25% | 339 | Std | 635.12 | 184 | 65 (<1%) | |||
| Zeros | --- | 5% | 150 | MAD | 434.40 | 303 | 63 (<1%) | |||
| Negative | --- | 1% | 84 | Kurt | 4.83 | 352 | 62 (<1%) | |||
| Memory Usage | <1 Mb | Min | 4 | Skew | 1.96 | 375 | 60 (<1%) | |||
Key Observations:
There are 2% missing values in product_description_lenght.
The maximum length of the product description is 3.99k characters.
The minimum length of the product description is 4 characters.
product_photos_qty
df_products['product_photos_qty'].explore.info(column_type='categorical')
| Summary | Text Metrics | Value Counts | |||||
|---|---|---|---|---|---|---|---|
| Total Values | 32.95k (100%) | Avg Word Count | 1.0 | 1.0 | 16.49k (50%) | ||
| Missing Values | 610 (2%) | Max Length (chars) | 4.0 | 2.0 | 6.26k (19%) | ||
| Empty Strings | --- | Avg Length (chars) | 3.0 | 3.0 | 3.86k (12%) | ||
| Distinct Values | 19 (<1%) | Median Length (chars) | 3.0 | 4.0 | 2.43k (7%) | ||
| Non-Duplicates | 2 (<1%) | Min Length (chars) | 3.0 | 5.0 | 1.48k (5%) | ||
| Exact Duplicates | 32.93k (99%) | Most Common Length | 3 (97.5%) | 6.0 | 968 (3%) | ||
| Fuzzy Duplicates | 32.93k (99%) | Avg Digit Ratio | 0.67 | 7.0 | 343 (1%) | ||
| Values with Duplicates | 17 (<1%) | 8.0 | 192 (<1%) | ||||
| Memory Usage | 2 | 9.0 | 105 (<1%) | ||||
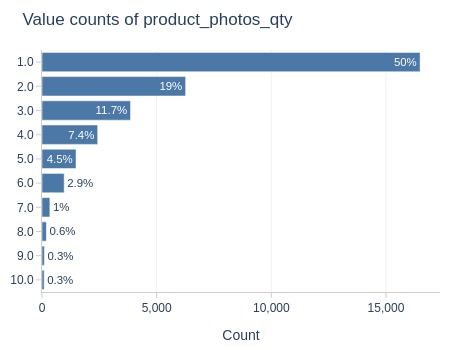
Key Observations:
In product_photos_qty, 2% of values are missing.
The maximum number of photos for a single product is 20.
50% of products have 1 photo.
product_weight_g
df_products['product_weight_g'].explore.info()
| Summary | Percentiles | Detailed Stats | Value Counts | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Total | 32.95k (99%) | Max | 40.42k | Mean | 2.28k | 200 | 2.08k (6%) | |||
| Missing | 2 (<1%) | 99% | 22.54k | Trimmed Mean (10%) | 1.20k | 300 | 1.56k (5%) | |||
| Distinct | 2.20k (7%) | 95% | 10.85k | Mode | 200 | 150 | 1.26k (4%) | |||
| Non-Duplicate | 1.03k (3%) | 75% | 1.90k | Range | 40.42k | 400 | 1.21k (4%) | |||
| Duplicates | 30.75k (93%) | 50% | 700 | IQR | 1.60k | 100 | 1.19k (4%) | |||
| Dup. Values | 1.17k (4%) | 25% | 300 | Std | 4.28k | 500 | 1.11k (3%) | |||
| Zeros | 4 (<1%) | 5% | 105 | MAD | 741.30 | 250 | 1.00k (3%) | |||
| Negative | --- | 1% | 60 | Kurt | 15.13 | 600 | 957 (3%) | |||
| Memory Usage | <1 Mb | Min | 0 | Skew | 3.60 | 350 | 832 (3%) | |||
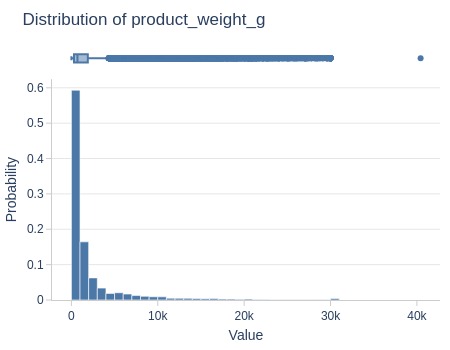
Key Observations:
In product_weight_g, there are 2 missing values.
In product_weight_g, there are 4 zero values.
The maximum product weight is 40.42k grams.
The product weight of 40.42k grams is clearly an outlier.
product_length_cm
df_products['product_length_cm'].explore.info()
| Summary | Percentiles | Detailed Stats | Value Counts | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Total | 32.95k (99%) | Max | 105 | Mean | 30.82 | 16 | 5.52k (17%) | |||
| Missing | 2 (<1%) | 99% | 100 | Trimmed Mean (10%) | 27.79 | 20 | 2.82k (9%) | |||
| Distinct | 99 (<1%) | 95% | 65 | Mode | 16 | 30 | 2.03k (6%) | |||
| Non-Duplicate | 1 (<1%) | 75% | 38 | Range | 98 | 18 | 1.50k (5%) | |||
| Duplicates | 32.85k (99%) | 50% | 25 | IQR | 20 | 25 | 1.39k (4%) | |||
| Dup. Values | 98 (<1%) | 25% | 18 | Std | 16.91 | 17 | 1.31k (4%) | |||
| Zeros | --- | 5% | 16 | MAD | 11.86 | 19 | 1.27k (4%) | |||
| Negative | --- | 1% | 16 | Kurt | 3.51 | 40 | 1.22k (4%) | |||
| Memory Usage | <1 Mb | Min | 7 | Skew | 1.75 | 22 | 972 (3%) | |||
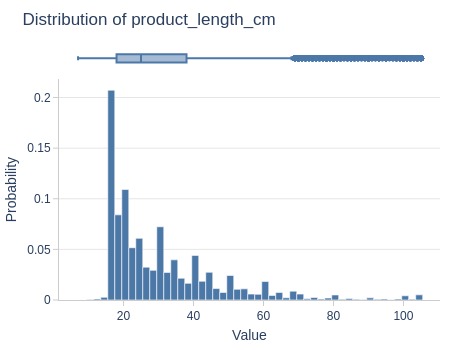
Key Observations:
In product_length_cm, there are 2 missing values.
The maximum product length is 105 cm. The minimum is 7 cm. The median is 25 cm.
product_height_cm
df_products['product_height_cm'].explore.info()
| Summary | Percentiles | Detailed Stats | Value Counts | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Total | 32.95k (99%) | Max | 105 | Mean | 16.94 | 10 | 2.55k (8%) | |||
| Missing | 2 (<1%) | 99% | 69 | Trimmed Mean (10%) | 14.74 | 15 | 2.02k (6%) | |||
| Distinct | 102 (<1%) | 95% | 44 | Mode | 10 | 20 | 1.99k (6%) | |||
| Non-Duplicate | 3 (<1%) | 75% | 21 | Range | 103 | 16 | 1.59k (5%) | |||
| Duplicates | 32.85k (99%) | 50% | 13 | IQR | 13 | 11 | 1.55k (5%) | |||
| Dup. Values | 99 (<1%) | 25% | 8 | Std | 13.64 | 5 | 1.53k (5%) | |||
| Zeros | --- | 5% | 3 | MAD | 8.90 | 12 | 1.52k (5%) | |||
| Negative | --- | 1% | 2 | Kurt | 6.68 | 8 | 1.47k (4%) | |||
| Memory Usage | <1 Mb | Min | 2 | Skew | 2.14 | 2 | 1.36k (4%) | |||
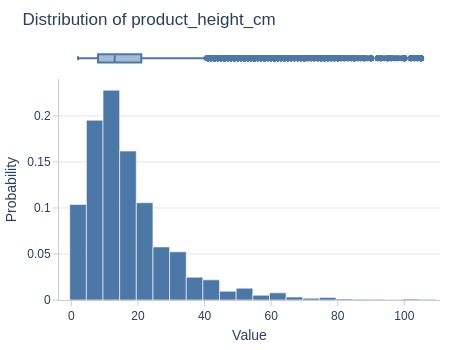
Key Observations:
In product_height_cm, there are 2 missing values.
