Time Series Analysis#
Order Volume vs. Successful Purchases#
Order Status Distribution
First, we examine order counts by status. Note that for purchase analysis, we’ll focus solely on delivered orders since other statuses don’t represent completed purchases.
labels = pd.Series(dict(
order_purchase_dt = 'Date'
, order_id = 'Number of Orders'
, order_status = 'Order Status'
))
df_orders.viz.line(
x=labels.index[0]
, y=labels.index[1]
, color='order_status'
, agg_func='nunique'
, freq='ME'
, labels=labels
, width=900
, title='Number of Orders by Order Status and Month'
)
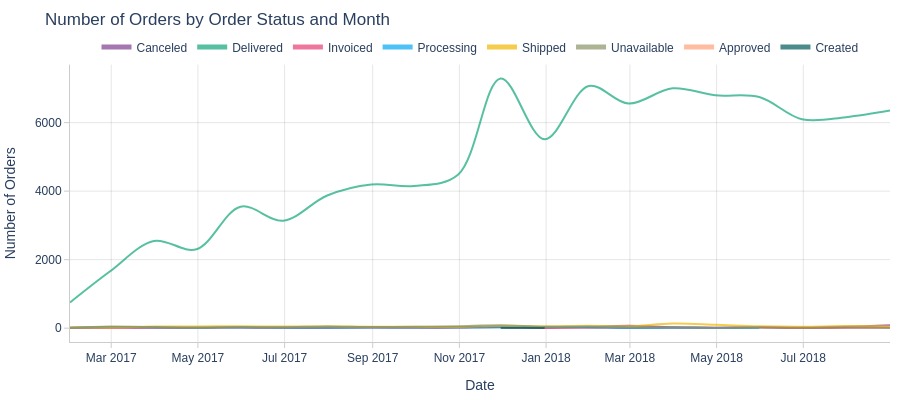
Key Observations:
Delivered orders consistently dominated all other statuses throughout the period.
Let’s look without delivered.
labels = pd.Series(dict(
order_purchase_dt = 'Date'
, order_id = 'Number of Orders'
, order_status = 'Order Status'
))
df_orders[lambda x: x.order_status != 'Delivered'].viz.line(
x=labels.index[0]
, y=labels.index[1]
, color='order_status'
, agg_func='nunique'
, freq='ME'
, labels=labels
, width=900
, markers=True
, title='Number of Orders by Order Status and Month (Without Delivered)'
)
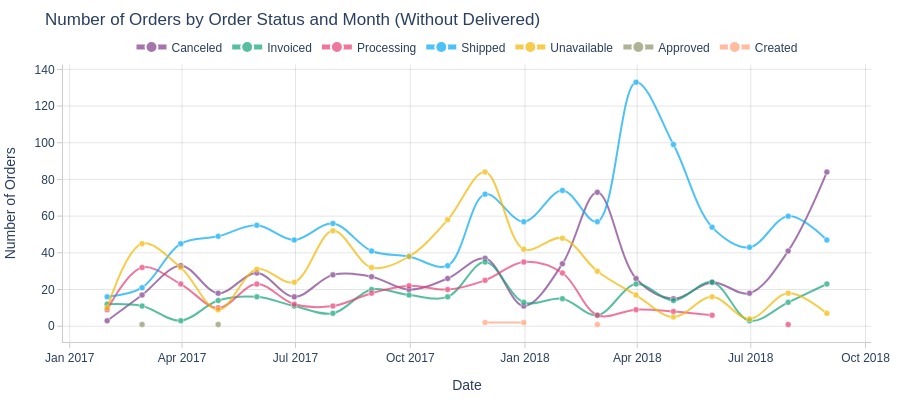
Key Observations:
March-April 2018 saw a sharp spike in orders stuck in “shipped” status
February and August 2018 peaks in “canceled” status
November 2017 “unavailable” peak coincided with Black Friday promotions
As identified during anomaly detection, most of these orders ultimately weren’t delivered for various reasons
Let’s compare the number of orders and sales.
tmp_df_orders_resampled = (
df_orders.resample('ME', on='order_purchase_dt')['order_id']
.nunique()
.reset_index(name='Orders')
)
tmp_tmp_df_resampled = (
df_sales.resample('ME', on='order_purchase_dt')['order_id']
.nunique()
.reset_index(name='Sales')
.merge(tmp_df_orders_resampled, on='order_purchase_dt', how='inner')
)
tmp_tmp_df_resampled['sale_share'] = tmp_tmp_df_resampled['Sales'] / tmp_tmp_df_resampled['Orders']
tmp_tmp_df_resampled_melted = tmp_tmp_df_resampled.melt(id_vars='order_purchase_dt', value_vars=['Orders', 'Sales'], var_name='order_or_sale', value_name='count')
By month
labels = pd.Series(dict(
order_purchase_dt = 'Date'
, count = 'Number of Orders'
, order_or_sale = 'Orders or Sales'
))
tmp_tmp_df_resampled_melted.viz.line(
x=labels.index[0]
, y=labels.index[1]
, color='order_or_sale'
, labels=labels
, category_orders=dict(order_or_sale=['Orders', 'Sales'])
, title='Number of Orders and Sales by Month'
)
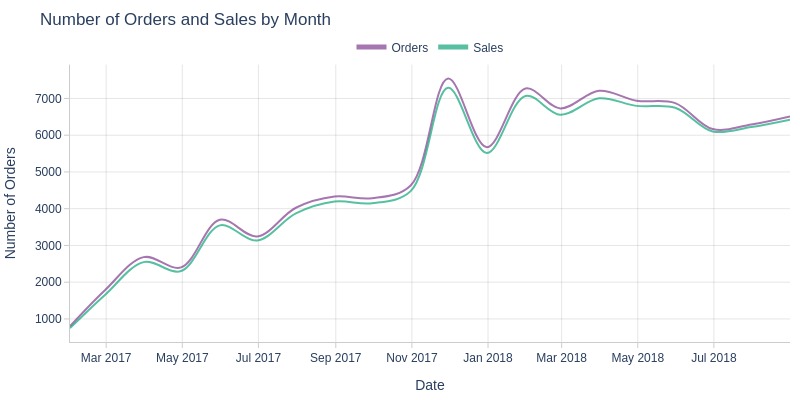
Key Observations:
Stable purchase-to-order ratio maintained month-over-month
Let’s look at conversion to success sale
labels = pd.Series(dict(
order_purchase_dt = 'Date'
, sale_share = 'Conversion to Sale'
))
fig = tmp_tmp_df_resampled.viz.line(
x=labels.index[0]
, y=labels.index[1]
, labels=labels
, title='Conversion to Success Sale by Month'
)
pb.to_slide(fig)
fig.show()
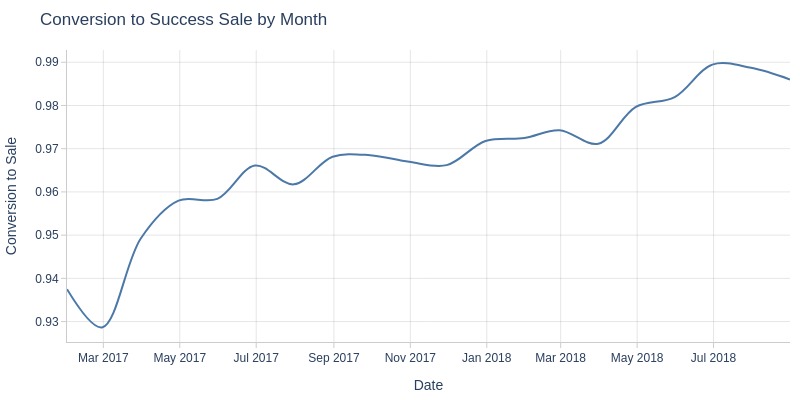
Key Observations:
Consistent month-over-month improvement in successful purchase conversion
Share of Canceled Orders#
pb.configure(
time_column = 'order_purchase_dt'
, time_column_label = 'Date'
, metric = 'target_share'
, metric_label = 'Share of Canceled Orders'
, freq='ME'
)
By month
tmp_tmp_df_res = df_orders['order_status'].preproc.calc_target_category_share(
target_category='Canceled'
, group_columns=['order_purchase_dt']
, resample_freq = 'ME'
)
pb.line(
data_frame=tmp_tmp_df_res
, to_slide=True
)
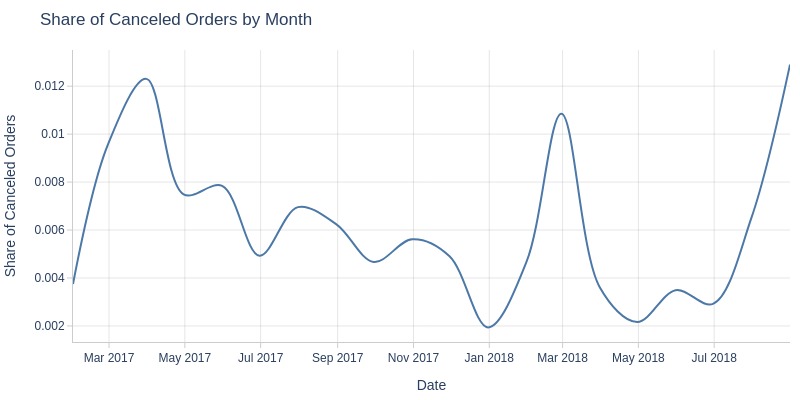
Key Observations:
Fluctuated between 0.2% and 1.2% across months
By Review Score
tmp_tmp_df_res = df_orders['order_status'].preproc.calc_target_category_share(
target_category='Canceled'
, group_columns=['order_purchase_dt', 'order_avg_reviews_score']
, resample_freq = 'ME'
)
pb.line(
data_frame=tmp_tmp_df_res
, color='order_avg_reviews_score'
, to_slide=True
)
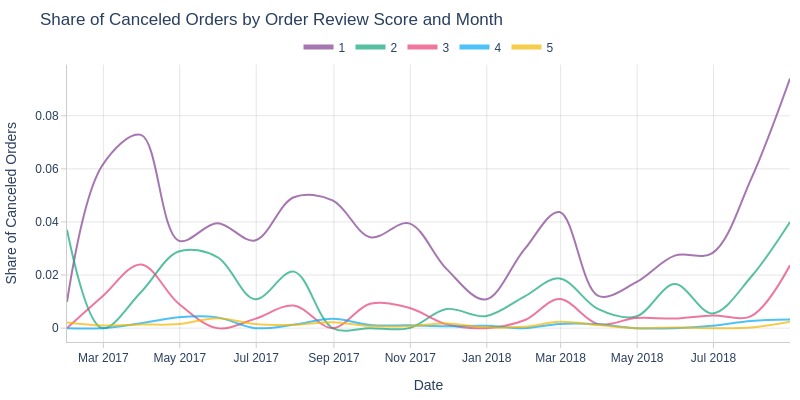
Key Observations:
Orders with score 1 showed significantly higher cancelation rates
Scores 4-5 maintained 0% cancelation rates for most months
del tmp_tmp_df_res
Number of Sales#
pb.configure(
df = df_sales
, time_column = 'order_purchase_dt'
, time_column_label = 'Date'
, metric = 'order_id'
, metric_label = 'Number of Sales'
, agg_func = 'nunique'
, freq = 'ME'
)
By Day and Month
for freq in ['D', 'ME']:
pb.line_resample(
freq=freq
, to_slide=True if freq == 'ME' else False
).show()
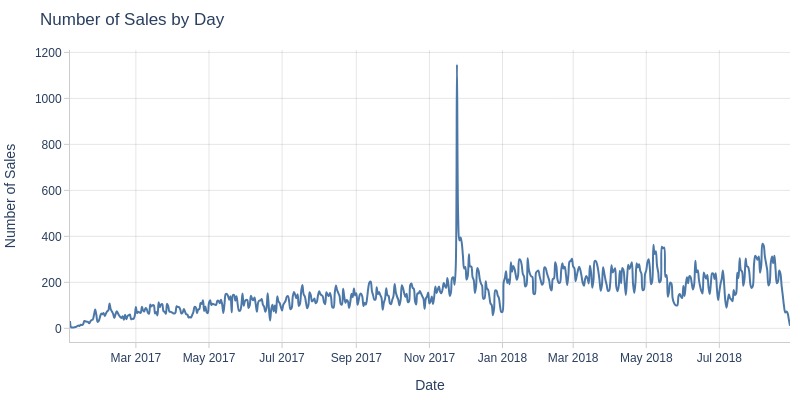
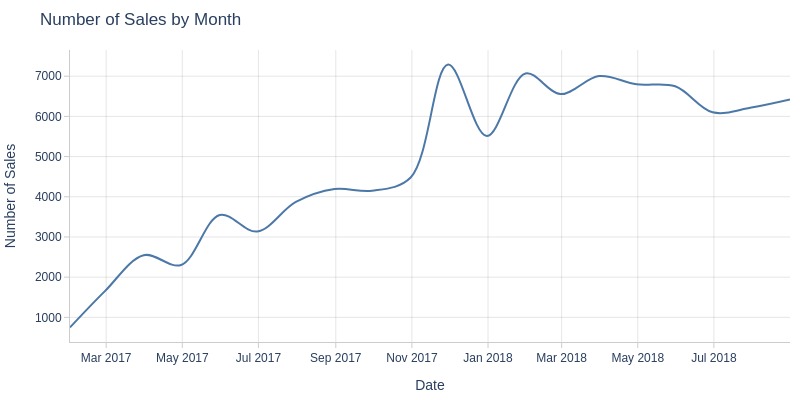
Key Observations:
There was an anomalous peak in sales volume on November 24, 2017 - Black Friday
The number of sales steadily increased until November 2017, reaching a peak of approximately 7.3k orders per month. After that, sales stabilized and fluctuated in the range of 6-7k orders per month.
Monthly Growth
pb.period_change(
period='mom'
, to_slide=True
)
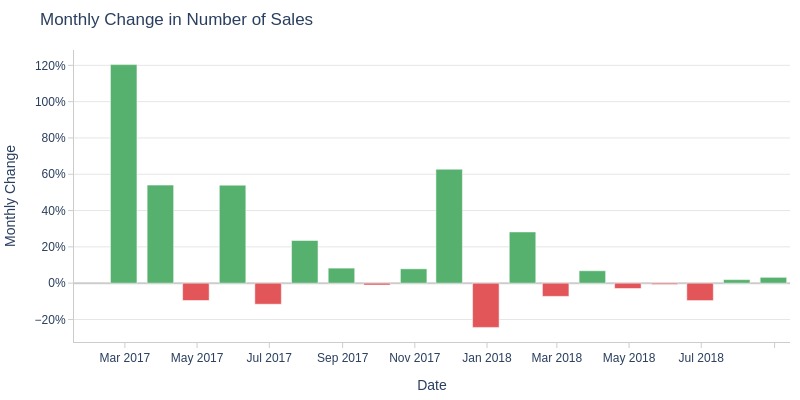
Key Observations:
The most significant decline in sales (more than 5% month-over-month) was observed in April, June, and December 2017, as well as in February and June 2018.
