Seller Analysis#
Let’s create a helper function.
def seller_top(metric: str, show_cnt: bool=True, ascending=False):
"""Show Top Customers by Metric"""
cols = ['seller_id', metric]
if show_cnt:
if metric == 'products_cnt':
cols += ['orders_cnt']
else:
cols += ['products_cnt', 'orders_cnt']
display(
df_sellers[cols]
.sort_values(metric, ascending=ascending)
.set_index('seller_id')
.head(10)
)
Number of Products#
Let’s identify the top sellers.
seller_top('products_cnt')
| products_cnt | orders_cnt | |
|---|---|---|
| seller_id | ||
| 6560211a19b47992c3666cc44a7e94c0 | 2,003.00 | 1,826.00 |
| 4a3ca9315b744ce9f8e9374361493884 | 1,952.00 | 1,775.00 |
| 1f50f920176fa81dab994f9023523100 | 1,926.00 | 1,399.00 |
| cc419e0650a3c5ba77189a1882b7556a | 1,719.00 | 1,651.00 |
| da8622b14eb17ae2831f4ac5b9dab84a | 1,548.00 | 1,311.00 |
| 955fee9216a65b617aa5c0531780ce60 | 1,475.00 | 1,264.00 |
| 1025f0e2d44d7041d6cf58b6550e0bfa | 1,420.00 | 910.00 |
| 7c67e1448b00f6e969d365cea6b010ab | 1,356.00 | 974.00 |
| ea8482cd71df3c1969d7b9473ff13abc | 1,188.00 | 1,132.00 |
| 7a67c85e85bb2ce8582c35f2203ad736 | 1,156.00 | 1,146.00 |
Key Observations:
Seller “6560211a19b47992c3666cc44a7e94c0” sold the most products
Let’s see at statistics and distribution of the metric.
df_sellers['products_cnt'].explore.info(
labels=dict(unique_products_cnt='Number of Products')
, title='Distribution of Number of Products Per Seller'
, upper_quantile=0.95
, hist_mode='dual_hist_trim'
)
| Summary | Percentiles | Detailed Stats | Value Counts | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Total | 2.95k (95%) | Max | 2.00k | Mean | 37.33 | 1 | 471 (15%) | |||
| Missing | 148 (5%) | 99% | 437.26 | Trimmed Mean (10%) | 15.06 | 2 | 278 (9%) | |||
| Distinct | 262 (8%) | 95% | 151 | Mode | 1 | 3 | 193 (6%) | |||
| Non-Duplicate | 114 (4%) | 75% | 26 | Range | 2.00k | 4 | 145 (5%) | |||
| Duplicates | 2.83k (92%) | 50% | 8 | IQR | 24 | 5 | 143 (5%) | |||
| Dup. Values | 148 (5%) | 25% | 2 | Std | 120.08 | 6 | 106 (3%) | |||
| Zeros | --- | 5% | 1 | MAD | 10.38 | 7 | 97 (3%) | |||
| Negative | --- | 1% | 1 | Kurt | 119.73 | 8 | 95 (3%) | |||
| Memory Usage | <1 Mb | Min | 1 | Skew | 9.61 | 9 | 79 (3%) | |||
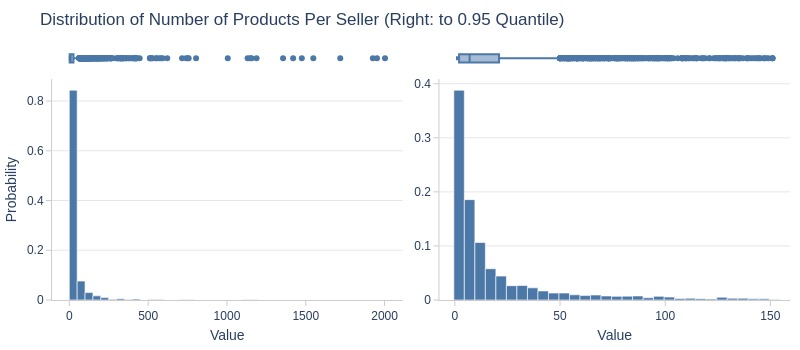
Key Observations:
75% of sellers sold ≤26 products total
Top 5% sold >150 products
Number of Unique Products#
Let’s identify the top sellers.