The maximum product height is 105 cm. The minimum is 2 cm. The median is 13 cm.
product_width_cm
df_products['product_width_cm'].explore.info()
| Summary | Percentiles | Detailed Stats | Value Counts | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Total | 32.95k (99%) | Max | 118 | Mean | 23.20 | 11 | 3.72k (11%) | |||
| Missing | 2 (<1%) | 99% | 63 | Trimmed Mean (10%) | 21.39 | 20 | 3.05k (9%) | |||
| Distinct | 95 (<1%) | 95% | 47 | Mode | 11 | 16 | 2.81k (9%) | |||
| Non-Duplicate | 9 (<1%) | 75% | 30 | Range | 112 | 15 | 2.39k (7%) | |||
| Duplicates | 32.85k (99%) | 50% | 20 | IQR | 15 | 30 | 1.79k (5%) | |||
| Dup. Values | 86 (<1%) | 25% | 15 | Std | 12.08 | 12 | 1.54k (5%) | |||
| Zeros | --- | 5% | 11 | MAD | 8.90 | 25 | 1.33k (4%) | |||
| Negative | --- | 1% | 11 | Kurt | 4.07 | 14 | 1.26k (4%) | |||
| Memory Usage | <1 Mb | Min | 6 | Skew | 1.67 | 13 | 1.13k (3%) | |||
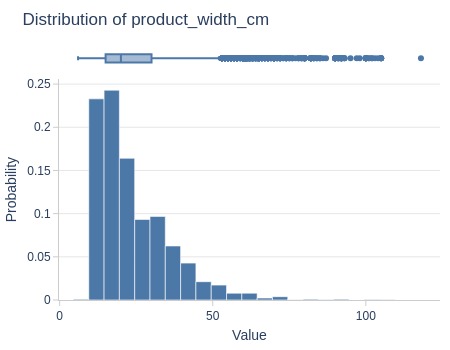
Key Observations:
In product_width_cm, there are 2 missing values.
The maximum product width is 118 cm. The minimum is 6 cm. The median is 20 cm.
Exploring Missing Values#
Let’s see which columns have missing values.
df_products.explore.anomalies_report(
anomaly_type='missing'
, pct_diff_threshold=10
)
| Count | Percent | |
|---|---|---|
| product_category_name | 610 | 1.9% |
| product_name_lenght | 610 | 1.9% |
| product_description_lenght | 610 | 1.9% |
| product_photos_qty | 610 | 1.9% |
| product_weight_g | 2 | 0.0% |
| product_length_cm | 2 | 0.0% |
| product_height_cm | 2 | 0.0% |
| product_width_cm | 2 | 0.0% |
| product_category_name | product_name_lenght | product_description_lenght | product_photos_qty | product_weight_g | product_length_cm | product_height_cm | product_width_cm | |
|---|---|---|---|---|---|---|---|---|
| product_category_name | ||||||||
| product_name_lenght | < 100.0% / ^ 100.0% | |||||||
| product_description_lenght | < 100.0% / ^ 100.0% | < 100.0% / ^ 100.0% | ||||||
| product_photos_qty | < 100.0% / ^ 100.0% | < 100.0% / ^ 100.0% | < 100.0% / ^ 100.0% | |||||
| product_weight_g | < 50.0% / ^ under 1% | < 50.0% / ^ under 1% | < 50.0% / ^ under 1% | < 50.0% / ^ under 1% | ||||
| product_length_cm | < 50.0% / ^ under 1% | < 50.0% / ^ under 1% | < 50.0% / ^ under 1% | < 50.0% / ^ under 1% | < 100.0% / ^ 100.0% | |||
| product_height_cm | < 50.0% / ^ under 1% | < 50.0% / ^ under 1% | < 50.0% / ^ under 1% | < 50.0% / ^ under 1% | < 100.0% / ^ 100.0% | < 100.0% / ^ 100.0% | ||
| product_width_cm | < 50.0% / ^ under 1% | < 50.0% / ^ under 1% | < 50.0% / ^ under 1% | < 50.0% / ^ under 1% | < 100.0% / ^ 100.0% | < 100.0% / ^ 100.0% | < 100.0% / ^ 100.0% |
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| product_category_name | nan | 610 | 610 | 100.0% | 1.9% | 99.8% | 98.0% |
| product_id | product_category_name | product_name_lenght | product_description_lenght | product_photos_qty | product_weight_g | product_length_cm | product_height_cm | product_width_cm | |
|---|---|---|---|---|---|---|---|---|---|
| 23260 | 96aca2f53bcaed6f466449f7fb18ae75 | nan | nan | nan | nan | 400.0 | 16.0 | 16.0 | 16.0 |
| 428 | 629beb8e7317703dcc5f35b5463fd20e | nan | nan | nan | nan | 1400.0 | 25.0 | 25.0 | 25.0 |
| 14367 | f18333439cbbfd0ae30acf09ae09c0f0 | nan | nan | nan | nan | 23300.0 | 56.0 | 48.0 | 40.0 |
| 16816 | f55cd6a68f96c3041176998ce1850ff3 | nan | nan | nan | nan | 200.0 | 20.0 | 5.0 | 20.0 |
| 18850 | 1e9e02777a02de03c17eb432be7daf71 | nan | nan | nan | nan | 200.0 | 16.0 | 5.0 | 15.0 |
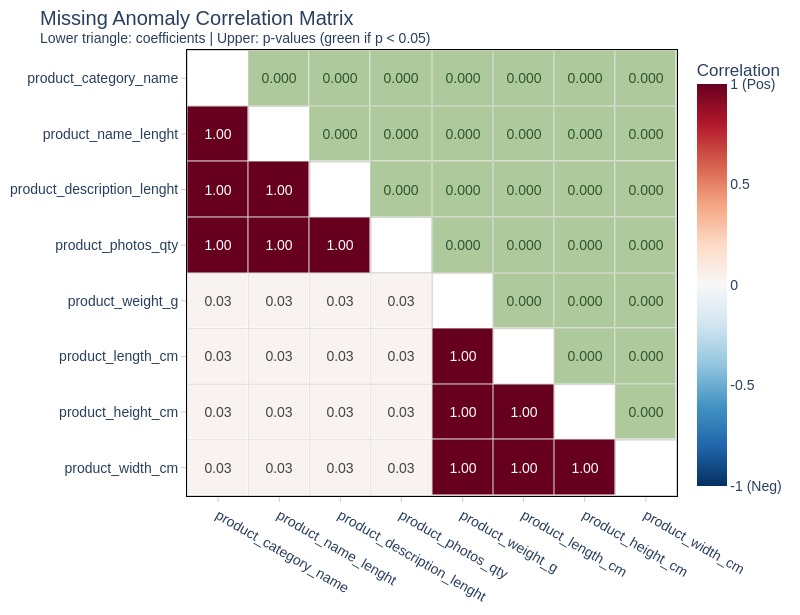
Let’s hypothesize that missing values in the following columns are in the same rows:
product category name
product name length
product description length
number of product photos
df_products.explore.detect_simultaneous_anomalies(['product_category_name', 'product_name_lenght', 'product_description_lenght', 'product_photos_qty'])
| Column | Individual Anomalies | % of Total | % in Simultaneous |
|---|---|---|---|
| product_category_name | 610 | 1.85% | 100.00% |
| product_name_lenght | 610 | 1.85% | 100.00% |
| product_description_lenght | 610 | 1.85% | 100.00% |
| product_photos_qty | 610 | 1.85% | 100.00% |
Key Observations:
Missing values in product category name, product name length, product description length, and number of product photos are in the same rows.