Conversely, the most pronounced spikes in growth (exceeding 50%) were recorded in February, March, and May 2017, and in November 2018 (Black Friday).
This indicates strong demand volatility in specific months, possibly linked to seasonality or marketing activities.
By Time of Day
pb.line_resample(
color='purchase_time_of_day'
, to_slide=True
)
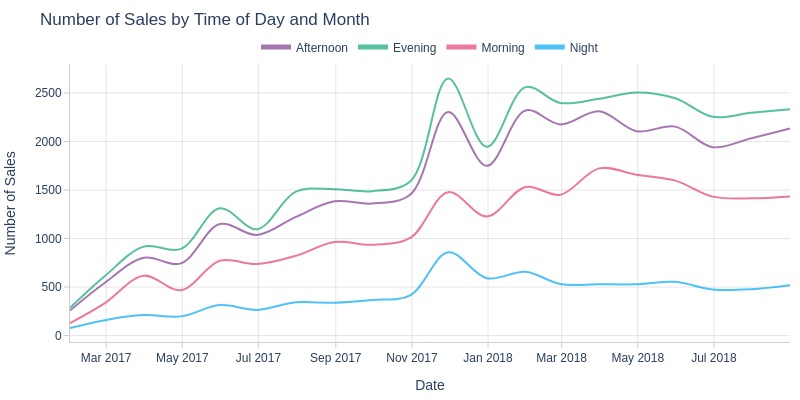
Key Observations:
Nighttime sales are on average lower than other times of day
The highest sales volume occurs in the evening
By Day of Week
Analyzing trends by month would be incorrect, as one month might have 4 Mondays while another has 5.
Therefore, we’ll examine weekly patterns.
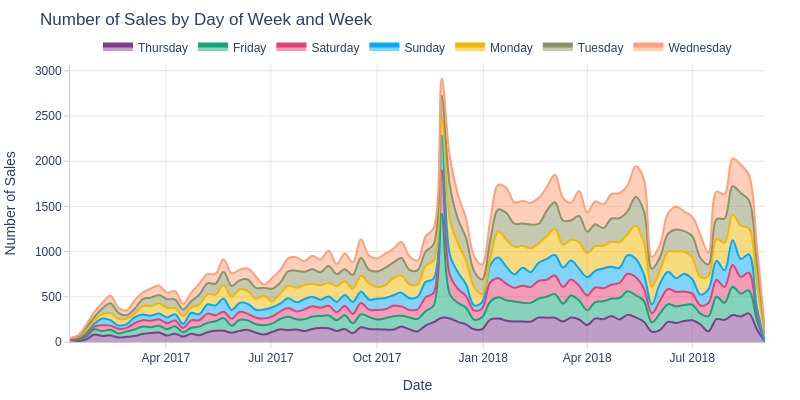
pb.area_resample(color='purchase_weekday', freq='W', title='Number of Sales by Day of Week and Week')
pb.heatmap(x=pd.Grouper(key=pb.time_column, freq='W')
, y='purchase_weekday'
, text_auto=False
, title='Number of Sales by Day of Week and Week'
)
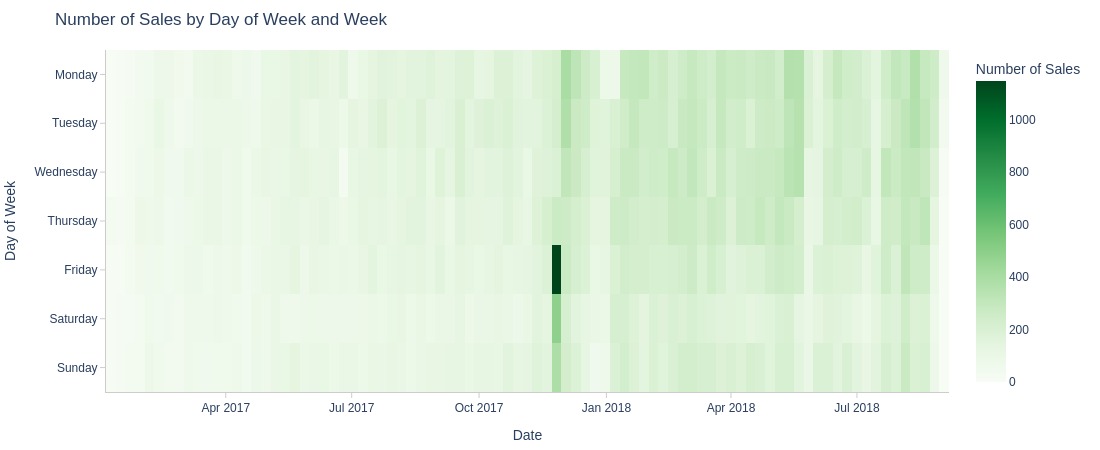
Key Observations:
There’s no significant difference in sales by day of week, though weekends show slightly lower volumes
The peak value occurred on Black Friday
By Weekday vs Weekend
pb.line_resample(color='purchase_day_type')
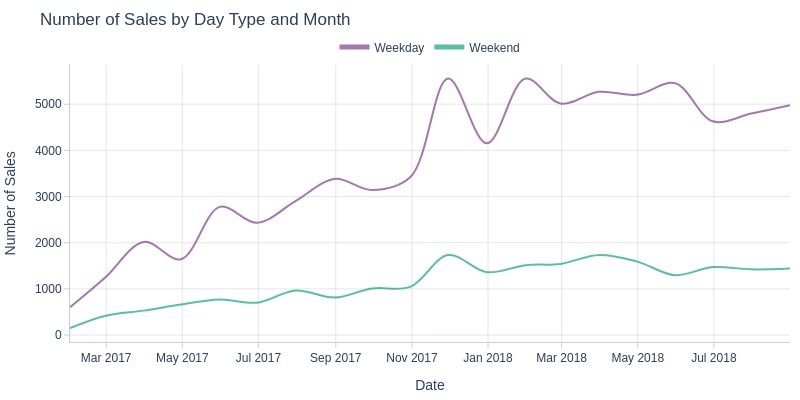
Key Observations:
Weekday sales grew faster than weekend sales
By Review Score
pb.line_resample(
color='order_avg_reviews_score'
, to_slide=True
)
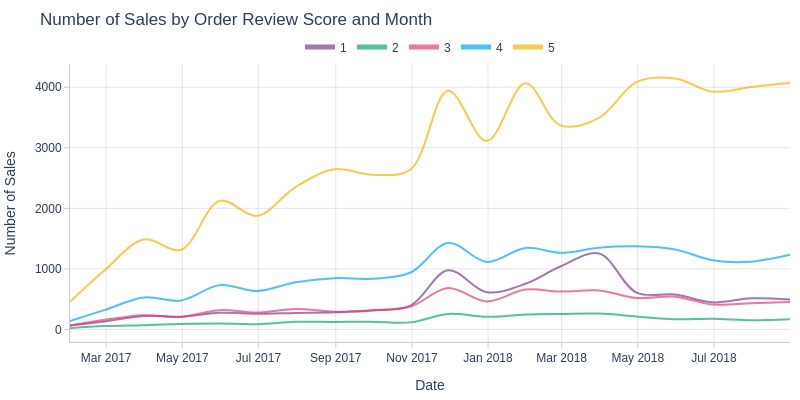
Key Observations:
Orders with 5-star reviews significantly outnumber others each month
Orders with 2-star reviews are consistently the least common
5-star orders continued growing in 2018 despite overall sales plateauing, due to declining 1-star orders
By Delivery Delay Status
pb.line_resample(
color='is_delayed'
, to_slide=True
)
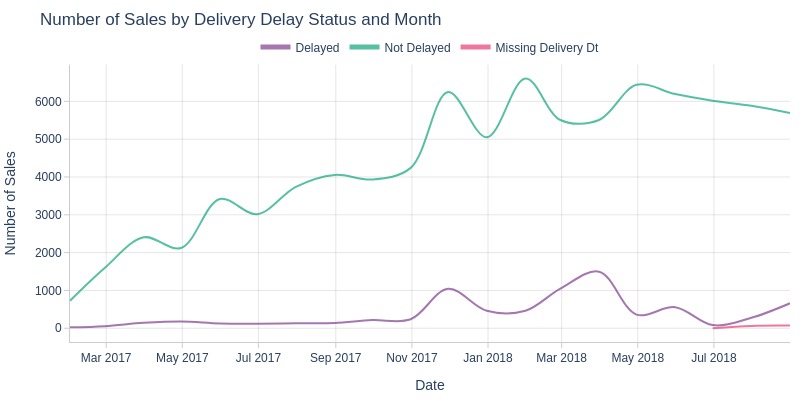
Key Observations:
Delayed orders aren’t increasing proportionally with total orders - a positive trend
Peak months for delays: November 2017 (Black Friday) and March 2018
By Payment Category
pb.line_resample(color='order_total_payment_cat')
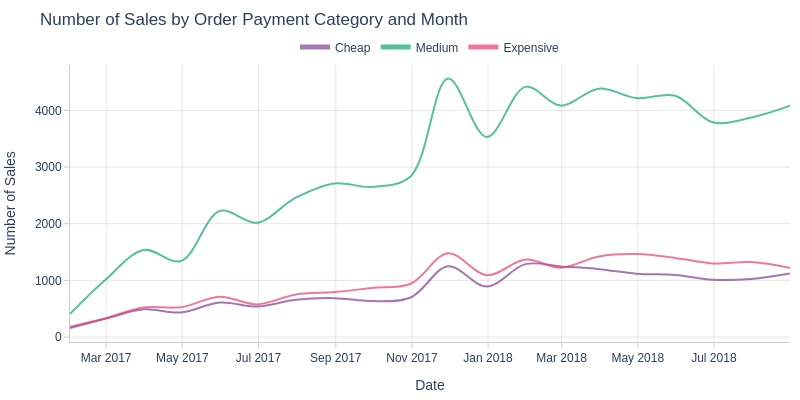
Key Observations:
The overall sales trend remains consistent across cheap, medium, and expensive orders
By Order Weight Category
pb.line_resample(color='order_total_weight_cat')
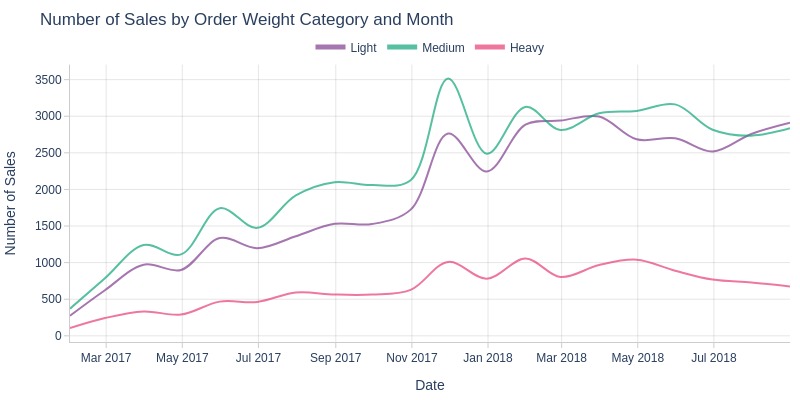
Key Observations:
The overall sales trend remains consistent across light, medium, and heavy orders
By Delivery Time Category
pb.line_resample(
color='delivery_time_days_cat'
, to_slide=True
)
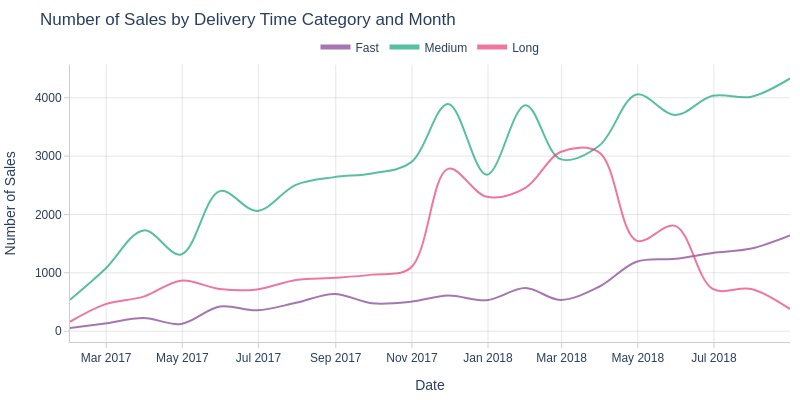
Key Observations:
November 2017 saw a sharp spike in long-delivery orders (likely Black Friday effect)
High volumes of long deliveries persisted until March 2018
By August 2018, long deliveries became less common than medium and fast ones
By Presence of Installment Payments
pb.line_resample(color='order_has_installment')
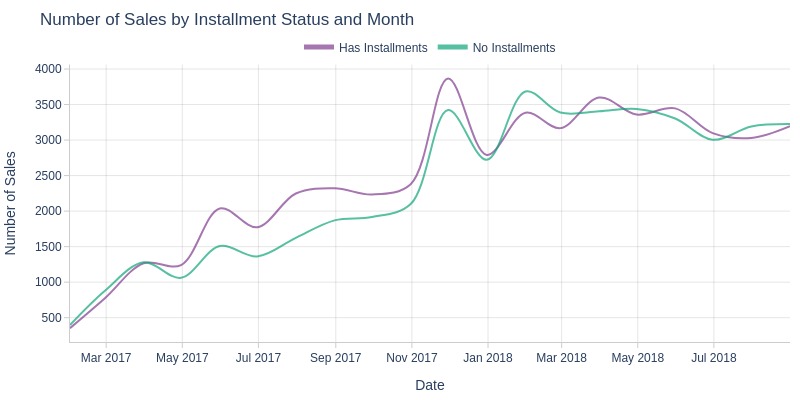
Key Observations:
Before 2018, non-installment orders lagged behind installment ones, but volumes equalized in 2018
By Top Customer States
pb.line_resample(
color='customer_state'
, to_slide=True
)
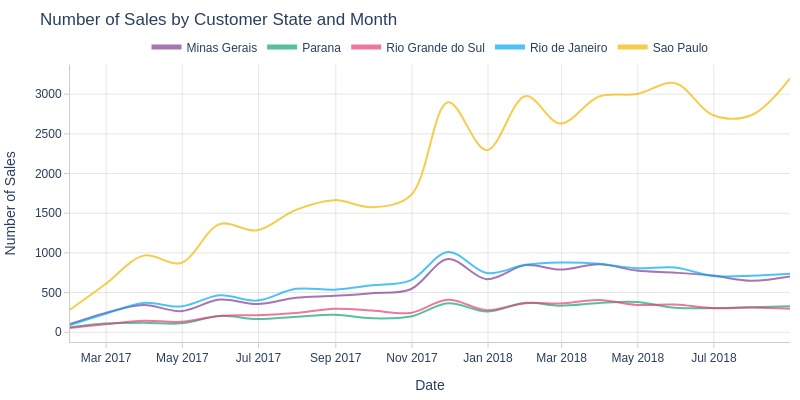
Key Observations:
São Paulo state consistently led in sales volume throughout the period
Unlike other states, São Paulo maintained stable monthly sales in 2018
Rio de Janeiro and Minas Gerais ranked second and third respectively
By Top Customer Cities
pb.line_resample(
color='customer_city'
, to_slide=True
)
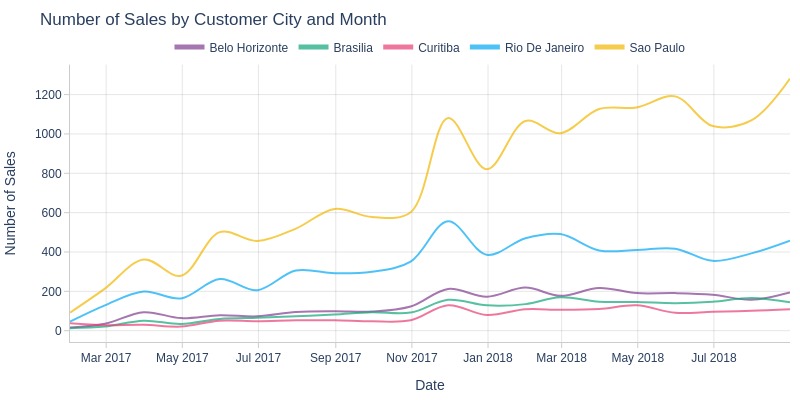
Key Observations:
São Paulo city consistently had the highest sales volume
Rio de Janeiro ranked second
Unlike other cities, São Paulo showed monthly sales growth in 2018
Sales Amount#
pb.configure(
df = df_sales
, time_column = 'order_purchase_dt'
, time_column_label = 'Date'
, metric = 'total_payment'