seller_top('unique_products_cnt')
| unique_products_cnt | products_cnt | orders_cnt | |
|---|---|---|---|
| seller_id | |||
| 4a3ca9315b744ce9f8e9374361493884 | 395.00 | 1,952.00 | 1,775.00 |
| d91fb3b7d041e83b64a00a3edfb37e4f | 309.00 | 527.00 | 526.00 |
| cca3071e3e9bb7d12640c9fbe2301306 | 307.00 | 804.00 | 691.00 |
| fa1c13f2614d7b5c4749cbc52fecda94 | 285.00 | 581.00 | 580.00 |
| 7142540dd4c91e2237acb7e911c4eba2 | 265.00 | 328.00 | 316.00 |
| 6560211a19b47992c3666cc44a7e94c0 | 254.00 | 2,003.00 | 1,826.00 |
| da8622b14eb17ae2831f4ac5b9dab84a | 221.00 | 1,548.00 | 1,311.00 |
| ea8482cd71df3c1969d7b9473ff13abc | 219.00 | 1,188.00 | 1,132.00 |
| 3d871de0142ce09b7081e2b9d1733cb1 | 202.00 | 1,131.00 | 1,064.00 |
| 7c67e1448b00f6e969d365cea6b010ab | 197.00 | 1,356.00 | 974.00 |
Key Observations:
Seller “4a3ca9315b744ce9f8e9374361493884” sold the most unique products
Let’s see at statistics and distribution of the metric.
df_sellers['unique_products_cnt'].explore.info(
labels=dict(unique_products_cnt='Number of Unique Products')
, title='Distribution of Number of Unique Products Per Seller'
, upper_quantile=0.95
, hist_mode='dual_hist_trim'
)
| Summary | Percentiles | Detailed Stats | Value Counts | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Total | 2.95k (95%) | Max | 395 | Mean | 11.39 | 1 | 669 (22%) | |||
| Missing | 148 (5%) | 99% | 126 | Trimmed Mean (10%) | 6.14 | 2 | 414 (13%) | |||
| Distinct | 127 (4%) | 95% | 46 | Mode | 1 | 3 | 285 (9%) | |||
| Non-Duplicate | 49 (2%) | 75% | 10 | Range | 394 | 4 | 207 (7%) | |||
| Duplicates | 2.97k (96%) | 50% | 4 | IQR | 8 | 5 | 166 (5%) | |||
| Dup. Values | 78 (3%) | 25% | 2 | Std | 24.55 | 6 | 123 (4%) | |||
| Zeros | --- | 5% | 1 | MAD | 4.45 | 8 | 102 (3%) | |||
| Negative | --- | 1% | 1 | Kurt | 60.57 | 7 | 101 (3%) | |||
| Memory Usage | <1 Mb | Min | 1 | Skew | 6.49 | 9 | 88 (3%) | |||
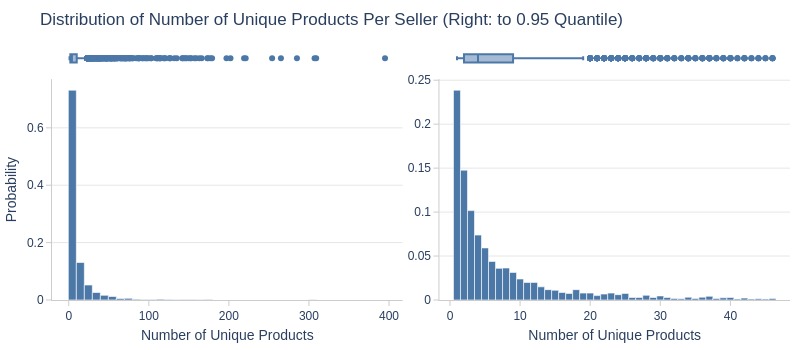
Key Observations:
75% of sellers sold ≤10 unique products
Top 5% sold >45 unique products
Number of Orders#
Let’s identify the top sellers.
seller_top('orders_cnt', show_cnt=False)
| orders_cnt | |
|---|---|
| seller_id | |
| 6560211a19b47992c3666cc44a7e94c0 | 1,826.00 |
| 4a3ca9315b744ce9f8e9374361493884 | 1,775.00 |
| cc419e0650a3c5ba77189a1882b7556a | 1,651.00 |
| 1f50f920176fa81dab994f9023523100 | 1,399.00 |
| da8622b14eb17ae2831f4ac5b9dab84a | 1,311.00 |
| 955fee9216a65b617aa5c0531780ce60 | 1,264.00 |
| 7a67c85e85bb2ce8582c35f2203ad736 | 1,146.00 |
| ea8482cd71df3c1969d7b9473ff13abc | 1,132.00 |
| 4869f7a5dfa277a7dca6462dcf3b52b2 | 1,124.00 |
| 3d871de0142ce09b7081e2b9d1733cb1 | 1,064.00 |
Key Observations:
Seller “6560211a19b47992c3666cc44a7e94c0” participated in the most orders
Let’s see at statistics and distribution of the metric.