Let’s hypothesize that missing values in the following columns are in the same rows:
product length
product width
product height
product weight
df_products.explore.detect_simultaneous_anomalies(['product_weight_g', 'product_length_cm', 'product_height_cm', 'product_width_cm'])
| Column | Individual Anomalies | % of Total | % in Simultaneous |
|---|---|---|---|
| product_weight_g | 2 | 0.01% | 100.00% |
| product_length_cm | 2 | 0.01% | 100.00% |
| product_height_cm | 2 | 0.01% | 100.00% |
| product_width_cm | 2 | 0.01% | 100.00% |
Key Observations:
Missing values in product length, width, height, and weight are located in the same rows.
Exploring Outliers#
df_products.explore.anomalies_report(
anomaly_type='outlier'
)
| Count | Percent | |
|---|---|---|
| product_name_lenght | 2322 | 7.0% |
| product_description_lenght | 3212 | 9.7% |
| product_photos_qty | 849 | 2.6% |
| product_weight_g | 3279 | 10.0% |
| product_length_cm | 1694 | 5.1% |
| product_height_cm | 2956 | 9.0% |
| product_width_cm | 1616 | 4.9% |
| product_name_lenght | product_description_lenght | product_photos_qty | product_weight_g | product_length_cm | product_height_cm | product_width_cm | |
|---|---|---|---|---|---|---|---|
| product_name_lenght | |||||||
| product_description_lenght | < 8.2% / ^ 11.3% | ||||||
| product_photos_qty | < 13.9% / ^ 5.1% | < 13.1% / ^ 3.5% | |||||
| product_weight_g | < 7.2% / ^ 10.1% | < 11.8% / ^ 12.1% | < 2.7% / ^ 10.5% | ||||
| product_length_cm | < 7.5% / ^ 5.5% | < 11.2% / ^ 5.9% | < 3.7% / ^ 7.4% | < 22.0% / ^ 11.3% | |||
| product_height_cm | < 7.1% / ^ 9.0% | < 7.6% / ^ 7.0% | < 3.6% / ^ 12.6% | < 30.7% / ^ 27.7% | < 5.9% / ^ 10.3% | ||
| product_width_cm | < 8.5% / ^ 5.9% | < 13.7% / ^ 6.9% | < 2.7% / ^ 5.1% | < 37.6% / ^ 18.5% | < 30.3% / ^ 28.9% | < 18.3% / ^ 10.0% |
| Column | Category | % Diff |
|---|
| product_id | product_category_name | product_name_lenght | product_description_lenght | product_photos_qty | product_weight_g | product_length_cm | product_height_cm | product_width_cm | |
|---|---|---|---|---|---|---|---|---|---|
| 18231 | b29c9ac1d3d4e8866f6c4ad814ae9591 | beleza_saude | 18.0 | 1177.0 | 1.0 | 500.0 | 31.0 | 11.0 | 23.0 |
| 15521 | c413fa08b405af6edb9d49e85e241c08 | telefonia | 37.0 | 326.0 | 2.0 | 100.0 | 18.0 | 4.0 | 12.0 |
| 14354 | 975c79322e3ae1a967d8f5b82608ffd7 | livros_importados | 52.0 | 502.0 | 1.0 | 500.0 | 30.0 | 2.0 | 20.0 |
| 15381 | e2e9a22be498ad23b97170cbc20c477c | automotivo | 39.0 | 360.0 | 1.0 | 14350.0 | 63.0 | 63.0 | 21.0 |
| 5751 | fe31b2791161c24e921f90788d443e1c | consoles_games | 60.0 | 2462.0 | 5.0 | 1100.0 | 22.0 | 13.0 | 18.0 |
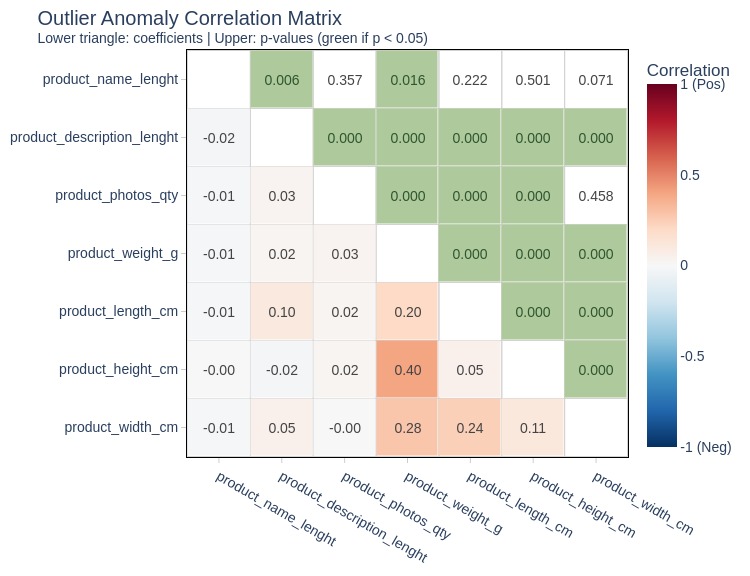
Key Observations:
The proportion of outliers in the number of photos, length, and width of products is within normal limits.
The proportion of outliers in product weight and height exceeds the norm (usually 5%), but is not critical.
Exploring Other Anomalies#
Examining zero values
df_products.explore.anomalies_report(
anomaly_type='zero'
)
| Count | Percent | |
|---|---|---|
| product_weight_g | 4 | 0.0% |
Not enough columns with zero to analyze combinations
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| product_category_name | cama_mesa_banho | 3029 | 4 | 0.1% | 9.2% | 100.0% | 90.8% |
| product_id | product_category_name | product_name_lenght | product_description_lenght | product_photos_qty | product_weight_g | product_length_cm | product_height_cm | product_width_cm | |
|---|---|---|---|---|---|---|---|---|---|
| 13683 | 8038040ee2a71048d4bdbbdc985b69ab | cama_mesa_banho | 48.0 | 528.0 | 1.0 | 0.0 | 30.0 | 25.0 | 30.0 |
| 32079 | e673e90efa65a5409ff4196c038bb5af | cama_mesa_banho | 53.0 | 528.0 | 1.0 | 0.0 | 30.0 | 25.0 | 30.0 |
| 9769 | 81781c0fed9fe1ad6e8c81fca1e1cb08 | cama_mesa_banho | 51.0 | 529.0 | 1.0 | 0.0 | 30.0 | 25.0 | 30.0 |
| 14997 | 36ba42dd187055e1fbe943b2d11430ca | cama_mesa_banho | 53.0 | 528.0 | 1.0 | 0.0 | 30.0 | 25.0 | 30.0 |
Not enough columns with anomalies for correlation analysis
Key Observations:
All 4 products with zero weight belong to the category cama_mesa_banho (home textiles).