, metric_label = 'Sales Amount, R$'
, metric_label_for_distribution = 'Order Value, R$'
, title_base = 'Sales Amount'
, agg_func = 'sum'
, freq='ME'
)
By Day and Month
pb.box(mode='time_series', freq='M').show()
pb.box(mode='time_series', freq='M', upper_quantile=0.95).show()
for freq in ['D', 'ME']:
pb.line_resample(
freq=freq
, to_slide=True if freq == 'ME' else False
).show()
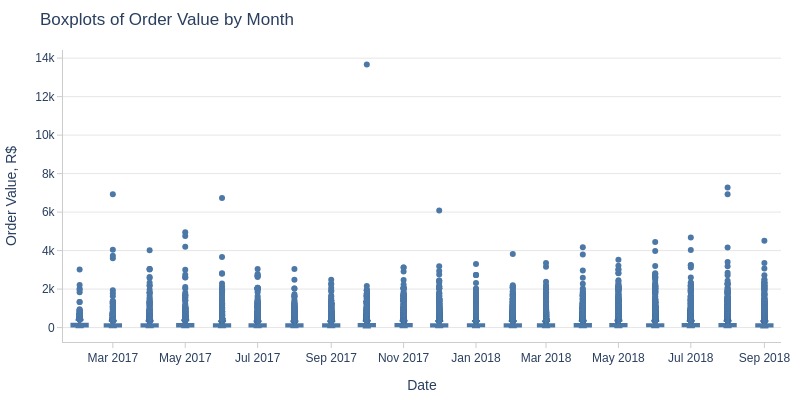
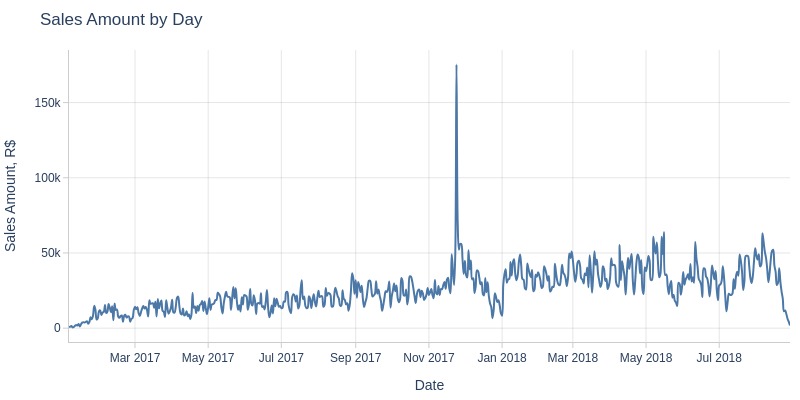
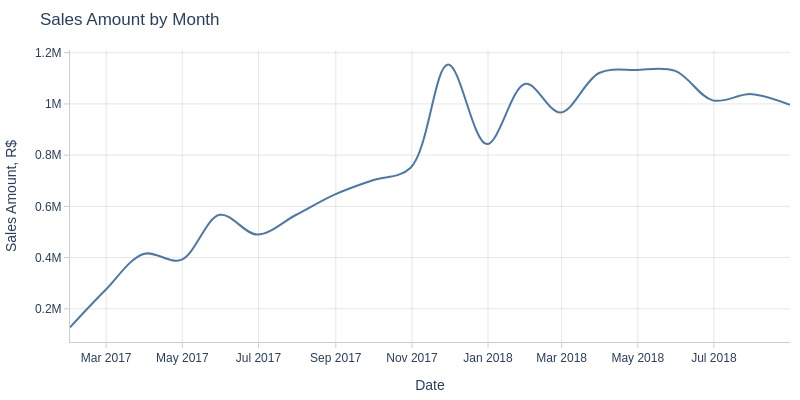
Key Observations:
There was an anomalous peak in sales revenue on November 24, 2017 - Black Friday
Monthly sales revenue grew until 2018, then stabilized at 1-1.2 million R$ per month
Monthly Growth
pb.period_change(
period='mom'
, to_slide=True
)
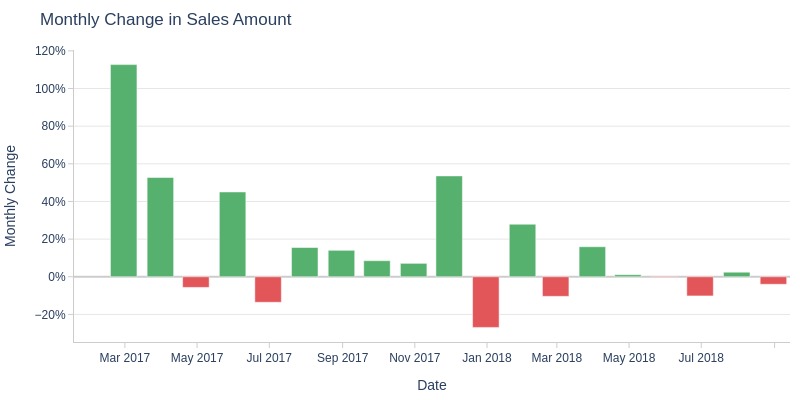
Key Observations:
Sales revenue dropped by more than 5% month-over-month in April, June, and December 2017, and February and June 2018
By Time of Day
pb.line_resample(color='purchase_time_of_day', to_slide=True)
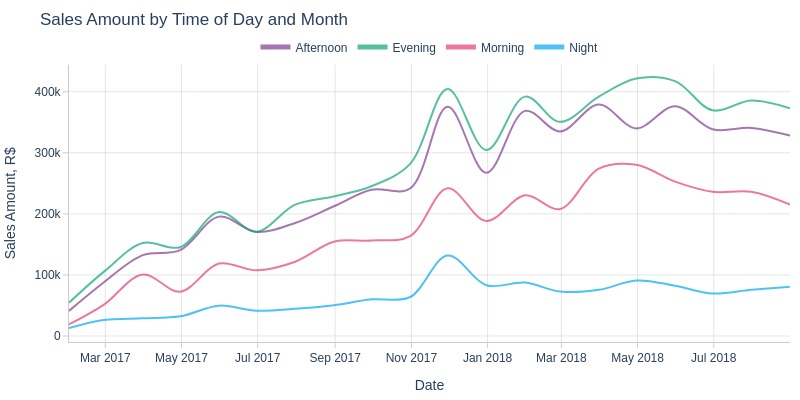
Key Observations:
Nighttime sales revenue is on average lower than other times
Highest revenue occurs in evenings and afternoons
By Day of Week
pb.area_resample(freq='W', color='purchase_weekday', title='Sales Amount by Day of the Week and Week')
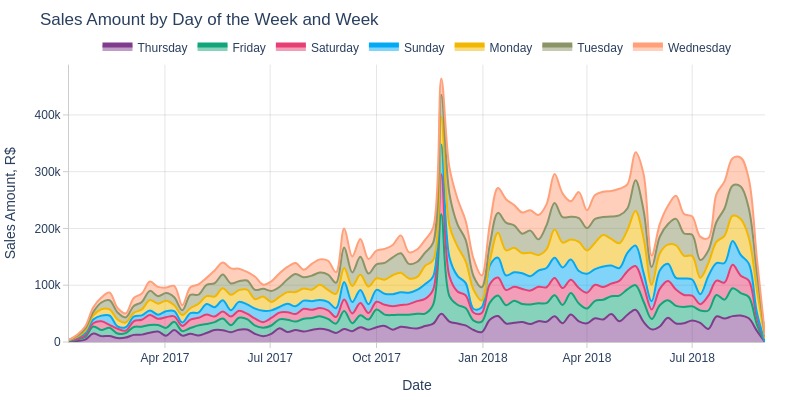
pb.heatmap(x=pd.Grouper(key=pb.time_column, freq='W')
, y='purchase_weekday'
, text_auto=False
, title='Sales Amount by Day of the Week and Week'
)
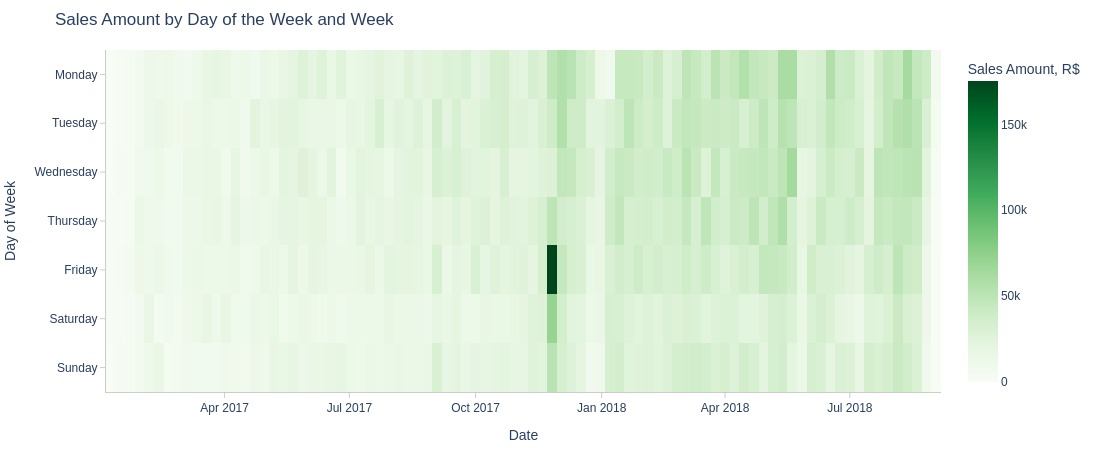
Key Observations:
No significant difference in revenue by day of week, though weekends are slightly lower
By Weekday vs Weekend
pb.line_resample(color='purchase_day_type')
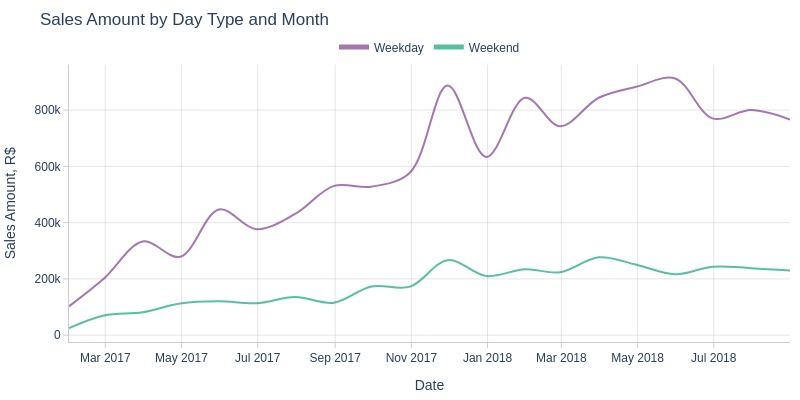
Key Observations:
Weekday revenue grew faster than weekend revenue
By Review Score
pb.line_resample(color='order_avg_reviews_score', to_slide=True)
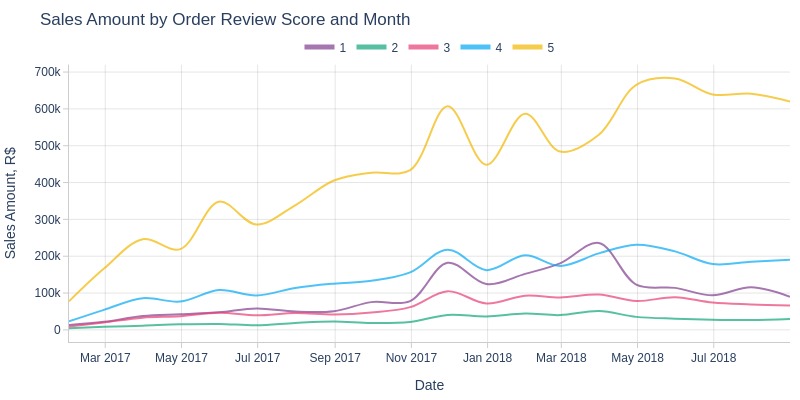
Key Observations:
Orders with 5-star reviews generate significantly more revenue each month
Orders with 2-star reviews consistently generate the least revenue
Black Friday saw the strongest revenue spikes for both 5-star and 1-star orders
5-star order revenue continued growing in 2018 despite overall stagnation, partly due to declining 1-star order revenue
By Whether the Order is Delayed or Not
pb.line_resample(color='is_delayed', to_slide=True)
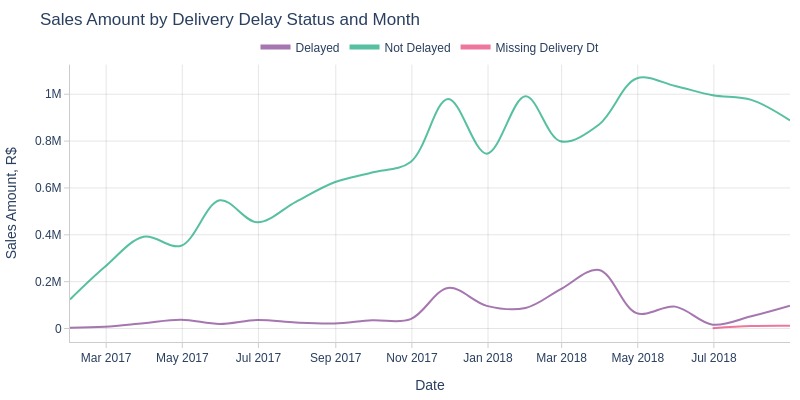
Key Observations:
Peak months for delayed order revenue: November 2017 (Black Friday) and March 2018
By Payment Category
pb.line_resample(color='order_total_payment_cat')
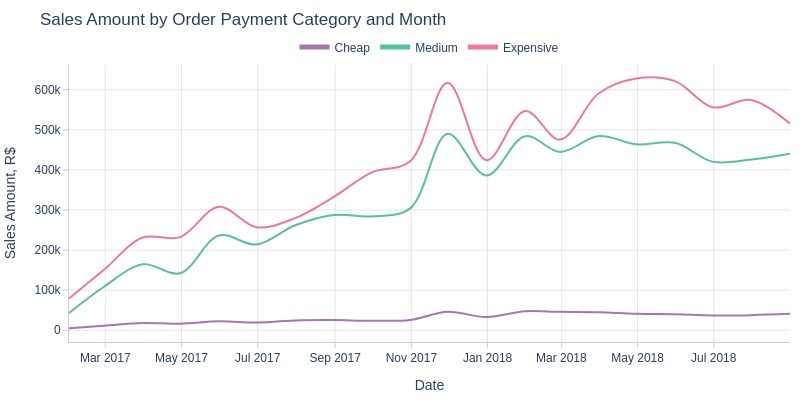
Key Observations:
The overall revenue trend remains consistent across cheap, medium, and expensive orders
By Order Weight Category
pb.line_resample(color='order_total_weight_cat')
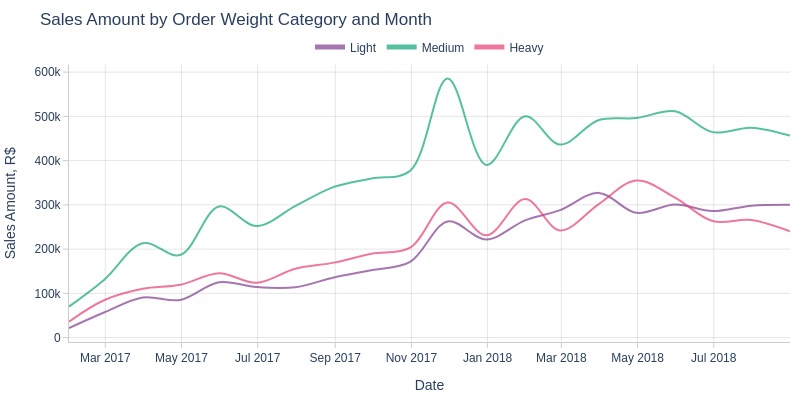
Key Observations:
The overall revenue trend remains consistent across light, medium, and heavy orders
By Delivery Time Category
pb.line_resample(color='delivery_time_days_cat', to_slide=True)
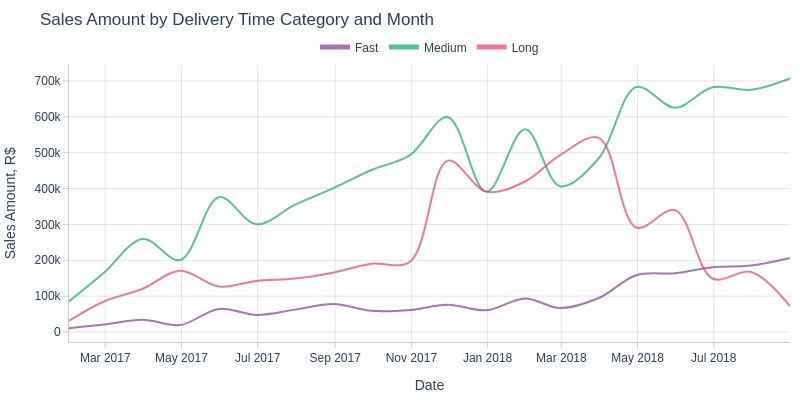
Key Observations:
November 2017 saw a sharp spike in revenue from long-delivery orders (likely Black Friday effect)
High volumes of long deliveries persisted until April 2018 (unexplained by Black Friday)
The subsequent sharp decline in long deliveries wasn’t matched by growth in other categories
This may explain why overall revenue stopped growing in 2018
By Presence of Installment Payments
pb.line_resample(color='order_has_installment', to_slide=True)
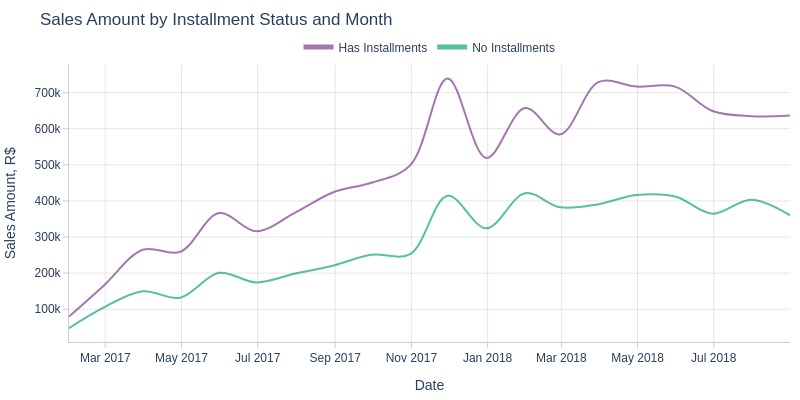
Key Observations:
Installment orders consistently generated higher revenue than non-installment orders
By Top Customer States
pb.line_resample(color='customer_state', to_slide=True)
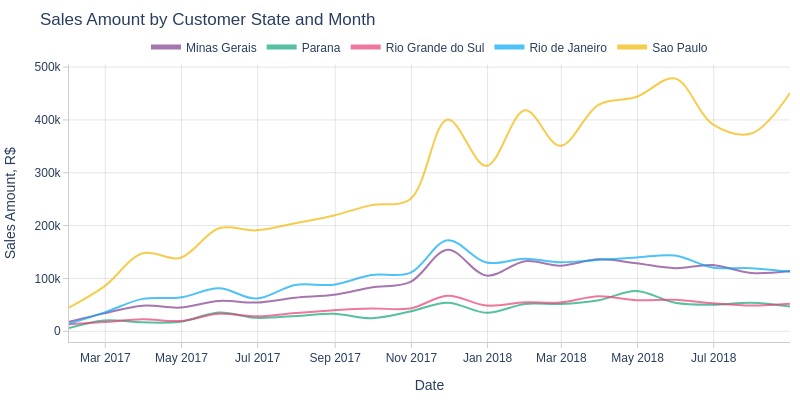