df_sellers['orders_cnt'].explore.info(
labels=dict(orders_cnt='Number of Orders')
, title='Distribution of Number of Orders Per Seller'
, upper_quantile=0.95
, hist_mode='dual_hist_trim'
)
| Summary | Percentiles | Detailed Stats | Value Counts | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Total | 2.95k (95%) | Max | 1.83k | Mean | 33.15 | 1 | 517 (17%) | |||
| Missing | 148 (5%) | 99% | 402.78 | Trimmed Mean (10%) | 13.27 | 2 | 307 (10%) | |||
| Distinct | 247 (8%) | 95% | 133 | Mode | 1 | 3 | 209 (7%) | |||
| Non-Duplicate | 112 (4%) | 75% | 22 | Range | 1.82k | 4 | 153 (5%) | |||
| Duplicates | 2.85k (92%) | 50% | 7 | IQR | 20 | 5 | 141 (5%) | |||
| Dup. Values | 135 (4%) | 25% | 2 | Std | 105.79 | 6 | 110 (4%) | |||
| Zeros | --- | 5% | 1 | MAD | 8.90 | 7 | 96 (3%) | |||
| Negative | --- | 1% | 1 | Kurt | 117.00 | 8 | 94 (3%) | |||
| Memory Usage | <1 Mb | Min | 1 | Skew | 9.43 | 9 | 84 (3%) | |||
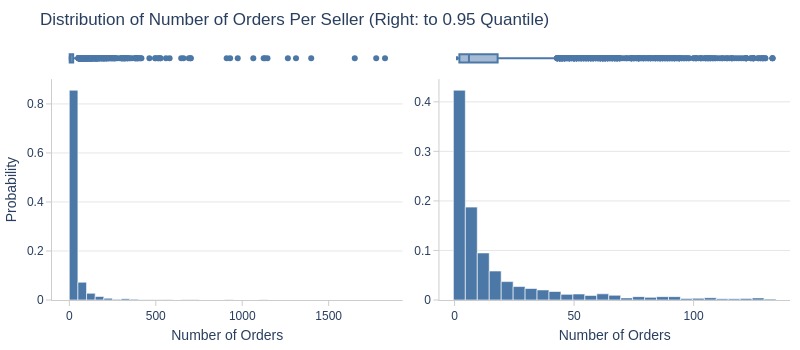
Key Observations:
75% of sellers participated in ≤22 orders
Top 5% participated in ≥130 orders
Total Sales Revenue#
Let’s identify the top sellers.
seller_top('revenue')
| revenue | products_cnt | orders_cnt | |
|---|---|---|---|
| seller_id | |||
| 4869f7a5dfa277a7dca6462dcf3b52b2 | 226,987.93 | 1,148.00 | 1,124.00 |
| 53243585a1d6dc2643021fd1853d8905 | 218,620.44 | 404.00 | 352.00 |
| 4a3ca9315b744ce9f8e9374361493884 | 197,210.82 | 1,952.00 | 1,775.00 |
| fa1c13f2614d7b5c4749cbc52fecda94 | 191,785.04 | 581.00 | 580.00 |
| 7c67e1448b00f6e969d365cea6b010ab | 186,740.04 | 1,356.00 | 974.00 |
| 7e93a43ef30c4f03f38b393420bc753a | 164,582.49 | 321.00 | 318.00 |
| da8622b14eb17ae2831f4ac5b9dab84a | 159,816.87 | 1,548.00 | 1,311.00 |
| 7a67c85e85bb2ce8582c35f2203ad736 | 139,908.68 | 1,156.00 | 1,146.00 |
| 1025f0e2d44d7041d6cf58b6550e0bfa | 138,208.56 | 1,420.00 | 910.00 |
| 955fee9216a65b617aa5c0531780ce60 | 132,138.71 | 1,475.00 | 1,264.00 |
Key Observations:
Seller “4869f7a5dfa277a7dca6462dcf3b52b2” generated the most revenue
Let’s see at statistics and distribution of the metric.