Table df_categories#
Let’s look at the information about the dataframe.
df_categories.explore.info()
| Summary | Column Types | |||
|---|---|---|---|---|
| Rows | 71 | Text | 0 | |
| Features | 2 | Categorical | 2 | |
| Missing cells | --- | Int | 0 | |
| Exact Duplicates | --- | Float | 0 | |
| Fuzzy Duplicates | --- | Datetime | 0 | |
| Memory Usage (Mb) | <1 Mb | |||
Initial Column Analysis#
We will examine each column individually.
product_category_name
df_categories['product_category_name'].explore.info(plot=False)
| Summary | Text Metrics | Value Counts | |||||
|---|---|---|---|---|---|---|---|
| Total Values | 71 (100%) | Avg Word Count | 1.0 | agro_industria_e_comercio | 1 (1%) | ||
| Missing Values | --- | Max Length (chars) | 46.0 | instrumentos_musicais | 1 (1%) | ||
| Empty Strings | --- | Avg Length (chars) | 17.0 | market_place | 1 (1%) | ||
| Distinct Values | 71 (100%) | Median Length (chars) | 16.0 | malas_acessorios | 1 (1%) | ||
| Non-Duplicates | 71 (100%) | Min Length (chars) | 3.0 | livros_tecnicos | 1 (1%) | ||
| Exact Duplicates | --- | Most Common Length | 15 (9.9%) | livros_interesse_geral | 1 (1%) | ||
| Fuzzy Duplicates | --- | Avg Digit Ratio | 0.00 | livros_importados | 1 (1%) | ||
| Values with Duplicates | --- | la_cuisine | 1 (1%) | ||||
| Memory Usage | <1 Mb | informatica_acessorios | 1 (1%) | ||||
Key Observations:
The product_category_name table has 71 unique product categories, while the products table has 73 categories.
product_category_name_english
df_categories['product_category_name_english'].explore.info(plot=False)
| Summary | Text Metrics | Value Counts | |||||
|---|---|---|---|---|---|---|---|
| Total Values | 71 (100%) | Avg Word Count | 2.3 | Agro Industry And Commerce | 1 (1%) | ||
| Missing Values | --- | Max Length (chars) | 39.0 | Home Appliances 2 | 1 (1%) | ||
| Empty Strings | --- | Avg Length (chars) | 16.1 | Kitchen Dining Laundry Garden Furniture | 1 (1%) | ||
| Distinct Values | 71 (100%) | Median Length (chars) | 15.0 | Industry Commerce And Business | 1 (1%) | ||
| Non-Duplicates | 71 (100%) | Min Length (chars) | 3.0 | Housewares | 1 (1%) | ||
| Exact Duplicates | --- | Most Common Length | 10 (8.5%) | Home Construction | 1 (1%) | ||
| Fuzzy Duplicates | --- | Avg Digit Ratio | 0.00 | Home Confort | 1 (1%) | ||
| Values with Duplicates | --- | Home Comfort 2 | 1 (1%) | ||||
| Memory Usage | <1 Mb | Home Appliances | 1 (1%) | ||||
Table df_sellers#
Let’s look at the information about the dataframe.
df_sellers.explore.info()
| Summary | Column Types | |||
|---|---|---|---|---|
| Rows | 3.10k | Text | 1 | |
| Features | 4 | Categorical | 2 | |
| Missing cells | --- | Int | 1 | |
| Exact Duplicates | --- | Float | 0 | |
| Fuzzy Duplicates | --- | Datetime | 0 | |
| Memory Usage (Mb) | <1 Mb | |||
Initial Column Analysis#
We will examine each column individually.
seller_id
df_sellers['seller_id'].explore.info(plot=False)
| Summary | Text Metrics | |||
|---|---|---|---|---|
| Total Values | 3.10k (100%) | Avg Word Count | 1.0 | |
| Missing Values | --- | Max Length (chars) | 32.0 | |
| Empty Strings | --- | Avg Length (chars) | 32.0 | |
| Distinct Values | 3.10k (100%) | Median Length (chars) | 32.0 | |
| Non-Duplicates | 3.10k (100%) | Min Length (chars) | 32.0 | |
| Exact Duplicates | --- | Most Common Length | 32 (100.0%) | |
| Fuzzy Duplicates | --- | Avg Digit Ratio | 0.62 | |
| Values with Duplicates | --- | |||
| Memory Usage | <1 Mb | |||
seller_zip_code_prefix
df_sellers['seller_zip_code_prefix'].explore.info(plot=False)
| Summary | Percentiles | Detailed Stats | Value Counts | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Total | 3.10k (100%) | Max | 99.73k | Mean | 32.29k | 14940 | 49 (2%) | |||
| Missing | --- | 99% | 95.90k | Trimmed Mean (10%) | 28.67k | 13660 | 10 (<1%) | |||
| Distinct | 2.25k (73%) | 95% | 89.29k | Mode | 14940 | 13920 | 9 (<1%) | |||
| Non-Duplicate | 1.71k (55%) | 75% | 64.55k | Range | 98729 | 16200 | 9 (<1%) | |||
| Duplicates | 849 (27%) | 50% | 14.94k | IQR | 57.46k | 87050 | 8 (<1%) | |||
| Dup. Values | 537 (17%) | 25% | 7.09k | Std | 32.71k | 14020 | 8 (<1%) | |||
| Zeros | --- | 5% | 2.46k | MAD | 16.18k | 1026 | 8 (<1%) | |||
| Negative | --- | 1% | 1.14k | Kurt | -0.86 | 37540 | 7 (<1%) | |||
| Memory Usage | <1 Mb | Min | 1.00k | Skew | 0.92 | 13481 | 7 (<1%) | |||
seller_city
df_sellers['seller_city'].explore.info()
| Summary | Text Metrics | Value Counts | |||||
|---|---|---|---|---|---|---|---|
| Total Values | 3.10k (100%) | Avg Word Count | 1.7 | Sao Paulo | 695 (22%) | ||
| Missing Values | --- | Max Length (chars) | 38.0 | Curitiba | 127 (4%) | ||
| Empty Strings | --- | Avg Length (chars) | 10.2 | Rio De Janeiro | 96 (3%) | ||
| Distinct Values | 605 (20%) | Median Length (chars) | 9.0 | Belo Horizonte | 68 (2%) | ||
| Non-Duplicates | 337 (11%) | Min Length (chars) | 2.0 | Ribeirao Preto | 52 (2%) | ||
| Exact Duplicates | 2.49k (80%) | Most Common Length | 9 (29.4%) | Guarulhos | 50 (2%) | ||
| Fuzzy Duplicates | 2.49k (80%) | Avg Digit Ratio | 0.00 | Ibitinga | 49 (2%) | ||
| Values with Duplicates | 268 (9%) | Santo Andre | 45 (1%) | ||||
| Memory Usage | <1 Mb | Campinas | 41 (1%) | ||||
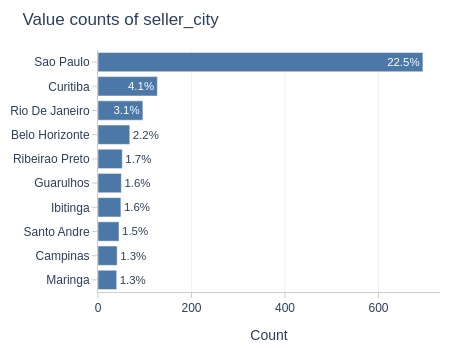
Key Observations:
The most sellers are from the city of sao paulo (22%).