Key Observations:
São Paulo state consistently led in sales revenue
Rio de Janeiro and Minas Gerais ranked second and third respectively
By Top Customer Cities
pb.line_resample(color='customer_city', to_slide=True)
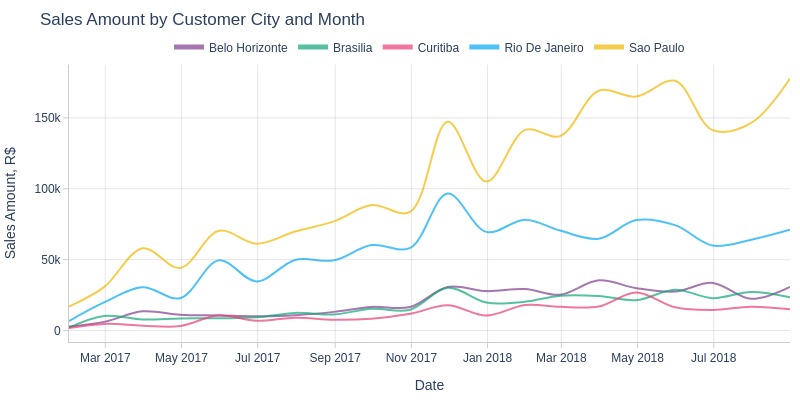
Key Observations:
São Paulo city consistently generated the highest sales revenue
Rio de Janeiro ranked second
By Payment Type
pb.line_resample(color='order_payment_types', to_slide=True)
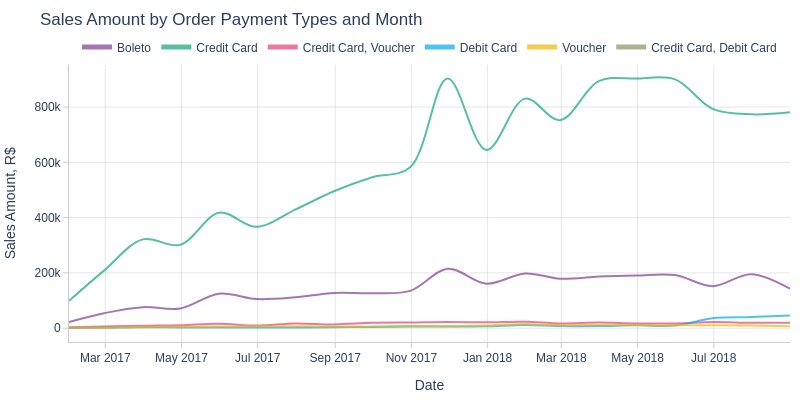
Key Observations:
Credit card payments consistently generated the highest revenue, with boleto second
Debit card payment revenue grew from June 2018
By Product Category
pb.line_resample(color='order_general_product_categories', to_slide=True)
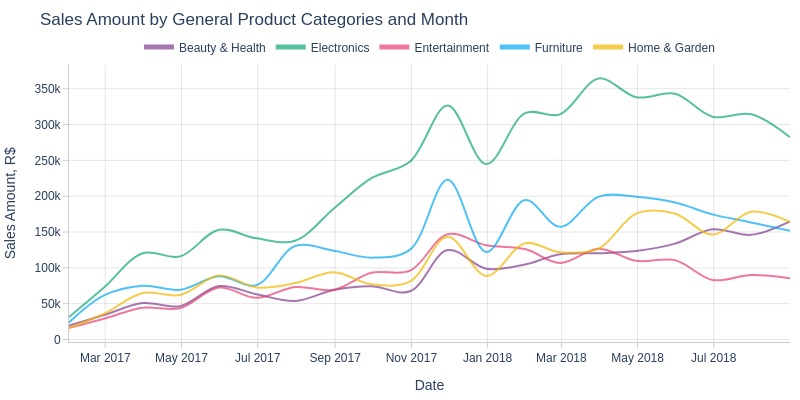
Key Observations:
Electronics consistently generated the highest revenue, followed by furniture
‘Beauty/Health’ and ‘Home/Garden’ categories continued growing in 2018 while others slowed or declined
Average Order Value#
pb.configure(
df = df_sales
, time_column = 'order_purchase_dt'
, time_column_label = 'Date'
, metric = 'total_payment'
, metric_label = 'Average Order Value, R$'
, metric_label_for_distribution = 'Order Value, R$'
, title_base = 'Average Order Value'
, agg_func = 'mean'
, freq='ME'
)
By Day and Month
for freq in ['D', 'ME']:
pb.line_resample(
freq=freq
, to_slide=True if freq == 'ME' else False
).show()
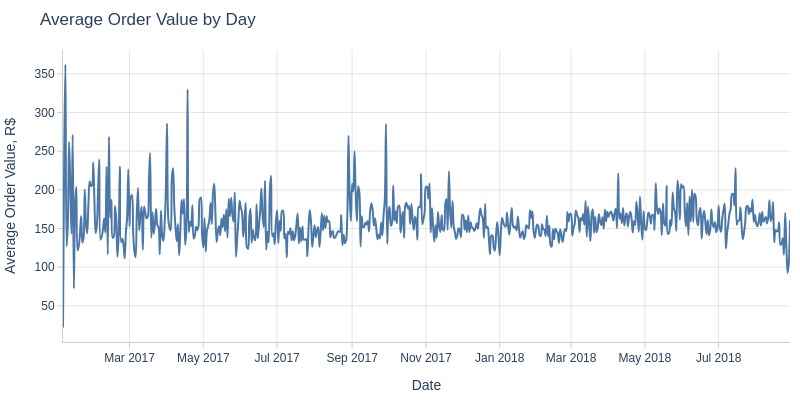
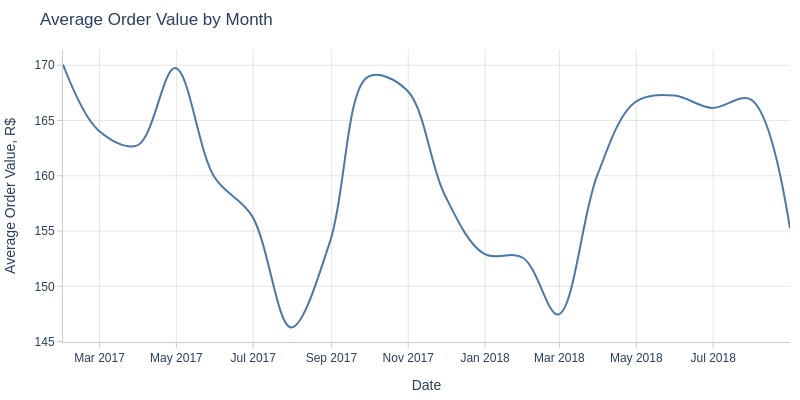
Key Observations:
The average order value fluctuates between 100-250 R$ daily
Black Friday didn’t show a spike in average order value
Monthly average order value remains stable at 150-170 R$ without growth
Monthly Growth
pb.period_change(period='mom', to_slide=True)
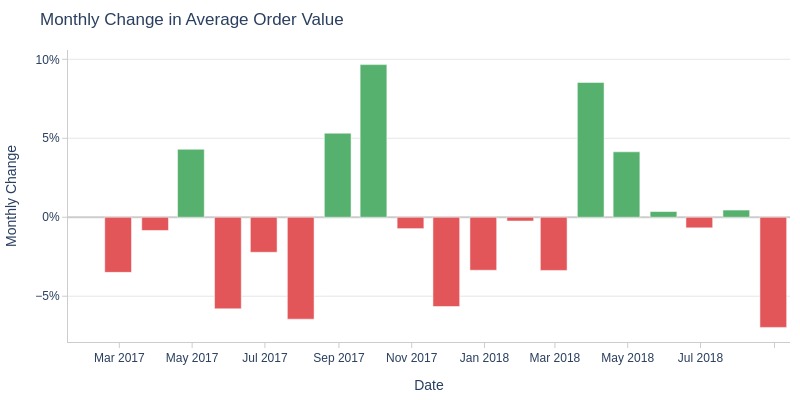
Key Observations:
Average order value dropped >5% month-over-month in May, July, November 2017 and August 2018
By Time of Day
pb.line_resample(color='purchase_time_of_day')
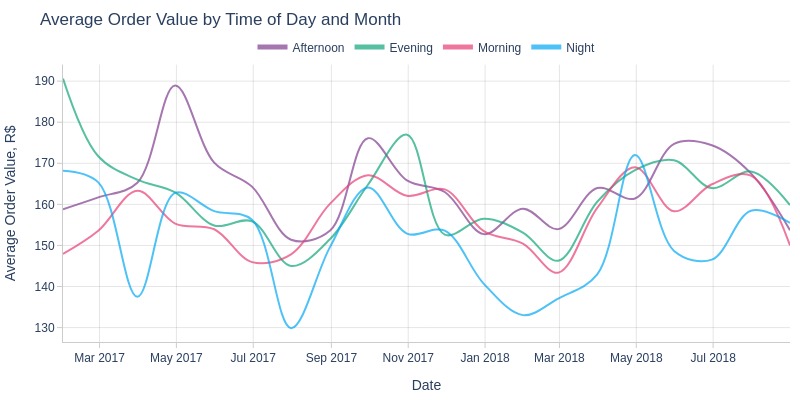
Key Observations:
No significant difference in average order value by time of day
Nighttime averages are slightly lower
By Whether the Order is Delayed or Not
pb.line_resample(color='is_delayed')
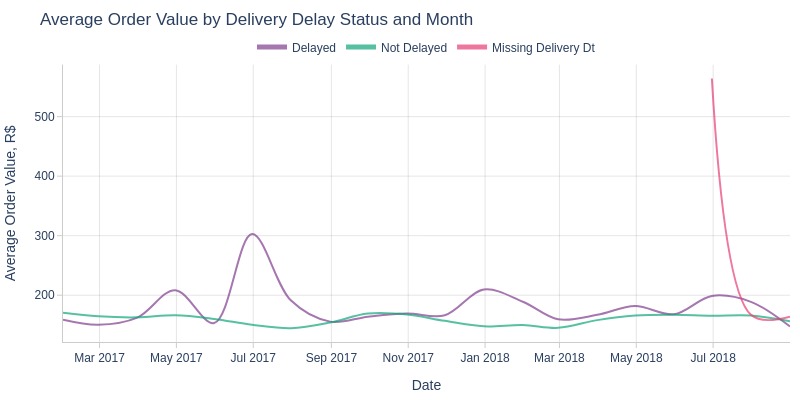
Key Observations:
June 2017 saw a major peak in average value for delayed orders
Smaller peaks occurred in April/December 2017 and January/June 2018
By Order Weight Category
pb.line_resample(color='order_total_weight_cat')
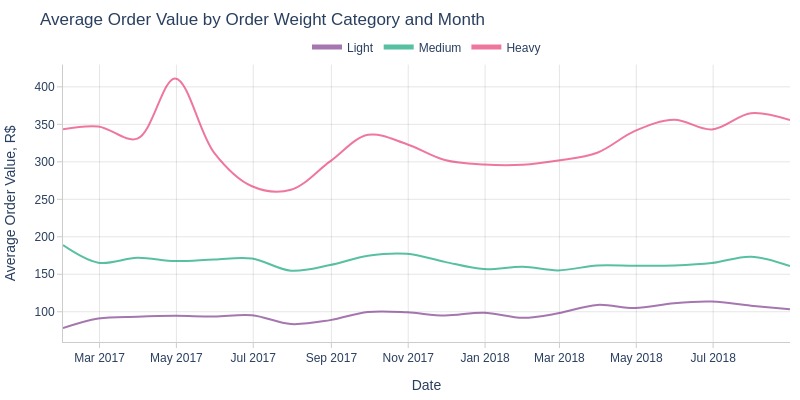
Key Observations:
Heavy orders show more variability in average value over time
Consistently: heavy > medium > light order values
April-July 2017 saw significant decline in heavy order values, followed by fluctuating growth
By Delivery Time Category
pb.line_resample(color='delivery_time_days_cat', to_slide=True)
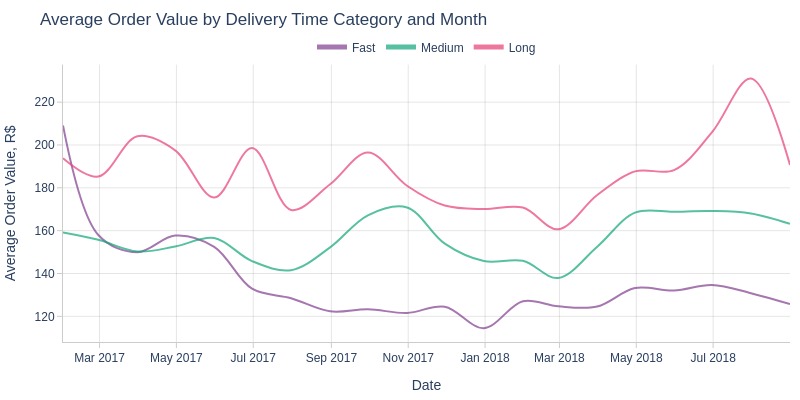
Key Observations:
For most months, expensive items had longer delivery times
By Presence of Installment Payments
pb.line_resample(color='order_has_installment', to_slide=True)
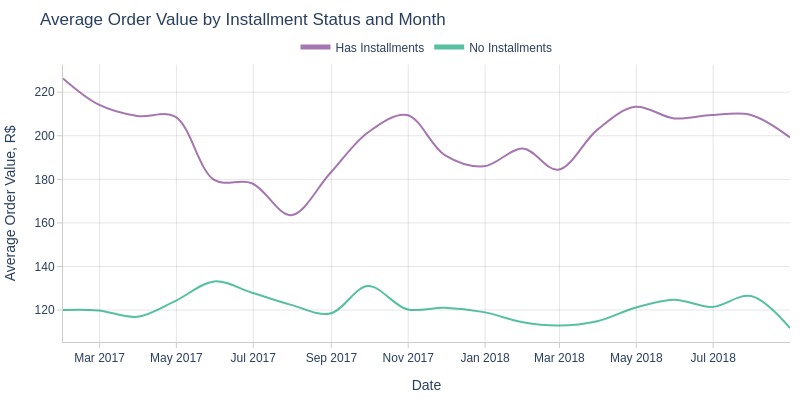
Key Observations:
Installment orders consistently show higher average values (logical as customers can afford more)
Installment order values fluctuate more over time
Pre-July 2017: steady decline in installment order values
Post-July 2017: fluctuating growth
By Review Score
pb.line_resample(color='order_avg_reviews_score', to_slide=True)
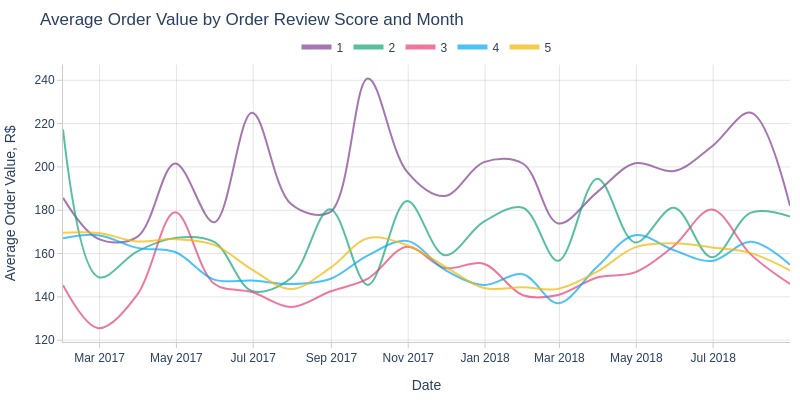
Key Observations:
Orders with 1-star reviews typically had higher average values
Orders with 2-star reviews often had higher values than 3/4/5-star orders
Conclusion: lower ratings were more common for higher-value orders
By Top Customer Cities
pb.line_resample(color='customer_city')
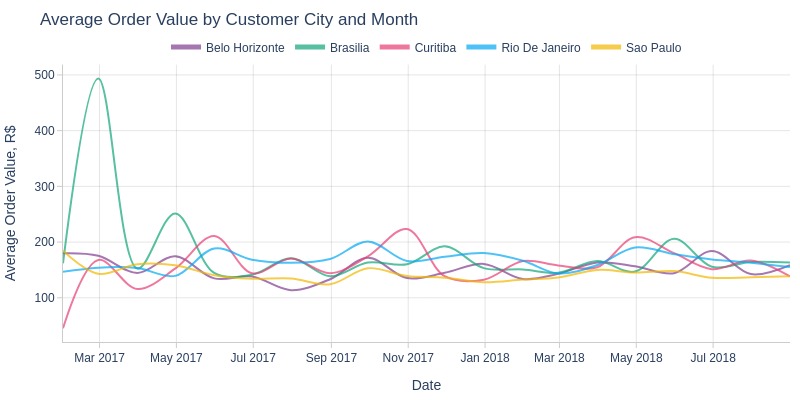
Key Observations:
February 2017 saw a major spike in Brasília’s average order value
Otherwise, top 5 cities show similar average values
Number of Purchases per Customer per Week#
tmp_df_res = (df_sales.groupby([pd.Grouper(key = 'order_purchase_dt', freq='ME'), 'customer_unique_id'])['order_id']
.nunique()
.reset_index(name='order_cnt')
)
tmp_df_res['weeks_in_month_cnt'] = tmp_df_res.order_purchase_dt.dt.days_in_month / 7
tmp_df_res['avg_orders_per_week'] = tmp_df_res['order_cnt'] / tmp_df_res['weeks_in_month_cnt']
tmp_df_res.drop(['order_cnt', 'weeks_in_month_cnt'], axis=1, inplace=True)
tmp_df_res.sort_values('avg_orders_per_week', ascending=False).head(10)
| order_purchase_dt | customer_unique_id | avg_orders_per_week | |
|---|---|---|---|
| 62 | 2017-01-31 | 12f5d6e1cbf93dafd9dcc19095df0b3d | 1.35 |
| 1722 | 2017-02-28 | a239b8e2fbce33780f1f1912e2ee5275 | 1.00 |
| 51293 | 2018-02-28 | 3e43e6105506432c953e165fb2acf44c | 1.00 |
| 54267 | 2018-02-28 | b4e4f24de1e8725b74e4a1f4975116ed | 1.00 |
| 24422 | 2017-09-30 | b08fab27d47a1eb6deda07bfd965ad43 | 0.93 |
| 5199 | 2017-04-30 | 25a560b9a6006157838aab1bdbd68624 | 0.93 |
| 375 | 2017-01-31 | 83e7958a94bd7f74a9414d8782f87628 | 0.90 |
| 93685 | 2018-08-31 | c8460e4251689ba205045f3ea17884a1 | 0.90 |
| 55050 | 2018-02-28 | d3882d7abd0c66064d740d7ed04dd1ef | 0.75 |
| 54211 | 2018-02-28 | b2bd387fdc3cf05931f0f897d607dc88 | 0.75 |
Key Observations:
User ‘12f5d6e1cbf93dafd9dcc19095df0b3d’ had the highest weekly purchase frequency (January 2017)
labels = pd.Series(dict(
order_purchase_dt = 'Date'
, avg_orders_per_week = 'Average number of sales per week'
))
tmp_df_res.viz.line(
x=labels.index[0]
, y=labels.index[1]
, agg_func='mean'
, freq='ME'
, labels=labels
, title='Average number of sales per week by month'
)
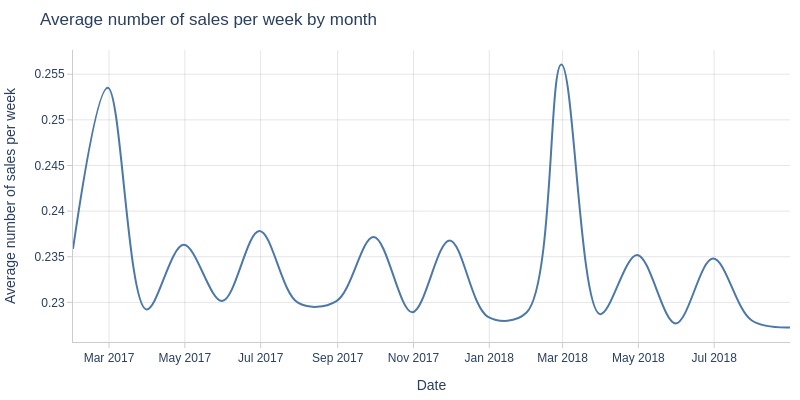
Key Observations:
Average weekly purchases per customer remains stable at 0.23-0.25
ARPPU#
pb.configure(
time_column = 'order_purchase_dt'
, time_column_label = 'Date'
, metric = 'arppu'
, metric_label = 'ARPPU, R$'
, title_base = 'ARPPU'
, freq = 'ME'
)
By Day and Month
tmp_df_res = (
df_sales.resample('D', on='order_purchase_dt')
.agg({'customer_unique_id': 'nunique', 'total_products_price': 'sum'})
.reset_index()
)
tmp_df_res['arppu'] = tmp_df_res['total_products_price'] / tmp_df_res['customer_unique_id']
fig_days = pb.line(data_frame=tmp_df_res, title='ARPPU by day')
tmp_df_res = (
df_sales.resample('ME', on='order_purchase_dt')
.agg({'customer_unique_id': 'nunique', 'total_products_price': 'sum'})
.reset_index()
)
tmp_df_res['arppu'] = tmp_df_res['total_products_price'] / tmp_df_res['customer_unique_id']
fig_days.show()
pb.line(data_frame=tmp_df_res, to_slide=True)
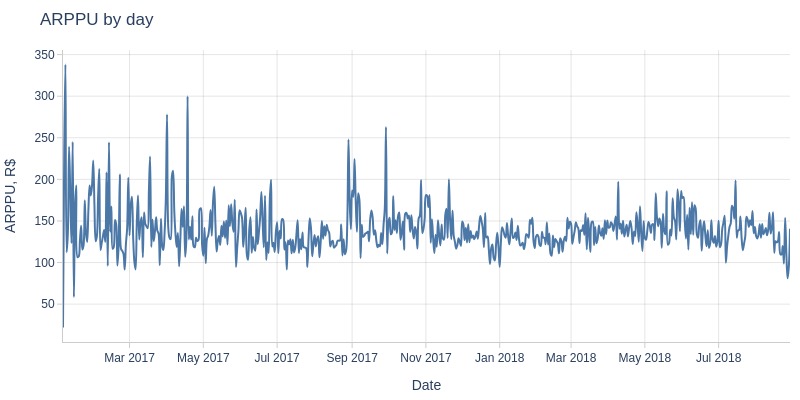
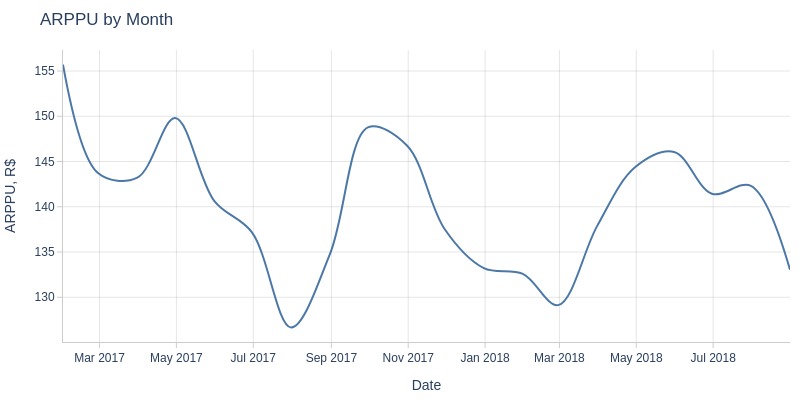
Key Observations:
ARPPU fluctuates daily between 100-250 R$
No Black Friday spike in ARPPU
Monthly ARPPU remains stable at 130-150 R$
By Time of Day
tmp_df_res = (
df_sales.groupby([pd.Grouper(key='order_purchase_dt', freq='ME'), 'purchase_time_of_day'], observed=False)
.agg({'customer_unique_id': 'nunique', 'total_products_price': 'sum'})
.reset_index()
)
tmp_df_res['arppu'] = tmp_df_res['total_products_price'] / tmp_df_res['customer_unique_id']
pb.line(data_frame=tmp_df_res, color='purchase_time_of_day')
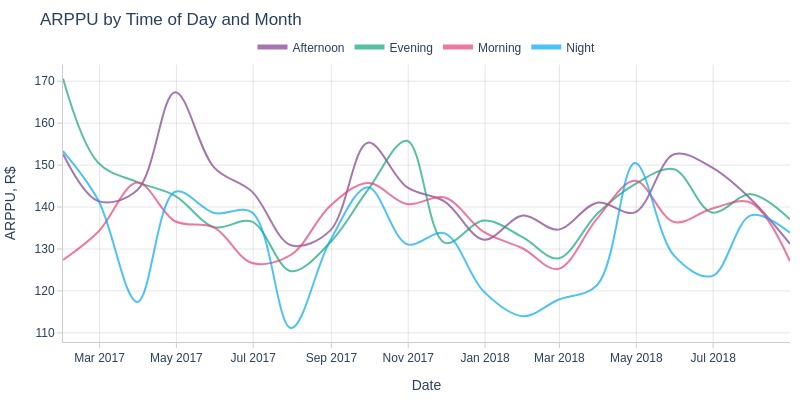
Key Observations:
No significant ARPPU differences by time of day
Nighttime ARPPU slightly lower
By Review Score
tmp_df_res = (
df_sales.groupby([pd.Grouper(key='order_purchase_dt', freq='ME'), 'order_avg_reviews_score'], observed=False)
.agg({'customer_unique_id': 'nunique', 'total_products_price': 'sum'})
.reset_index()
)
tmp_df_res['arppu'] = tmp_df_res['total_products_price'] / tmp_df_res['customer_unique_id']
Since the review score does not have a categorical type, we might lose groups with no data after grouping.