df_sellers['revenue'].explore.info(
labels=dict(revenue='Seller Revenue')
, title='Distribution of Seller Revenue'
, upper_quantile=0.95
, hist_mode='dual_hist_trim'
)
| Summary | Percentiles | Detailed Stats | Value Counts | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Total | 2.95k (95%) | Max | 226.99k | Mean | 4.48k | 59.90 | 7 (<1%) | |||
| Missing | 148 (5%) | 99% | 54.44k | Trimmed Mean (10%) | 1.84k | 69.90 | 7 (<1%) | |||
| Distinct | 2.68k (86%) | 95% | 16.97k | Mode | Multiple | 120 | 7 (<1%) | |||
| Non-Duplicate | 2.52k (81%) | 75% | 3.51k | Range | 226.98k | 119.90 | 6 (<1%) | |||
| Duplicates | 418 (14%) | 50% | 851.10 | IQR | 3.28k | 180 | 6 (<1%) | |||
| Dup. Values | 157 (5%) | 25% | 228.70 | Std | 13.96k | 49.90 | 6 (<1%) | |||
| Zeros | --- | 5% | 49 | MAD | 1.11k | 29.90 | 6 (<1%) | |||
| Negative | --- | 1% | 17.77 | Kurt | 102.35 | 89.90 | 6 (<1%) | |||
| Memory Usage | <1 Mb | Min | 6.50 | Skew | 8.87 | 79.90 | 6 (<1%) | |||
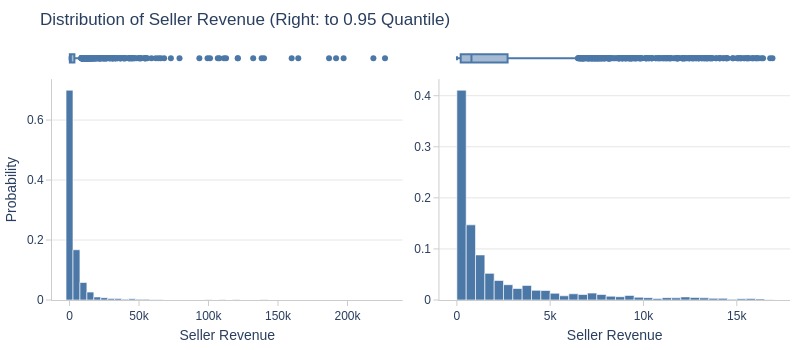
Key Observations:
75% of sellers made ≤3,500 R$
Top 5% made ≥17,000 R$
Number of Products per Order#
Let’s identify the top sellers.
seller_top('avg_prouducts_cnt')
| avg_prouducts_cnt | products_cnt | orders_cnt | |
|---|---|---|---|
| seller_id | |||
| 0b36063d5818f81ccb94b54adfaebbf5 | 15.00 | 15.00 | 1.00 |
| 99a25c39b28a74d1151c35c18d178292 | 6.00 | 6.00 | 1.00 |
| a3b42d266fa8afc874b909422ce88582 | 6.00 | 6.00 | 1.00 |
| c394e193cda3b4225ff2094d32184849 | 5.50 | 11.00 | 2.00 |
| 010da0602d7774602cd1b3f5fb7b709e | 5.00 | 5.00 | 1.00 |
| 8ff38bc3969e67c36c48343a07090f66 | 4.00 | 8.00 | 2.00 |
| fc6295add6f51a0936407ead70c1001d | 4.00 | 4.00 | 1.00 |
| ec8463980a4e0ea9f8517aea1ed0c419 | 4.00 | 8.00 | 2.00 |
| b37c4c02bda3161a7546a4e6d222d5b2 | 3.75 | 15.00 | 4.00 |
| ab27bbbad5239bc31a34709275a70db4 | 3.67 | 11.00 | 3.00 |
Key Observations:
Seller ‘0b36063d5818f81ccb94b54adfaebbf5’ has highest average products per order (single order)
Let’s see at statistics and distribution of the metric.