seller_state
df_sellers['seller_state'].explore.info()
| Summary | Text Metrics | Value Counts | |||||
|---|---|---|---|---|---|---|---|
| Total Values | 3.10k (100%) | Avg Word Count | 1.0 | SP | 1.85k (60%) | ||
| Missing Values | --- | Max Length (chars) | 2.0 | PR | 349 (11%) | ||
| Empty Strings | --- | Avg Length (chars) | 2.0 | MG | 244 (8%) | ||
| Distinct Values | 23 (<1%) | Median Length (chars) | 2.0 | SC | 190 (6%) | ||
| Non-Duplicates | 5 (<1%) | Min Length (chars) | 2.0 | RJ | 171 (6%) | ||
| Exact Duplicates | 3.07k (99%) | Most Common Length | 2 (100.0%) | RS | 129 (4%) | ||
| Fuzzy Duplicates | 3.07k (99%) | Avg Digit Ratio | 0.00 | GO | 40 (1%) | ||
| Values with Duplicates | 18 (<1%) | DF | 30 (<1%) | ||||
| Memory Usage | <1 Mb | ES | 23 (<1%) | ||||
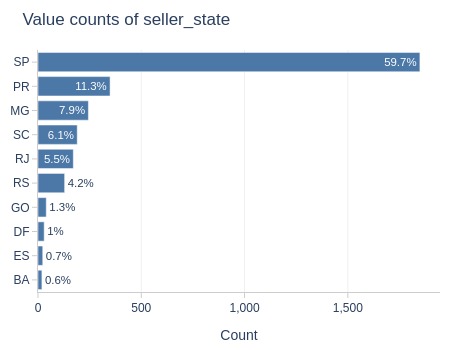
Key Observations:
The most sellers are from the state of sp (60%).
Table df_geolocations#
Let’s look at the information about the dataframe.
df_geolocations.explore.info()
| Summary | Column Types | |||
|---|---|---|---|---|
| Rows | 1.00m | Text | 0 | |
| Features | 5 | Categorical | 2 | |
| Missing cells | --- | Int | 1 | |
| Exact Duplicates | 279.76k (28%) | Float | 2 | |
| Fuzzy Duplicates | --- | Datetime | 0 | |
| Memory Usage (Mb) | 26 | |||
Key Observations:
The df_geolocations table has 28% fully duplicated rows.
Initial Column Analysis#
We will examine each column individually.
geolocation_zip_code_prefix
df_geolocations['geolocation_zip_code_prefix'].explore.info(plot=False)
| Summary | Percentiles | Detailed Stats | Value Counts | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Total | 1.00m (100%) | Max | 99.99k | Mean | 36.57k | 24220 | 1.15k (<1%) | |||
| Missing | --- | 99% | 98.01k | Trimmed Mean (10%) | 33.75k | 24230 | 1.10k (<1%) | |||
| Distinct | 19.02k (2%) | 95% | 91.75k | Mode | 24220 | 38400 | 965 (<1%) | |||
| Non-Duplicate | 1.04k (<1%) | 75% | 63.50k | Range | 98989 | 35500 | 907 (<1%) | |||
| Duplicates | 981.15k (98%) | 50% | 26.53k | IQR | 52.43k | 11680 | 879 (<1%) | |||
| Dup. Values | 17.97k (2%) | 25% | 11.07k | Std | 30.55k | 22631 | 832 (<1%) | |||
| Zeros | --- | 5% | 3.22k | MAD | 28.07k | 30140 | 810 (<1%) | |||
| Negative | --- | 1% | 1.32k | Kurt | -0.94 | 11740 | 788 (<1%) | |||
| Memory Usage | 8 | Min | 1.00k | Skew | 0.69 | 38408 | 773 (<1%) | |||
geolocation_lat
df_geolocations['geolocation_lat'].explore.info(plot=False)
| Summary | Percentiles | Detailed Stats | Value Counts | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Total | 1.00m (100%) | Max | 45.07 | Mean | -21.18 | -27.10 | 314 (<1%) | |||
| Missing | --- | 99% | -2.50 | Trimmed Mean (10%) | -21.98 | -23.50 | 190 (<1%) | |||
| Distinct | 717.36k (72%) | 95% | -7.67 | Mode | -27.10 | -23.51 | 141 (<1%) | |||
| Non-Duplicate | 584.67k (58%) | 75% | -19.98 | Range | 81.67 | -23.49 | 127 (<1%) | |||
| Duplicates | 282.80k (28%) | 50% | -22.92 | IQR | 3.62 | -23.01 | 102 (<1%) | |||
| Dup. Values | 132.69k (13%) | 25% | -23.60 | Std | 5.72 | -23.00 | 89 (<1%) | |||
| Zeros | --- | 5% | -28.98 | MAD | 1.65 | -22.97 | 89 (<1%) | |||
| Negative | 998.83k (99%) | 1% | -30.10 | Kurt | 2.85 | -15.84 | 85 (<1%) | |||
| Memory Usage | 8 | Min | -36.61 | Skew | 1.57 | -23.54 | 83 (<1%) | |||
geolocation_lng
df_geolocations['geolocation_lng'].explore.info(plot=False)
| Summary | Percentiles | Detailed Stats | Value Counts | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Total | 1.00m (100%) | Max | 121.11 | Mean | -46.39 | -48.63 | 314 (<1%) | |||
| Missing | --- | 99% | -34.94 | Trimmed Mean (10%) | -46.44 | -46.87 | 190 (<1%) | |||
| Distinct | 717.61k (72%) | 95% | -38.50 | Mode | -48.63 | -46.72 | 141 (<1%) | |||
| Non-Duplicate | 585.03k (58%) | 75% | -43.77 | Range | 222.57 | -46.87 | 127 (<1%) | |||
| Duplicates | 282.55k (28%) | 50% | -46.64 | IQR | 4.81 | -43.38 | 102 (<1%) | |||
| Dup. Values | 132.59k (13%) | 25% | -48.57 | Std | 4.27 | -46.55 | 91 (<1%) | |||
| Zeros | --- | 5% | -53.22 | MAD | 3.84 | -43.39 | 89 (<1%) | |||
| Negative | 1.00m (99%) | 1% | -57.65 | Kurt | 4.73 | -43.32 | 89 (<1%) | |||
| Memory Usage | 8 | Min | -101.47 | Skew | -0.10 | -48.02 | 85 (<1%) | |||
geolocation_city
df_geolocations['geolocation_city'].explore.info()
| Summary | Text Metrics | Value Counts | |||||
|---|---|---|---|---|---|---|---|
| Total Values | 1.00m (100%) | Avg Word Count | 1.8 | Sao Paulo | 160.72k (16%) | ||
| Missing Values | --- | Max Length (chars) | 36.0 | Rio De Janeiro | 62.15k (6%) | ||
| Empty Strings | --- | Avg Length (chars) | 10.5 | Belo Horizonte | 27.80k (3%) | ||
| Distinct Values | 5.93k (<1%) | Median Length (chars) | 9.0 | Curitiba | 16.59k (2%) | ||
| Non-Duplicates | 420 (<1%) | Min Length (chars) | 2.0 | Porto Alegre | 13.52k (1%) | ||
| Exact Duplicates | 994.23k (99%) | Most Common Length | 9 (22.9%) | Brasilia | 12.65k (1%) | ||
| Fuzzy Duplicates | 994.23k (99%) | Avg Digit Ratio | 0.00 | Salvador | 11.87k (1%) | ||
| Values with Duplicates | 5.51k (<1%) | Guarulhos | 11.34k (1%) | ||||
| Memory Usage | 2 | Sao Bernardo Do Campo | 9.63k (<1%) | ||||
Key Observations:
In geolocation_city, the most entries are for the city of sao paulo (16%).