Let’s restore the dates.
tmp_df_res = tmp_df_res.preproc.restore_full_index(
date_cols='order_purchase_dt'
, group_cols='order_avg_reviews_score'
, freq='ME'
)
pb.line(data_frame=tmp_df_res, color='order_avg_reviews_score', to_slide=True)
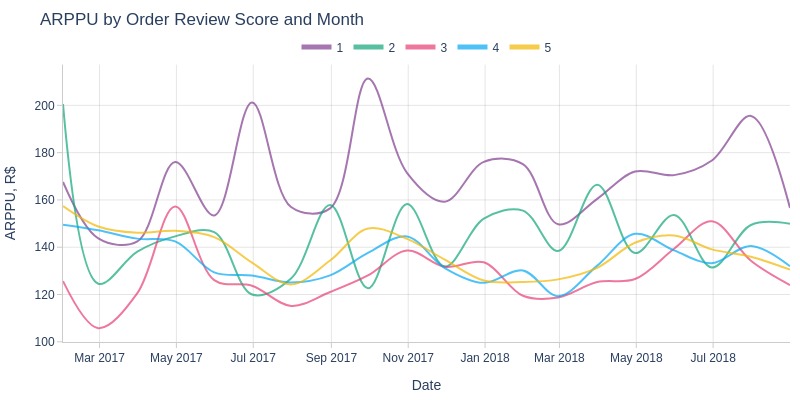
Key Observations:
1-star review orders typically had higher ARPPU
2-star orders often had higher ARPPU than 3/4/5-star orders
By Whether the Order is Delayed or Not
tmp_df_res = (
df_sales.groupby([pd.Grouper(key='order_purchase_dt', freq='ME'), 'is_delayed'], observed=False)
.agg({'customer_unique_id': 'nunique', 'total_products_price': 'sum'})
.reset_index()
)
tmp_df_res['arppu'] = tmp_df_res['total_products_price'] / tmp_df_res['customer_unique_id']
pb.line(data_frame=tmp_df_res, color='is_delayed')
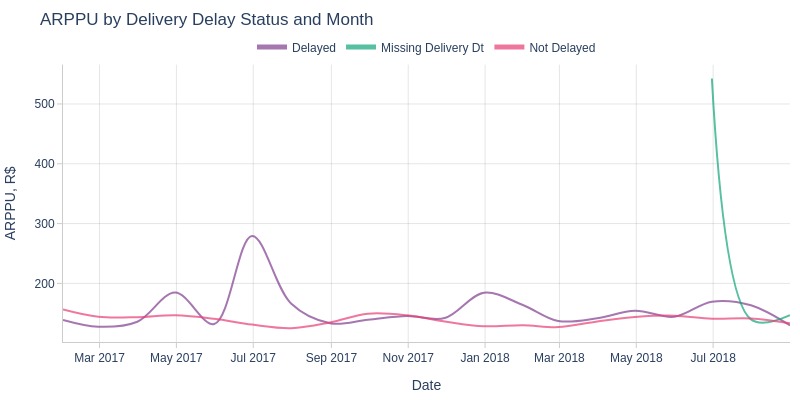
Key Observations:
June 2017 saw major ARPPU peak for delayed orders
Smaller peaks in April/December 2017 and January/June 2018
By Order Weight Category
tmp_df_res = (
df_sales.groupby([pd.Grouper(key='order_purchase_dt', freq='ME'), 'order_total_weight_cat'], observed=False)
.agg({'customer_unique_id': 'nunique', 'total_products_price': 'sum'})
.reset_index()
)
tmp_df_res['arppu'] = tmp_df_res['total_products_price'] / tmp_df_res['customer_unique_id']
pb.line(data_frame=tmp_df_res, color='order_total_weight_cat')
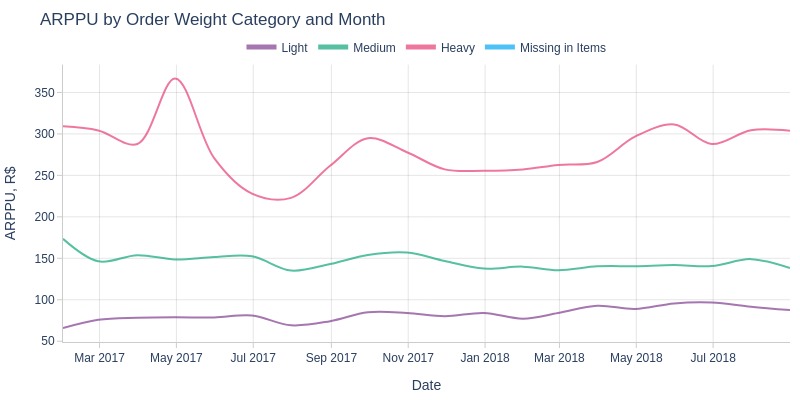
Key Observations:
Heavy orders show more ARPPU variability
Consistently: heavy > medium > light order ARPPU
April-July 2017: significant heavy order ARPPU decline, then fluctuating growth
By Delivery Time Category
tmp_df_res = (
df_sales.groupby([pd.Grouper(key='order_purchase_dt', freq='ME'), 'delivery_time_days_cat'], observed=False)
.agg({'customer_unique_id': 'nunique', 'total_products_price': 'sum'})
.reset_index()
)
tmp_df_res['arppu'] = tmp_df_res['total_products_price'] / tmp_df_res['customer_unique_id']
pb.line(data_frame=tmp_df_res, color='delivery_time_days_cat', to_slide=True)
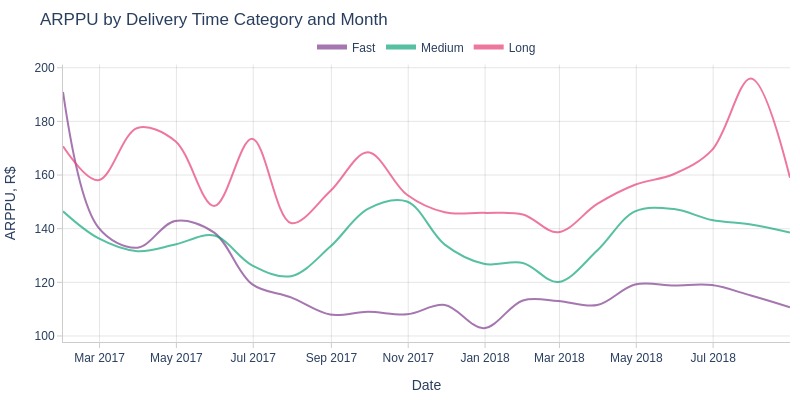
Key Observations:
Higher ARPPU typically correlates with longer delivery times
By Presence of Installment Payments
tmp_df_res = (
df_sales.groupby([pd.Grouper(key='order_purchase_dt', freq='ME'), 'order_has_installment'], observed=False)
.agg({'customer_unique_id': 'nunique', 'total_products_price': 'sum'})
.reset_index()
)
tmp_df_res['arppu'] = tmp_df_res['total_products_price'] / tmp_df_res['customer_unique_id']
pb.line(data_frame=tmp_df_res, color='order_has_installment', to_slide=True)
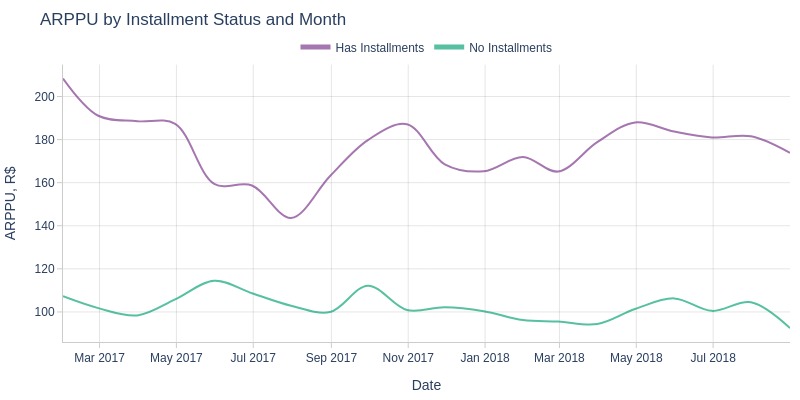
Key Observations:
Installment orders consistently show higher ARPPU
More ARPPU variability for installment orders
Pre-July 2017: steady ARPPU decline for installments
Post-July 2017: fluctuating growth
By Top Customer Cities
Since there are cities with very few sales, we will select the top 5 cities by sales volume.