df_sellers['avg_prouducts_cnt'].explore.info(
labels=dict(avg_prouducts_cnt='Average Number of Products in Order')
, title='Distribution of Average Number of Products in Order per Sellers'
, upper_quantile=0.95
, hist_mode='dual_hist_trim'
)
| Summary | Percentiles | Detailed Stats | Value Counts | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Total | 2.95k (95%) | Max | 15 | Mean | 1.16 | 1 | 1.56k (51%) | |||
| Missing | 148 (5%) | 99% | 3 | Trimmed Mean (10%) | 1.07 | 1.50 | 69 (2%) | |||
| Distinct | 511 (17%) | 95% | 1.82 | Mode | 1 | 2 | 62 (2%) | |||
| Non-Duplicate | 359 (12%) | 75% | 1.14 | Range | 14 | 1.33 | 57 (2%) | |||
| Duplicates | 2.58k (83%) | 50% | 1 | IQR | 0.14 | 1.17 | 42 (1%) | |||
| Dup. Values | 152 (5%) | 25% | 1 | Std | 0.44 | 1.25 | 41 (1%) | |||
| Zeros | --- | 5% | 1 | MAD | 0 | 1.14 | 38 (1%) | |||
| Negative | --- | 1% | 1 | Kurt | 346.25 | 1.11 | 28 (<1%) | |||
| Memory Usage | <1 Mb | Min | 1 | Skew | 13.39 | 1.20 | 28 (<1%) | |||
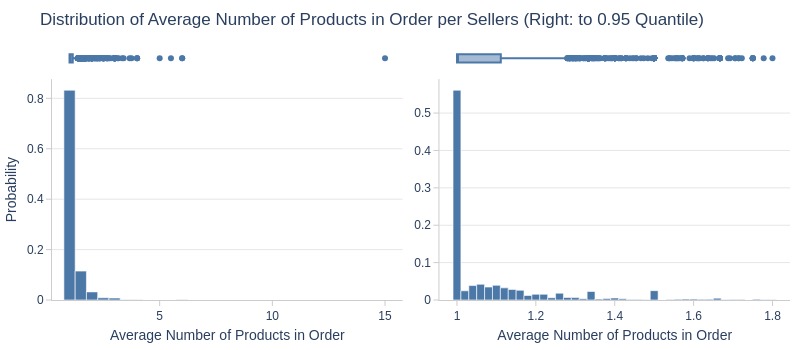
Key Observations:
75% of sellers average 1.14 products per order
Top 1% average ≥3 products
Total Product Value per Order#
Let’s identify the top sellers.
seller_top('avg_order_total_price')
| avg_order_total_price | products_cnt | orders_cnt | |
|---|---|---|---|
| seller_id | |||
| e3b4998c7a498169dc7bce44e6bb6277 | 6,735.00 | 1.00 | 1.00 |
| 80ceebb4ee9b31afb6c6a916a574a1e2 | 6,729.00 | 1.00 | 1.00 |
| ee27a8f15b1dded4d213a468ba4eb391 | 6,499.00 | 1.00 | 1.00 |
| b37c4c02bda3161a7546a4e6d222d5b2 | 6,018.75 | 15.00 | 4.00 |
| 585175ec331ea177fa47199e39a6170a | 3,549.00 | 1.00 | 1.00 |
| abe021b01ba992245271b9aa422032df | 3,360.00 | 2.00 | 2.00 |
| a00824eb9093d40e589b940ec45c4eb0 | 3,133.32 | 3.00 | 3.00 |
| e2a1ac9bf33e5549a2a4f834e70df2f8 | 2,999.89 | 5.00 | 5.00 |
| e908c0f3646e8b60375734a350d95d71 | 2,951.00 | 1.00 | 1.00 |
| d63c73efd41eb002280e7ec831424edb | 2,799.00 | 2.00 | 2.00 |
Key Observations:
Sellers “e3b4998c7a498169dc7bce44e6bb6277” and “80ceebb4ee9b31afb6c6a916a574a1e2” had highest order values (single order each)
Let’s see at statistics and distribution of the metric.