geolocation_state
df_geolocations['geolocation_state'].explore.info()
| Summary | Text Metrics | Value Counts | |||||
|---|---|---|---|---|---|---|---|
| Total Values | 1.00m (100%) | Avg Word Count | 1.0 | SP | 404.27k (40%) | ||
| Missing Values | --- | Max Length (chars) | 2.0 | MG | 126.34k (13%) | ||
| Empty Strings | --- | Avg Length (chars) | 2.0 | RJ | 121.17k (12%) | ||
| Distinct Values | 27 (<1%) | Median Length (chars) | 2.0 | RS | 61.85k (6%) | ||
| Non-Duplicates | --- | Min Length (chars) | 2.0 | PR | 57.86k (6%) | ||
| Exact Duplicates | 1.00m (99%) | Most Common Length | 2 (100.0%) | SC | 38.33k (4%) | ||
| Fuzzy Duplicates | 1.00m (99%) | Avg Digit Ratio | 0.00 | BA | 36.05k (4%) | ||
| Values with Duplicates | 27 (<1%) | GO | 20.14k (2%) | ||||
| Memory Usage | 1 | ES | 16.75k (2%) | ||||
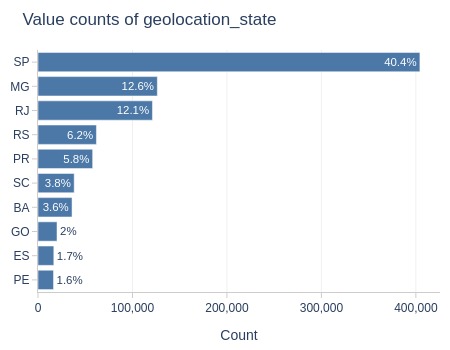
Key Observations:
In geolocation_state, the most entries are for the state of SP (40%).
Exploring Duplicates#
We have complete row duplicates in the geolocation table. Let’s examine them.
Let’s check if we have duplicates in the geolocation table in the geolocation_zip_code_prefix field, excluding common duplicates.
tmp_geo = df_geolocations.drop_duplicates()
tmp_geo.explore.detect_anomalies('duplicate', columns=['geolocation_zip_code_prefix'])
| Count | Percent | |
|---|---|---|
| geolocation_zip_code_prefix | 701390 | 97.36% |
Key Observations:
In the df_geolocations table, there are 97% duplicates in the geolocation_zip_code_prefix column.
Let’s see why there are duplicates.
tmp_geo.groupby('geolocation_zip_code_prefix').nunique().head(10)
| geolocation_lat | geolocation_lng | geolocation_city | geolocation_state | |
|---|---|---|---|---|
| geolocation_zip_code_prefix | ||||
| 1001 | 10 | 10 | 1 | 1 |
| 1002 | 6 | 6 | 1 | 1 |
| 1003 | 10 | 10 | 1 | 1 |
| 1004 | 14 | 14 | 1 | 1 |
| 1005 | 11 | 11 | 1 | 1 |
| 1006 | 7 | 7 | 1 | 1 |
| 1007 | 15 | 15 | 1 | 1 |
| 1008 | 12 | 12 | 1 | 1 |
| 1009 | 7 | 7 | 1 | 1 |
| 1010 | 5 | 5 | 1 | 1 |
This makes sense, as geolocation_zip_code_prefix can have many different unique coordinates.
But we need to take this into account when joining tables, since we only have zip_code_prefix in the customer and seller tables.
When joining, we may get many duplicates.
We can average the coordinates, but we can’t do the same with cities and states.
Let’s check if we have multiple states for a single prefix.
tmp_geo.groupby('geolocation_zip_code_prefix').geolocation_state.nunique().sort_values(ascending=False).head()
geolocation_zip_code_prefix
79750 2
78557 2
72915 2
4011 2
2116 2
Name: geolocation_state, dtype: int64
Let’s see the maximum number of cities with the same prefix.
tmp_geo.groupby('geolocation_zip_code_prefix').geolocation_city.nunique().sort_values(ascending=False).head()
geolocation_zip_code_prefix
65935 4
45936 4
13318 3
72270 3
9780 3
Name: geolocation_city, dtype: int64
Key Observations:
In the df_geolocations table, there are prefixes with 2 unique states.
In the df_geolocations table, there are prefixes with 4 unique cities.
There’s nothing we can do about this. We’ll need to account for this when analyzing geolocation coordinates.
Since we have states in the customer and seller tables, we can avoid using city and state from the geolocation table.
And we can average the coordinates.
Exploring Outliers#
Let’s see how many sales we have outside South America.
tmp_geo = df_geolocations.copy()
tmp_geo['in_south_america'] = (
(tmp_geo.geolocation_lat >= -53.90) & # Southern border
(tmp_geo.geolocation_lat <= 12.45) & # Northern border
(tmp_geo.geolocation_lng >= -81.32) & # Western border
(tmp_geo.geolocation_lng <= -34.79) # Eastern border
)
temp_df = (df_orders[['order_id', 'customer_id']].merge(df_customers, on='customer_id', how='left')
.merge(tmp_geo.drop_duplicates(subset=["geolocation_zip_code_prefix"]), left_on='customer_zip_code_prefix', right_on='geolocation_zip_code_prefix', how='left')
.dropna()
[['in_south_america', 'customer_city', 'customer_state', 'geolocation_lat', 'geolocation_lng']]
)
temp_df.in_south_america.value_counts()
in_south_america
True 99157
False 6
Name: count, dtype: int64
Key Observations:
There are 6 sales outside South America in the dataset.
Let’s look at these orders.
temp_df[temp_df.in_south_america == False]
| in_south_america | customer_city | customer_state | geolocation_lat | geolocation_lng | |
|---|---|---|---|---|---|
| 728 | False | Ilha Dos Valadares | PR | 42.18 | -8.72 |
| 5634 | False | Porto Trombetas | PA | 41.15 | -8.58 |
| 12766 | False | Areia Branca Dos Assis | PR | 39.06 | -9.40 |
| 74197 | False | Areia Branca Dos Assis | PR | 39.06 | -9.40 |
| 89139 | False | Areia Branca Dos Assis | PR | 39.06 | -9.40 |
| 96816 | False | Porto Trombetas | PA | 41.15 | -8.58 |
These coordinates are outside South America. Either it’s an error, or the order was placed outside South America.