top_cities = (
df_sales.groupby('customer_city', observed=False)['order_id']
.nunique()
.nlargest(5)
.index.tolist()
)
tmp_df_res = (
df_sales[lambda x: x.customer_city.isin(top_cities)]
.groupby([pd.Grouper(key='order_purchase_dt', freq='ME'), 'customer_city'], observed=False)
.agg({'customer_unique_id': 'nunique', 'total_products_price': 'sum'})
.reset_index()
)
tmp_df_res['arppu'] = tmp_df_res['total_products_price'] / tmp_df_res['customer_unique_id']
pb.line(data_frame=tmp_df_res, color='customer_city')
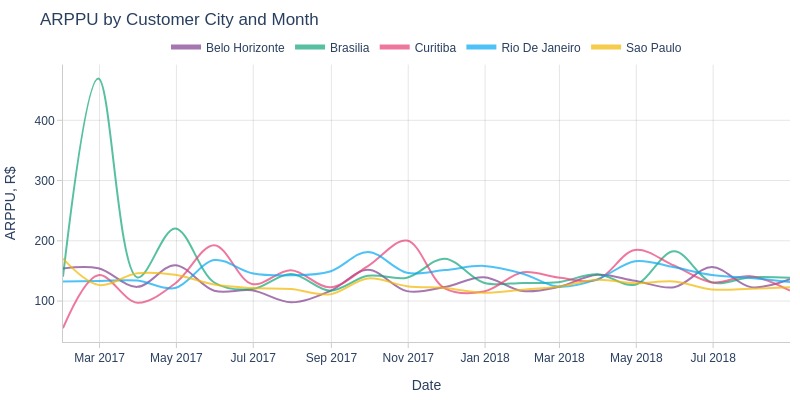
Key Observations:
February 2017: major ARPPU spike in Brasília
Otherwise minimal differences among top 5 cities
Number of Customers#
pb.configure(
df = df_sales
, time_column = 'order_purchase_dt'
, time_column_label = 'Date'
, metric = 'customer_unique_id'
, metric_label = 'Number of Customers'
, agg_func = 'nunique'
, freq='ME'
)
By Day and Month
for freq in ['D', 'ME']:
pb.line_resample(
freq=freq
, to_slide=True if freq == 'ME' else False
).show()
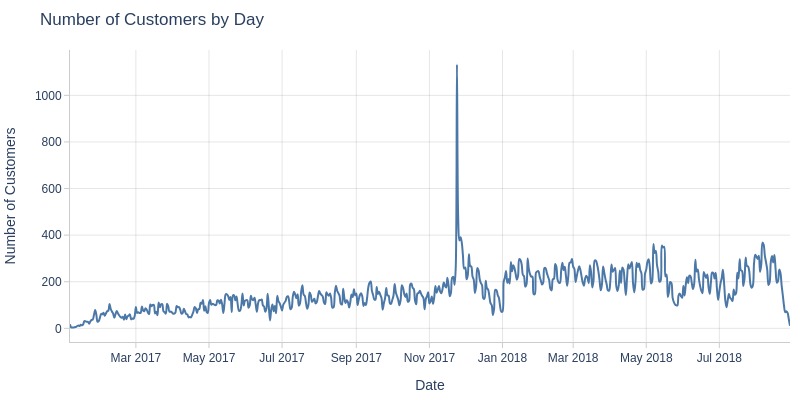
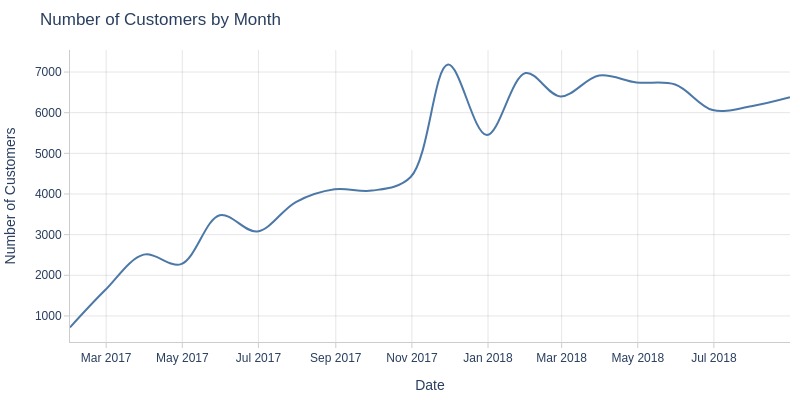
Key Observations:
Black Friday (Nov 24, 2017) saw anomalous customer count peak
Customer growth continued until 2018, then stabilized at 6-7k monthly
Monthly Growth
pb.period_change(period='mom', to_slide=True)
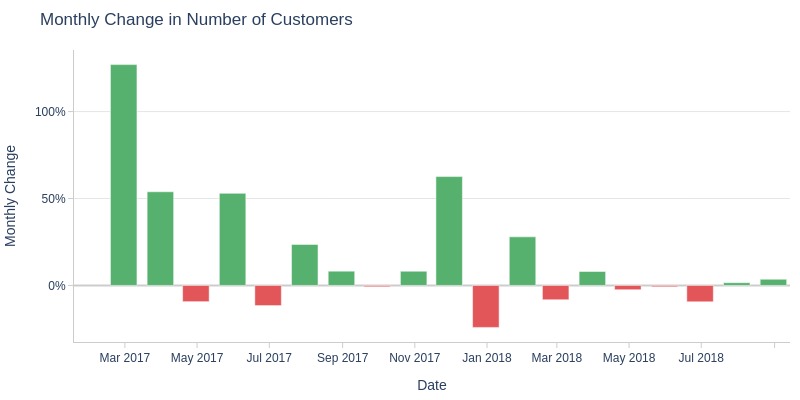
Key Observations:
Customer counts dropped >5% month-over-month in April/June/December 2017 and February/June 2018
By Time of Day
pb.line_resample(color='purchase_time_of_day', to_slide=True)
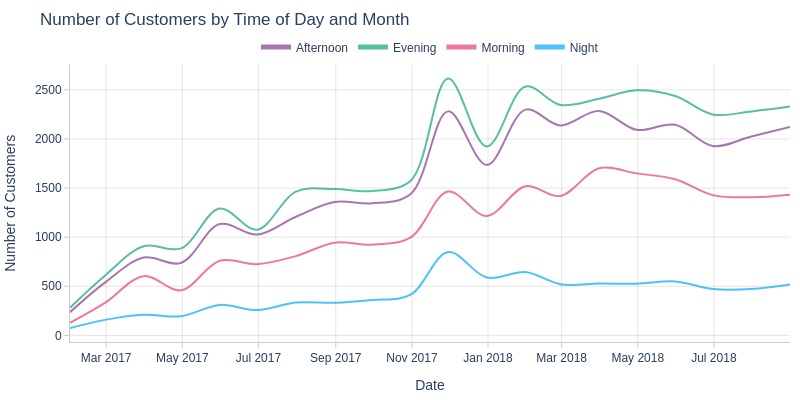
Key Observations:
Fewer customers at night
Evening sees most customer activity
By Day of Week
pb.area_resample(color='purchase_weekday', freq='W', title='Number of Sales by Day of Week and Week')
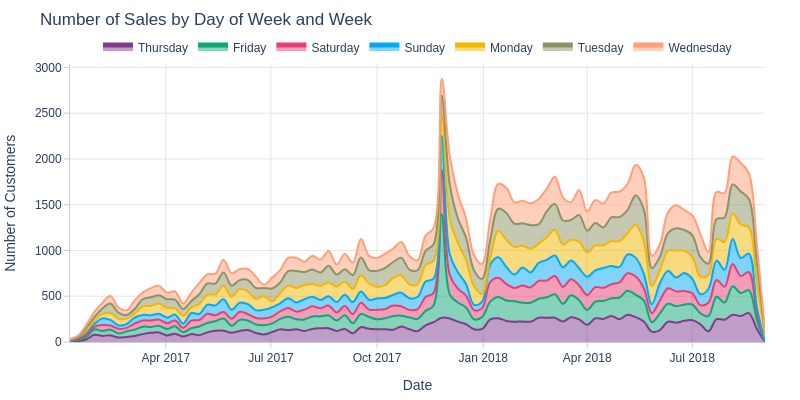
pb.heatmap(x=pd.Grouper(key=pb.time_column, freq='W')
, y='purchase_weekday'
, text_auto=False
, title='Number of Sales by Day of Week and Week'
)
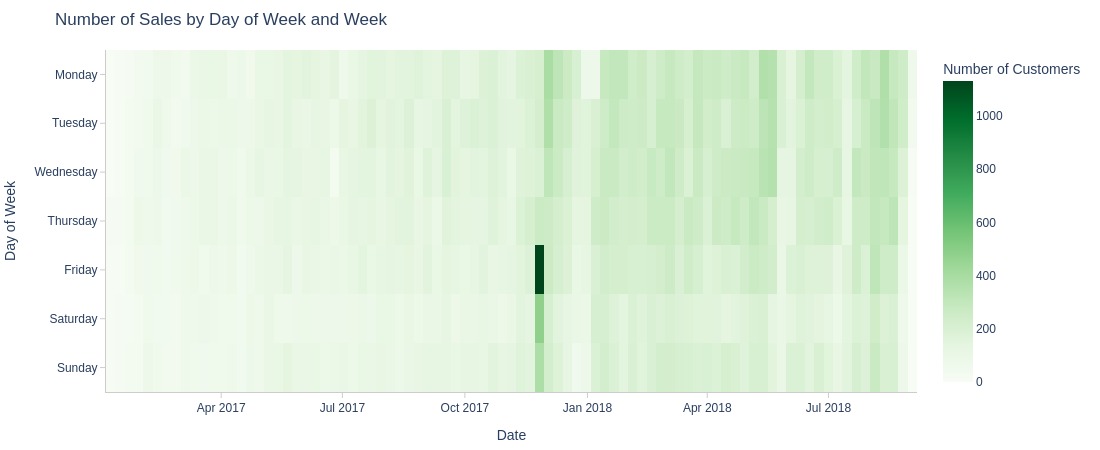
Key Observations:
Minimal weekday/weekend customer count differences
Weekends slightly lower
By Weekday vs Weekend
pb.line_resample(color='purchase_day_type')
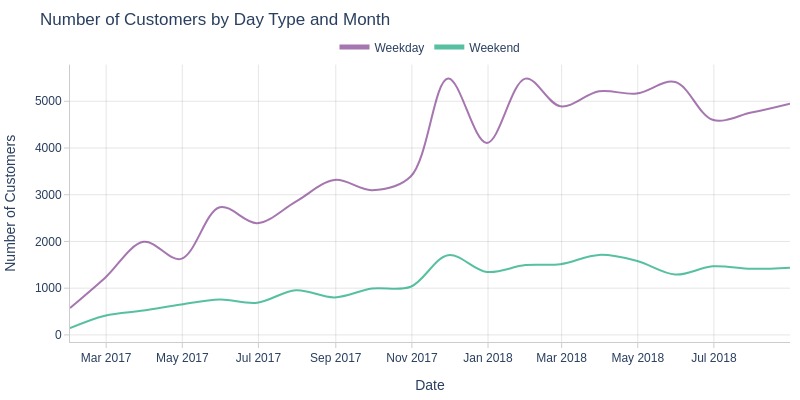
Key Observations:
Weekday customer growth outpaced weekends
By Top Customer States
pb.line_resample(color='customer_state', to_slide=True)
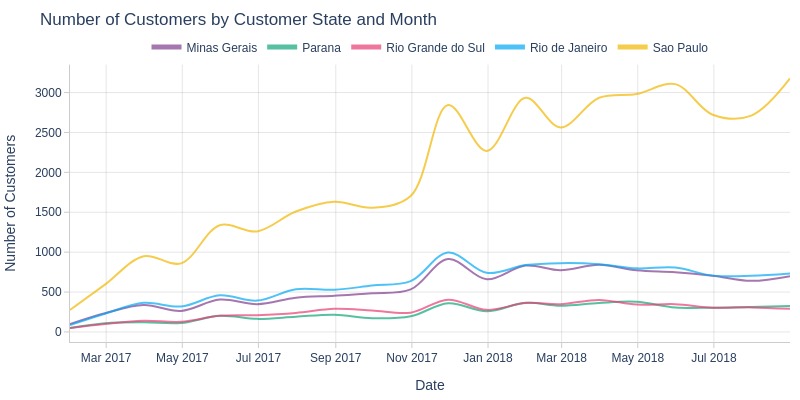
Key Observations:
São Paulo consistently led in customer counts
Unlike other states, maintained 2018 customer levels
Rio de Janeiro and Minas Gerais ranked 2nd/3rd
By Top Customer Cities
pb.line_resample(color='customer_city', to_slide=True)
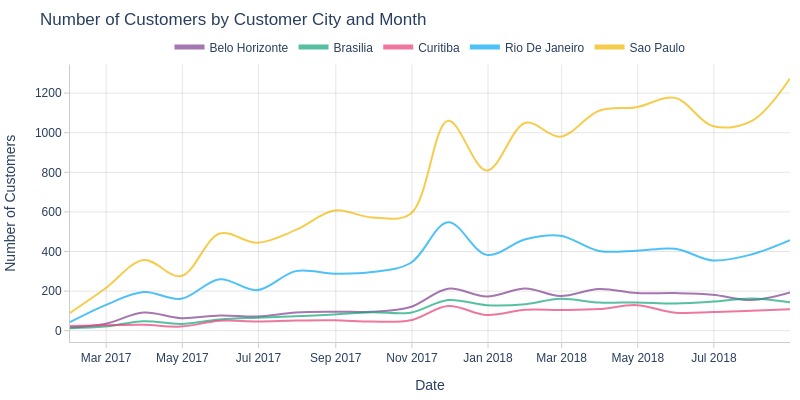
Key Observations:
São Paulo city consistently had most customers
Rio de Janeiro ranked second
Only São Paulo showed 2018 monthly growth
Share of New Customers#
pb.configure(
time_column = 'order_purchase_dt'
, time_column_label = 'Date'
, metric = 'new_customers_share'
, metric_label = 'Share of New Customers'
, freq='ME'
, update_fig={'yaxis': {'tickformat': '.1%'}}
)
By Day and Month
Since one customer could make multiple orders at the same time, we need to remove such duplicates.