df_sellers['avg_order_total_price'].explore.info(
labels=dict(avg_order_total_price='Average Amount of Products in Order, R$')
, title='Distribution of Average Amount of Products in Order Per Seller'
, upper_quantile=0.95
, hist_mode='dual_hist_trim'
)
| Summary | Percentiles | Detailed Stats | Value Counts | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Total | 2.95k (95%) | Max | 6.74k | Mean | 196.49 | 79.90 | 11 (<1%) | |||
| Missing | 148 (5%) | 99% | 1.61k | Trimmed Mean (10%) | 127.87 | 59.90 | 11 (<1%) | |||
| Distinct | 2.63k (85%) | 95% | 641.15 | Mode | Multiple | 69.90 | 11 (<1%) | |||
| Non-Duplicate | 2.47k (80%) | 75% | 189 | Range | 6.73k | 29.90 | 9 (<1%) | |||
| Duplicates | 466 (15%) | 50% | 105.53 | IQR | 128.72 | 39.90 | 9 (<1%) | |||
| Dup. Values | 157 (5%) | 25% | 60.28 | Std | 369.92 | 49.90 | 8 (<1%) | |||
| Zeros | --- | 5% | 26.17 | MAD | 80.72 | 119.90 | 7 (<1%) | |||
| Negative | --- | 1% | 14.23 | Kurt | 127.40 | 109.90 | 6 (<1%) | |||
| Memory Usage | <1 Mb | Min | 6 | Skew | 9.16 | 90 | 6 (<1%) | |||
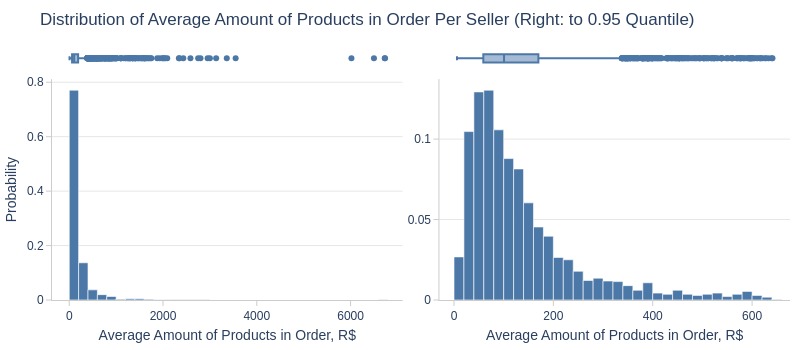
Key Observations:
75% of sellers average ≤189 R$ per order
Top 5% average ≥641 R$
Product Price per Order#
Let’s identify the top sellers.
seller_top('avg_product_price')
| avg_product_price | products_cnt | orders_cnt | |
|---|---|---|---|
| seller_id | |||
| e3b4998c7a498169dc7bce44e6bb6277 | 6,735.00 | 1.00 | 1.00 |
| 80ceebb4ee9b31afb6c6a916a574a1e2 | 6,729.00 | 1.00 | 1.00 |
| ee27a8f15b1dded4d213a468ba4eb391 | 6,499.00 | 1.00 | 1.00 |
| 585175ec331ea177fa47199e39a6170a | 3,549.00 | 1.00 | 1.00 |
| abe021b01ba992245271b9aa422032df | 3,360.00 | 2.00 | 2.00 |
| a00824eb9093d40e589b940ec45c4eb0 | 3,133.32 | 3.00 | 3.00 |
| e2a1ac9bf33e5549a2a4f834e70df2f8 | 2,999.89 | 5.00 | 5.00 |
| e908c0f3646e8b60375734a350d95d71 | 2,951.00 | 1.00 | 1.00 |
| d63c73efd41eb002280e7ec831424edb | 2,799.00 | 2.00 | 2.00 |
| 1444c08e64d55fb3c25f0f09c07ffcf2 | 2,749.00 | 1.00 | 1.00 |
Key Observations:
Seller “e3b4998c7a498169dc7bce44e6bb6277” has highest average product price (single order)
Let’s see at statistics and distribution of the metric.
df_sellers['avg_product_price'].explore.info(
labels=dict(avg_product_price='Average Product Price in Order, R$')
, title='Distribution of Average Product Price in Order Per Seller'
, upper_quantile=0.95
, hist_mode='dual_hist_trim'
)
| Summary | Percentiles | Detailed Stats | Value Counts | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Total | 2.95k (95%) | Max | 6.74k | Mean | 180.46 | 59.90 | 14 (<1%) | |||
| Missing | 148 (5%) | 99% | 1.58k | Trimmed Mean (10%) | 116.39 | 69.90 | 12 (<1%) | |||
| Distinct | 2.58k (83%) | 95% | 595.09 | Mode | 59.90 | 79.90 | 11 (<1%) | |||
| Non-Duplicate | 2.42k (78%) | 75% | 174 | Range | 6.73k | 29.90 | 11 (<1%) | |||
| Duplicates | 516 (17%) | 50% | 97.24 | IQR | 119.77 | 99 | 10 (<1%) | |||
| Dup. Values | 163 (5%) | 25% | 54.23 | Std | 347.44 | 39.90 | 10 (<1%) | |||
| Zeros | --- | 5% | 23.90 | MAD | 76.36 | 119.90 | 8 (<1%) | |||
| Negative | --- | 1% | 12.90 | Kurt | 138.90 | 120 | 8 (<1%) | |||
| Memory Usage | <1 Mb | Min | 6 | Skew | 9.45 | 49.90 | 8 (<1%) | |||
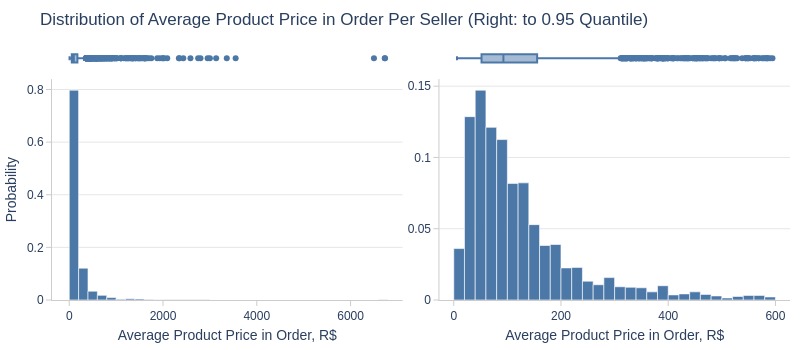
Key Observations:
75% of sellers average ≤174 R$ per product
Top 5% average ≥595 R$
Product Weight#
Let’s identify the top sellers.