(42.18, -8.72) is off the coast of Spain/Portugal
(20.09, -30.54) is in the central Atlantic Ocean
(13.00, -23.58) is in the eastern Atlantic Ocean near Cape Verde
(-11.31, -34.73) is in the South Atlantic
(20.09, -30.54) is a repeating point in the central Atlantic Ocean
del temp_df, tmp_geo
Exploring Cross-Table Anomalies#
Temporal Boundary Checks#
Examining time interval boundaries across different tables.
for key, df in dfs:
datetime_cols = [col for col in df.columns if pd.api.types.is_datetime64_any_dtype(df[col])]
for col in datetime_cols:
min_date = df[col].min()
max_date = df[col].max()
print(f"[{min_date.date()} - {max_date.date()}] DataFrame '{key}', Column '{col}':")
[2016-09-04 - 2018-10-17] DataFrame 'orders', Column 'order_purchase_dt':
[2016-09-15 - 2018-09-03] DataFrame 'orders', Column 'order_approved_dt':
[2016-10-08 - 2018-09-11] DataFrame 'orders', Column 'order_delivered_carrier_dt':
[2016-10-11 - 2018-10-17] DataFrame 'orders', Column 'order_delivered_customer_dt':
[2016-09-30 - 2018-11-12] DataFrame 'orders', Column 'order_estimated_delivery_dt':
[2016-09-19 - 2020-04-09] DataFrame 'items', Column 'shipping_limit_dt':
[2016-10-02 - 2018-08-31] DataFrame 'reviews', Column 'review_creation_dt':
[2016-10-07 - 2018-10-29] DataFrame 'reviews', Column 'review_answer_dt':
Key Observations:
The latest date in order_approved_dt is earlier than in order_purchase_dt.-
Anomalously large maximum date in shipping_limit_dt compared to other temporal variables.
Payment-Order Amount Mismatches#
Checking for orders where payment total differs from order value.
temp_df = (
df_items[['order_id', 'price', 'freight_value']]
.groupby('order_id')
.sum()
.assign(total_price=lambda x: x['price'] + x['freight_value'])
.drop(columns=['price', 'freight_value'])
.reset_index()
.merge(df_payments, on='order_id', how='inner')
.merge(df_orders, on='order_id', how='inner')
.dropna(subset=['payment_value', 'total_price'])
)
temp_df['payment_matches_total'] = temp_df['payment_value'].round(2) == temp_df['total_price'].round(2)
temp_df['payment_matches_total'].value_counts()
payment_matches_total
True 95179
False 7877
Name: count, dtype: int64
Key Observations:
Dataset contains 7,877 orders with payment-amount discrepancies.
tmp_mask = ~temp_df.payment_matches_total
Let’s analyze by payment type.
temp_df.explore.anomalies_by_categories(
custom_mask=tmp_mask
, pct_diff_threshold=-100
, include_columns='tmp_payment_types'
)
| Column | Category | Total | Anomaly | Anomaly Rate | Total % | Anomaly % | % Diff |
|---|---|---|---|---|---|---|---|
| tmp_payment_types | Voucher, Credit Card | 2907 | 2907 | 100.0% | 2.8% | 36.9% | 34.1% |
| tmp_payment_types | Credit Card, Voucher | 2424 | 2424 | 100.0% | 2.4% | 30.8% | 28.4% |
| tmp_payment_types | Voucher | 2540 | 1425 | 56.1% | 2.5% | 18.1% | 15.6% |
| tmp_payment_types | Credit Card, Debit Card | 2 | 2 | 100.0% | 0.0% | 0.0% | 0.0% |
| tmp_payment_types | Debit Card | 1521 | 15 | 1.0% | 1.5% | 0.2% | -1.3% |
| tmp_payment_types | Boleto | 19614 | 69 | 0.4% | 19.0% | 0.9% | -18.2% |
| tmp_payment_types | Credit Card | 74048 | 1035 | 1.4% | 71.9% | 13.1% | -58.7% |
Key Observations:
Payment type analysis shows most mismatches involve voucher payments (likely systemic issue).
Exploring Relationships Between Tables#
Reviewing inter-table connections for future joins and key consistency.
df_orders and df_payments
fron.analyze_join_keys(df_orders, df_payments, "order_id", short_result=False)
============================= Join Analysis Report =============================
Relationship:
- Type: one-to-many (1:N)
- Left total duplicates (keep=False): 0 (0% of rows)
- Right total duplicates (keep=False): 7,407 (7.1% of rows)
Coverage:
- Left-only keys: 1
- Right-only keys: 0
Counts:
- Left keys: 99,441 unique
- Right keys: 99,440 unique
- Common keys: 99,440
Missing Values:
- Left missing: 0 (0%)
- Right missing: 0 (0%)
Join Result Sizes:
- Left table size: 99,441 rows
- Right table size: 103,886 rows
- Inner join size: 103,886 rows
- Left join size: 103,887 rows
- Right join size: 103,886 rows
- Outer join size: 103,887 rows
Key Observations:
Orders table contains 1 order_id missing from payments table.
Let’s look at what this order is.
temp_df = df_orders.merge(df_payments, on='order_id', how='left')
temp_df[temp_df.payment_value.isna()]
| order_id | customer_id | order_status | order_purchase_dt | order_approved_dt | order_delivered_carrier_dt | order_delivered_customer_dt | order_estimated_delivery_dt | tmp_avg_reviews_score | tmp_payment_types | tmp_product_categories | tmp_customer_state | tmp_order_purchase_month | tmp_order_purchase_weekday | tmp_purchase_time_of_day | tmp_is_delayed | tmp_is_delivered | payment_sequential | payment_type | payment_installments | payment_value | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 32133 | bfbd0f9bdef84302105ad712db648a6c | 86dc2ffce2dfff336de2f386a786e574 | Delivered | 2016-09-15 12:16:38 | 2016-09-15 12:16:38 | 2016-11-07 17:11:53 | 2016-11-09 07:47:38 | 2016-10-04 | 1 | Missing in Pays | beleza_saude | SP | September | Thursday | Afternoon | Delayed | Delivered | NaN | NaN | NaN | NaN |
df_orders and df_items
fron.analyze_join_keys(df_orders, df_items, "order_id", short_result=False)
============================= Join Analysis Report =============================
Relationship:
- Type: one-to-many (1:N)
- Left total duplicates (keep=False): 0 (0% of rows)
- Right total duplicates (keep=False): 23,787 (21.1% of rows)
Coverage:
- Left-only keys: 775
- Right-only keys: 0
Counts:
- Left keys: 99,441 unique
- Right keys: 98,666 unique
- Common keys: 98,666
Missing Values:
- Left missing: 0 (0%)
- Right missing: 0 (0%)
Join Result Sizes:
- Left table size: 99,441 rows
- Right table size: 112,650 rows
- Inner join size: 112,650 rows
- Left join size: 113,425 rows
- Right join size: 112,650 rows
- Outer join size: 113,425 rows
Key Observations:
Orders table contains 775 order_ids missing from items table.
We have a payments table. Let’s check if orders missing from items exist in payments.
missing_orders = (df_orders.merge(df_items, on='order_id', how='left')
[lambda x: x['order_item_id'].isna()].order_id.unique()
)
len(missing_orders)
775
df_payments[df_payments.order_id.isin(missing_orders)].order_id.nunique()
775
All these orders are present in the payments table.