seller_top('avg_product_weight_kg')
| avg_product_weight_kg | products_cnt | orders_cnt | |
|---|---|---|---|
| seller_id | |||
| 5d043cd5512d4bd2f88e5ccdd5736c38 | 30.00 | 1.00 | 1.00 |
| d7827b2af99326a03b0ed9c7a24db0d3 | 30.00 | 1.00 | 1.00 |
| 731ef20c231d9a7103a425e83fd91271 | 30.00 | 3.00 | 2.00 |
| 19a7c9f66ffa6452ff4b4c0cca71da27 | 30.00 | 1.00 | 1.00 |
| a99504ac23ed125aaf5302af6cc30af9 | 30.00 | 1.00 | 1.00 |
| a9415cf907dfa12f9ed18693244f5329 | 30.00 | 2.00 | 1.00 |
| 08cdbae123ff67ca4e36d9d641ce0119 | 30.00 | 6.00 | 4.00 |
| ccb83a794700270fde70898fe9ff368b | 30.00 | 12.00 | 12.00 |
| 6fa9202c10491e472dffd59a3e82b2a3 | 30.00 | 3.00 | 3.00 |
| a70e9066dbfd10b6b97a3f54a1356762 | 30.00 | 4.00 | 2.00 |
Key Observations:
Maximum average product weight: 30kg
Let’s see at statistics and distribution of the metric.
df_sellers['avg_product_weight_kg'].explore.info(
labels=dict(avg_product_weight_kg='Average Weight of Products, kg')
, title='Distribution of Average Weight of Products Per Seller'
, upper_quantile=0.95
, hist_mode='dual_hist_trim'
)
| Summary | Percentiles | Detailed Stats | Value Counts | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Total | 2.95k (95%) | Max | 30 | Mean | 2.68 | 0.20 | 69 (2%) | |||
| Missing | 148 (5%) | 99% | 24.05 | Trimmed Mean (10%) | 1.65 | 0.30 | 57 (2%) | |||
| Distinct | 767 (25%) | 95% | 11.14 | Mode | 0.20 | 0.50 | 46 (1%) | |||
| Non-Duplicate | 383 (12%) | 75% | 2.73 | Range | 29.95 | 0.40 | 46 (1%) | |||
| Duplicates | 2.33k (75%) | 50% | 1 | IQR | 2.27 | 0.15 | 46 (1%) | |||
| Dup. Values | 384 (12%) | 25% | 0.46 | Std | 4.35 | 0.60 | 35 (1%) | |||
| Zeros | --- | 5% | 0.19 | MAD | 1.04 | 0.35 | 34 (1%) | |||
| Negative | --- | 1% | 0.10 | Kurt | 14.02 | 0.55 | 33 (1%) | |||
| Memory Usage | <1 Mb | Min | 0.05 | Skew | 3.40 | 0.25 | 31 (1%) | |||
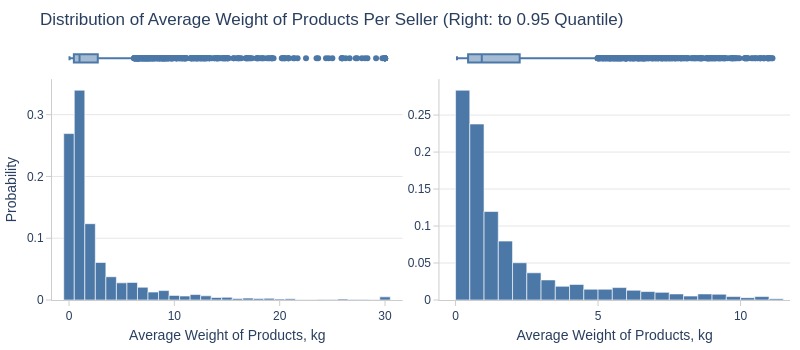
Key Observations:
75% of sellers average ≤2.7kg
Top 5% average ≥11kg
Carrier Handoff Delay#
Let’s identify the top sellers.