Let’s check how many of these orders are canceled.
df_orders[df_orders['order_id'].isin(missing_orders)].order_status.value_counts()
order_status
Unavailable 603
Canceled 164
Created 5
Invoiced 2
Shipped 1
Approved 0
Delivered 0
Processing 0
Name: count, dtype: int64
Key Observations:
These orders are either canceled, unavailable, or just created.
Let’s examine orders with “shipped” status.
df_orders[df_orders['order_id'].isin(missing_orders) & (df_orders.order_status == 'Shipped')]
| order_id | customer_id | order_status | order_purchase_dt | order_approved_dt | order_delivered_carrier_dt | order_delivered_customer_dt | order_estimated_delivery_dt | tmp_avg_reviews_score | tmp_payment_types | tmp_product_categories | tmp_customer_state | tmp_order_purchase_month | tmp_order_purchase_weekday | tmp_purchase_time_of_day | tmp_is_delayed | tmp_is_delivered | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 23254 | a68ce1686d536ca72bd2dadc4b8671e5 | d7bed5fac093a4136216072abaf599d5 | Shipped | 2016-10-05 01:47:40 | 2016-10-07 03:11:22 | 2016-11-07 16:37:37 | NaT | 2016-12-01 | 1 | Boleto | Missing in Items | RS | October | Wednesday | Night | Missing delivery dt | Not Delivered |
df_orders and df_customers
fron.analyze_join_keys(df_orders, df_customers, "customer_id", short_result=False)
============================= Join Analysis Report =============================
Relationship:
- Type: one-to-one (1:1)
- Left total duplicates (keep=False): 0 (0% of rows)
- Right total duplicates (keep=False): 0 (0% of rows)
Coverage:
- Left-only keys: 0
- Right-only keys: 0
Counts:
- Left keys: 99,441 unique
- Right keys: 99,441 unique
- Common keys: 99,441
Missing Values:
- Left missing: 0 (0%)
- Right missing: 0 (0%)
Join Result Sizes:
- Left table size: 99,441 rows
- Right table size: 99,441 rows
- Inner join size: 99,441 rows
- Left join size: 99,441 rows
- Right join size: 99,441 rows
- Outer join size: 99,441 rows
Key Observations:
All is well…
df_orders and df_reviews
fron.analyze_join_keys(df_orders, df_reviews, "order_id", short_result=False)
============================= Join Analysis Report =============================
Relationship:
- Type: one-to-many (1:N)
- Left total duplicates (keep=False): 0 (0% of rows)
- Right total duplicates (keep=False): 1,114 (1.1% of rows)
Coverage:
- Left-only keys: 0
- Right-only keys: 0
Counts:
- Left keys: 99,441 unique
- Right keys: 99,441 unique
- Common keys: 99,441
Missing Values:
- Left missing: 0 (0%)
- Right missing: 0 (0%)
Join Result Sizes:
- Left table size: 99,441 rows
- Right table size: 100,000 rows
- Inner join size: 100,000 rows
- Left join size: 100,000 rows
- Right join size: 100,000 rows
- Outer join size: 100,000 rows
Key Observations:
All is well…
df_items and df_products
fron.analyze_join_keys(df_items, df_products, "product_id", short_result=False)
============================= Join Analysis Report =============================
Relationship:
- Type: many-to-one (N:1)
- Left total duplicates (keep=False): 94,533 (83.9% of rows)
- Right total duplicates (keep=False): 0 (0% of rows)
Coverage:
- Left-only keys: 0
- Right-only keys: 0
Counts:
- Left keys: 32,951 unique
- Right keys: 32,951 unique
- Common keys: 32,951
Missing Values:
- Left missing: 0 (0%)
- Right missing: 0 (0%)
Join Result Sizes:
- Left table size: 112,650 rows
- Right table size: 32,951 rows
- Inner join size: 112,650 rows
- Left join size: 112,650 rows
- Right join size: 112,650 rows
- Outer join size: 112,650 rows
Key Observations:
All is well…
df_items and df_sellers
fron.analyze_join_keys(df_items, df_sellers, "seller_id", short_result=False)
============================= Join Analysis Report =============================
Relationship:
- Type: many-to-one (N:1)
- Left total duplicates (keep=False): 112,141 (99.5% of rows)
- Right total duplicates (keep=False): 0 (0% of rows)
Coverage:
- Left-only keys: 0
- Right-only keys: 0
Counts:
- Left keys: 3,095 unique
- Right keys: 3,095 unique
- Common keys: 3,095
Missing Values:
- Left missing: 0 (0%)
- Right missing: 0 (0%)
Join Result Sizes:
- Left table size: 112,650 rows
- Right table size: 3,095 rows
- Inner join size: 112,650 rows
- Left join size: 112,650 rows
- Right join size: 112,650 rows
- Outer join size: 112,650 rows
Key Observations:
All is well…
df_customers and df_geolocations
fron.analyze_join_keys(df_customers, df_geolocations, left_on = 'customer_zip_code_prefix', right_on = "geolocation_zip_code_prefix", short_result=False)
============================= Join Analysis Report =============================
Relationship:
- Type: many-to-many (N:M)
- Left total duplicates (keep=False): 96,429 (97% of rows)
- Right total duplicates (keep=False): 999,120 (99.9% of rows)
Coverage:
- Left-only keys: 157
- Right-only keys: 4,178
Counts:
- Left keys: 14,994 unique
- Right keys: 19,015 unique
- Common keys: 14,837
Missing Values:
- Left missing: 0 (0%)
- Right missing: 0 (0%)
Join Result Sizes:
- Left table size: 99,441 rows
- Right table size: 1,000,163 rows
- Inner join size: 15,083,455 rows
- Left join size: 15,083,733 rows
- Right join size: 15,115,319 rows
- Outer join size: 15,115,597 rows
Key Observations:
In df_customers table, there are 157 zip_code_prefixes not present in df_geolocations.-
In df_geolocations table, there are 4178 zip_code_prefixes not present in df_customers.
df_sellers and df_geolocations
fron.analyze_join_keys(df_sellers, df_geolocations, left_on = 'seller_zip_code_prefix', right_on = "geolocation_zip_code_prefix", short_result=False)
============================= Join Analysis Report =============================
Relationship:
- Type: many-to-many (N:M)
- Left total duplicates (keep=False): 1,386 (44.8% of rows)
- Right total duplicates (keep=False): 999,120 (99.9% of rows)
Coverage:
- Left-only keys: 7
- Right-only keys: 16,776
Counts:
- Left keys: 2,246 unique
- Right keys: 19,015 unique
- Common keys: 2,239
Missing Values:
- Left missing: 0 (0%)
- Right missing: 0 (0%)
Join Result Sizes:
- Left table size: 3,095 rows
- Right table size: 1,000,163 rows
- Inner join size: 435,087 rows
- Left join size: 435,094 rows
- Right join size: 1,166,434 rows
- Outer join size: 1,166,441 rows
Key Observations:
In df_sellers table, there are 7 zip_code_prefixes not present in df_geolocations.-
In df_geolocations table, there are 16776 zip_code_prefixes not present in df_sellers.
Delete temporary fields.
df_orders = df_orders[[col for col in df_orders.columns if not col.startswith('tmp_')]]
Clear memory of temporary variables.
for var_name in list(globals().keys()):
if var_name.startswith('tmp_'):
del globals()[var_name]