seller_top('avg_carrier_delivery_delay_days')
| avg_carrier_delivery_delay_days | products_cnt | orders_cnt | |
|---|---|---|---|
| seller_id | |||
| 586a871d4f1221763fddb6ceefdeb95e | 45.43 | 2.00 | 1.00 |
| 8e670472e453ba34a379331513d6aab1 | 40.15 | 1.00 | 1.00 |
| 20f0aeea30bc3b8c4420be8ced4226c0 | 32.60 | 1.00 | 1.00 |
| e09887ca8c7bf8a4621ce481820414ef | 32.02 | 3.00 | 2.00 |
| 6d04126aba80df143fd038e711b8fd96 | 26.87 | 1.00 | 1.00 |
| 244b04680fdbded0acf5aebd9c92b44a | 23.73 | 2.00 | 2.00 |
| 8d92f3ea807b89465643c219455e7369 | 21.52 | 8.00 | 3.00 |
| 8629a7efec1aab257e58cda559f03ba7 | 19.31 | 1.00 | 1.00 |
| bd4ff04377f974574f7f0bf9d6ce7dde | 19.10 | 1.00 | 1.00 |
| c004e5ea15737026cecaee0447e00b75 | 18.52 | 1.00 | 1.00 |
Key Observations:
Seller “586a871d4f1221763fddb6ceefdeb95e” had maximum carrier handoff delay: 45 days
Let’s see at statistics and distribution of the metric.
df_sellers['avg_carrier_delivery_delay_days'].explore.info(
labels=dict(avg_carrier_delivery_delay_days='Average Carrier Delivery Delay Time, days')
, title='Distribution of Average Carrier Delivery Delay Time Per Seller'
, lower_quantile=0.05
, upper_quantile=0.95
, hist_mode='dual_hist_trim'
)
| Summary | Percentiles | Detailed Stats | Value Counts | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Total | 2.95k (95%) | Max | 45.43 | Mean | -3.04 | -0.39 | 1 (<1%) | |||
| Missing | 149 (5%) | 99% | 9.34 | Trimmed Mean (10%) | -3.24 | -5.22 | 1 (<1%) | |||
| Distinct | 2.95k (95%) | 95% | 1.17 | Mode | Multiple | -3.00 | 1 (<1%) | |||
| Non-Duplicate | 2.95k (95%) | 75% | -2.20 | Range | 79.55 | -3.52 | 1 (<1%) | |||
| Duplicates | 148 (5%) | 50% | -3.28 | IQR | 2.06 | -4.50 | 1 (<1%) | |||
| Dup. Values | 0 (<1%) | 25% | -4.26 | Std | 3.55 | -9.99 | 1 (<1%) | |||
| Zeros | --- | 5% | -6.51 | MAD | 1.53 | -2.93 | 1 (<1%) | |||
| Negative | 2.72k (88%) | 1% | -11.68 | Kurt | 37.56 | -3.35 | 1 (<1%) | |||
| Memory Usage | <1 Mb | Min | -34.12 | Skew | 3.03 | -4.03 | 1 (<1%) | |||
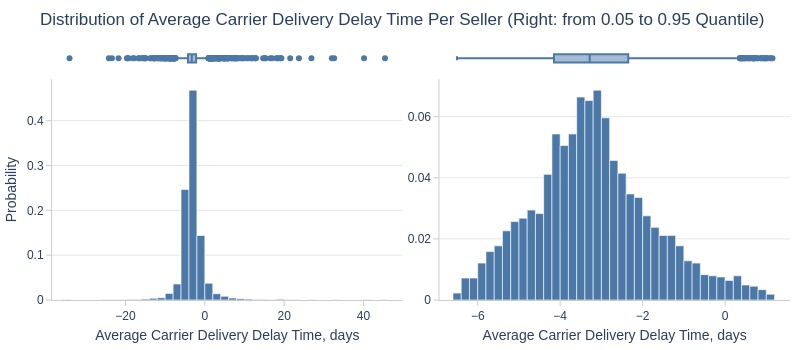
Key Observations:
Top 5% of sellers delivered to carrier ≥6.5 days early
75% delivered ≥2 days early
Bottom 5% delayed ≥1 day