tmp_df_res = (df_sales[['order_purchase_dt', 'customer_unique_id', 'sale_is_customer_first_purchase']].drop_duplicates()
.resample('D', on='order_purchase_dt')
.agg(
new_customers_cnt=('sale_is_customer_first_purchase', 'sum'),
all_customers_cnt=('customer_unique_id', 'nunique')
)
.reset_index()
)
tmp_df_res['new_customers_share'] = tmp_df_res['new_customers_cnt'] / tmp_df_res['all_customers_cnt']
fig_days = pb.line(data_frame=tmp_df_res, title='Share of New Customers by Day')
tmp_df_res = (df_sales[['order_purchase_dt', 'customer_unique_id', 'sale_is_customer_first_purchase']].drop_duplicates()
.resample('ME', on='order_purchase_dt')
.agg(
new_customers_cnt=('sale_is_customer_first_purchase', 'sum'),
all_customers_cnt=('customer_unique_id', 'nunique')
)
.reset_index()
)
tmp_df_res['new_customers_share'] = tmp_df_res['new_customers_cnt'] / tmp_df_res['all_customers_cnt']
fig_days.show()
pb.line(data_frame=tmp_df_res, to_slide=True)
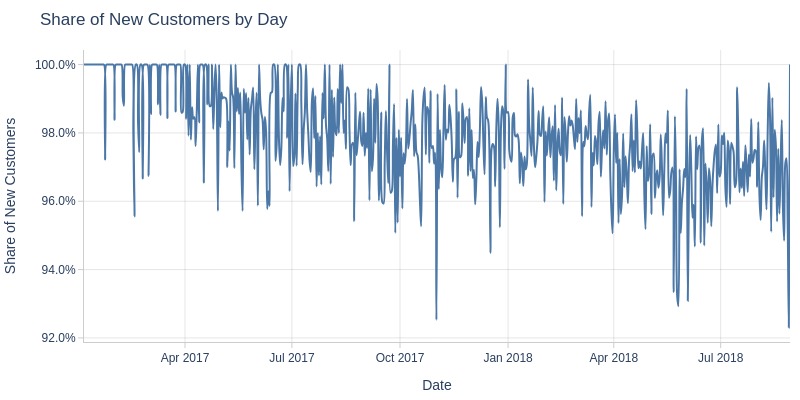
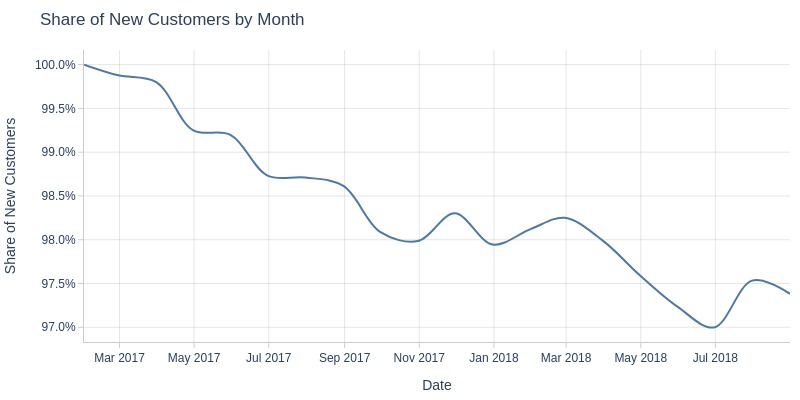
Key Observations:
Daily new customer share never fell below 92%
Monthly new customer share gradually declined (still >97%)
Nearly all active customers are new
By Weekday vs Weekend
tmp_df_res = (df_sales[['order_purchase_dt', 'customer_unique_id', 'sale_is_customer_first_purchase', 'purchase_day_type']].drop_duplicates()
.groupby([pd.Grouper(key='order_purchase_dt', freq='ME'), 'purchase_day_type'], observed=True)
.agg(
new_customers_cnt=('sale_is_customer_first_purchase', 'sum'),
all_customers_cnt=('customer_unique_id', 'nunique')
)
.reset_index()
)
tmp_df_res['new_customers_share'] = tmp_df_res['new_customers_cnt'] / tmp_df_res['all_customers_cnt']
pb.line(data_frame=tmp_df_res, color='purchase_day_type')
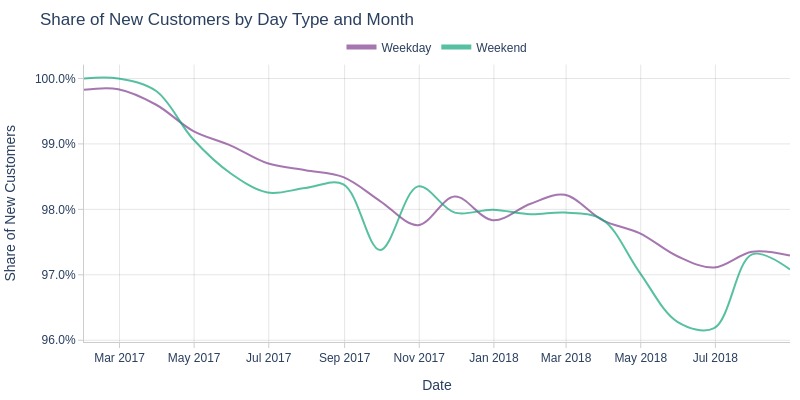
Key Observations:
Weekend new customer share fluctuates more than weekdays
Weekends typically have lower new customer share
By Top Customer States
top_states = (df_sales
.groupby('customer_state', observed=False)['order_id']
.nunique()
.nlargest(5)
.index.tolist()
)
tmp_df_res = (df_sales[lambda x: x.customer_state.isin(top_states)]
[['order_purchase_dt', 'customer_unique_id', 'sale_is_customer_first_purchase', 'customer_state']].drop_duplicates()
.groupby([pd.Grouper(key='order_purchase_dt', freq='ME'), 'customer_state'], observed=False)
.agg(
new_customers_cnt=('sale_is_customer_first_purchase', 'sum'),
all_customers_cnt=('customer_unique_id', 'nunique')
)
.reset_index()
)
tmp_df_res['new_customers_share'] = tmp_df_res['new_customers_cnt'] / tmp_df_res['all_customers_cnt']
pb.line(data_frame=tmp_df_res, color='customer_state')
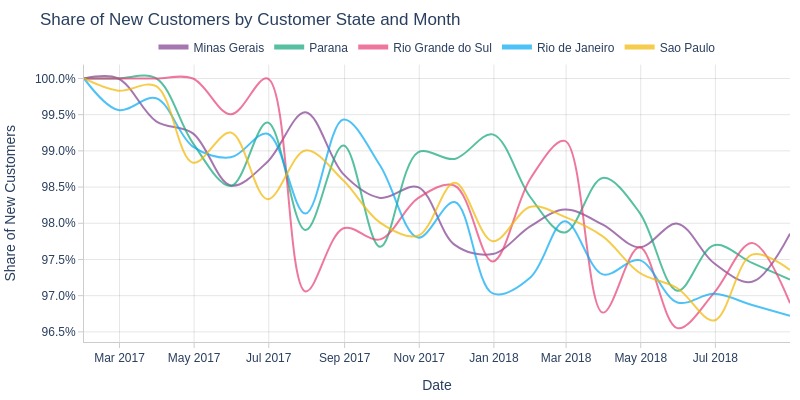
Key Observations:
Minimal state-level differences in new customer share
Rio Grande do Sul showed more variability
By Top Customer Cities
top_cities = (df_sales
.groupby('customer_city', observed=False)['order_id']
.nunique()
.nlargest(5)
.index.tolist()
)
tmp_df_res = (df_sales[lambda x: x.customer_city.isin(top_cities)]
[['order_purchase_dt', 'customer_unique_id', 'sale_is_customer_first_purchase', 'customer_city']].drop_duplicates()
.groupby([pd.Grouper(key='order_purchase_dt', freq='ME'), 'customer_city'], observed=False)
.agg(
new_customers_cnt=('sale_is_customer_first_purchase', 'sum'),
all_customers_cnt=('customer_unique_id', 'nunique')
)
.reset_index()
)
tmp_df_res['new_customers_share'] = tmp_df_res['new_customers_cnt'] / tmp_df_res['all_customers_cnt']
pb.line(data_frame=tmp_df_res, color='customer_city')
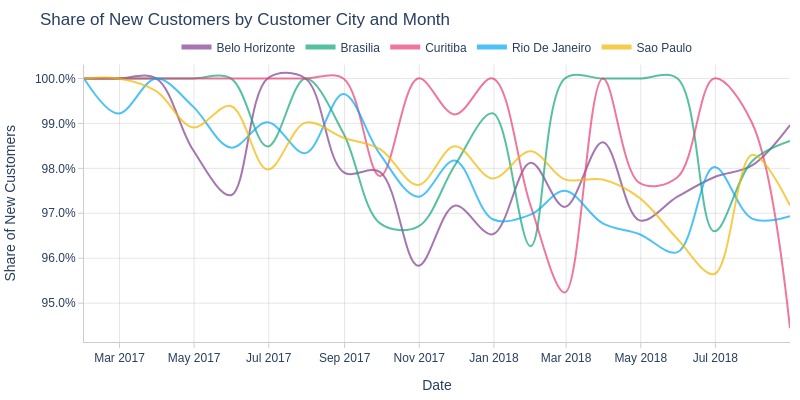
Key Observations:
São Paulo and Rio de Janeiro show less monthly fluctuation in new customer share
Number of Sellers#
tmp_df_sales_sellers = (
df_sales.merge(df_items[['order_id', 'seller_id']], on='order_id', how='left')
.merge(df_sellers[['seller_id', 'seller_state', 'seller_city']], on='seller_id', how='left')
)
pb.configure(
df = tmp_df_sales_sellers
, time_column = 'order_purchase_dt'
, time_column_label = 'Date'
, metric = 'seller_id'
, metric_label = 'Number of Sellers'
, agg_func = 'nunique'
, freq = 'ME'
)
By Day and Month
for freq in ['D', 'ME']:
pb.line_resample(
freq=freq
, to_slide=True if freq == 'ME' else False
).show()
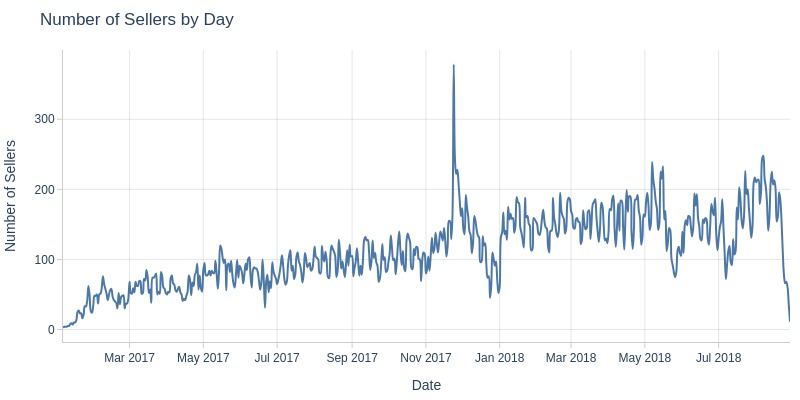
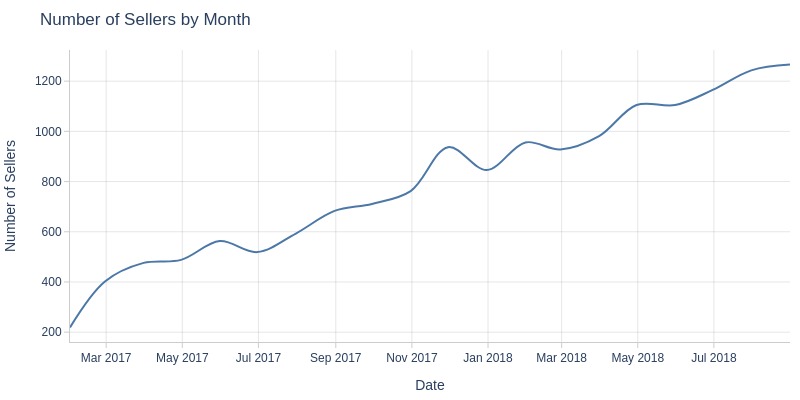
Key Observations:
Black Friday (Nov 24, 2017) saw anomalous seller count peak
Monthly seller counts show steady growth
By Time of Day
pb.line_resample(color='purchase_time_of_day', to_slide=True)
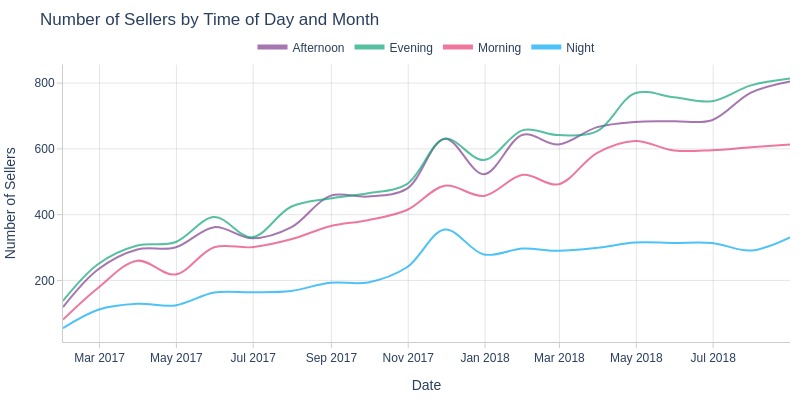
Key Observations:
Fewer active sellers at night
Evening/afternoon see most seller activity
By Weekday vs Weekend
pb.line_resample(color='purchase_day_type')
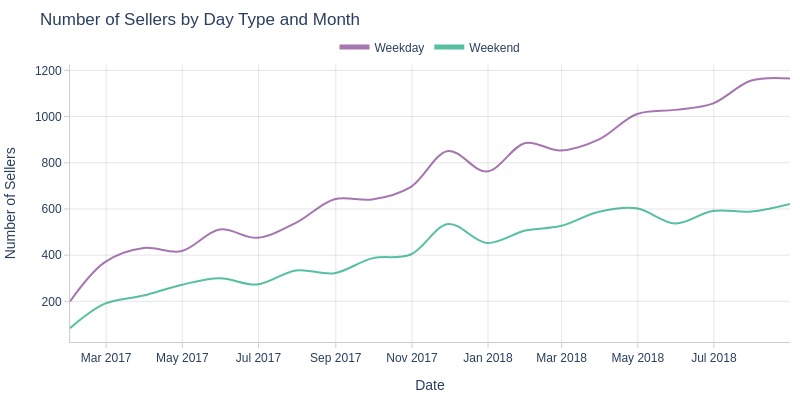
Key Observations:
Weekday seller growth outpaced weekends
By Top Seller States
pb.line_resample(color='seller_state', to_slide=True)
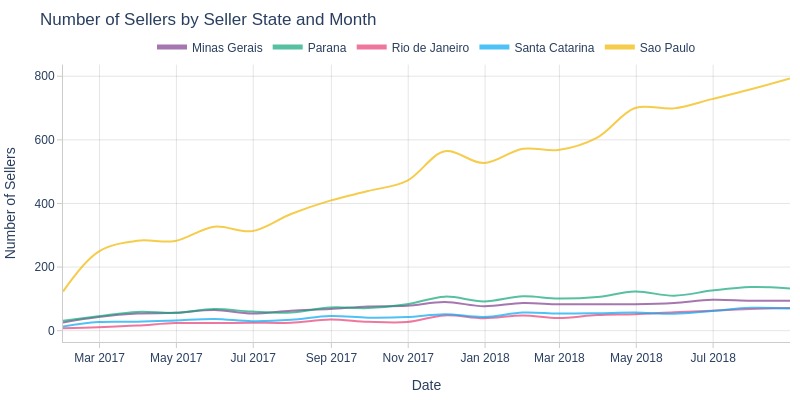
Key Observations:
São Paulo consistently led in seller counts with strongest growth
Paraná and Minas Gerais ranked 2nd/3rd
All top 5 states showed steady seller growth
By Top Seller Cities
pb.line_resample(color='seller_city', to_slide=True)
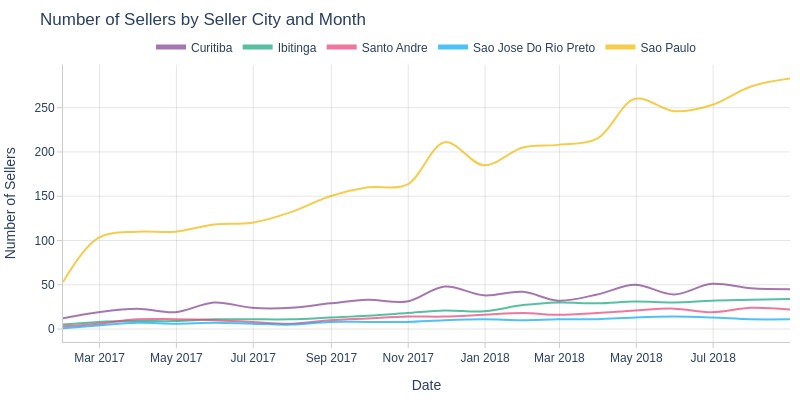
Key Observations:
São Paulo city consistently had most sellers with strongest growth
Curitiba ranked second
Share of New Sellers#
pb.configure(
time_column = 'order_purchase_dt'
, time_column_label = 'Date'
, metric = 'new_sellers_share'
, metric_label = 'Share of New Sellers'
, freq='ME'
, update_fig={'yaxis': {'tickformat': '.1%'}}
)
tmp_df_sales_sellers['seller_first_order_dt'] = tmp_df_sales_sellers.groupby('seller_id')['order_purchase_dt'].transform('min')
tmp_df_sales_sellers['is_seller_first_order'] = tmp_df_sales_sellers['order_purchase_dt'] == tmp_df_sales_sellers['seller_first_order_dt']
By Day and Month
Since one seller could appear in multiple orders at the same time in the first order, we need to remove such duplicates.
tmp_df_res = (tmp_df_sales_sellers[['order_purchase_dt', 'seller_id', 'is_seller_first_order']].drop_duplicates()
.resample('D', on='order_purchase_dt')
.agg(
new_sellers_cnt=('is_seller_first_order', 'sum'),
all_sellers_cnt=('seller_id', 'nunique')
)
.reset_index()
)
tmp_df_res['new_sellers_share'] = tmp_df_res['new_sellers_cnt'] / tmp_df_res['all_sellers_cnt']
fig_days = pb.line(data_frame=tmp_df_res
, title='Share of New Sellers by Day'
)
tmp_df_res = (tmp_df_sales_sellers[['order_purchase_dt', 'seller_id', 'is_seller_first_order']].drop_duplicates()
.resample('ME', on='order_purchase_dt')
.agg(
new_sellers_cnt=('is_seller_first_order', 'sum'),
all_sellers_cnt=('seller_id', 'nunique')
)
.reset_index()
)
tmp_df_res['new_sellers_share'] = tmp_df_res['new_sellers_cnt'] / tmp_df_res['all_sellers_cnt']
fig_days.show()
pb.line(data_frame=tmp_df_res, to_slide=True)
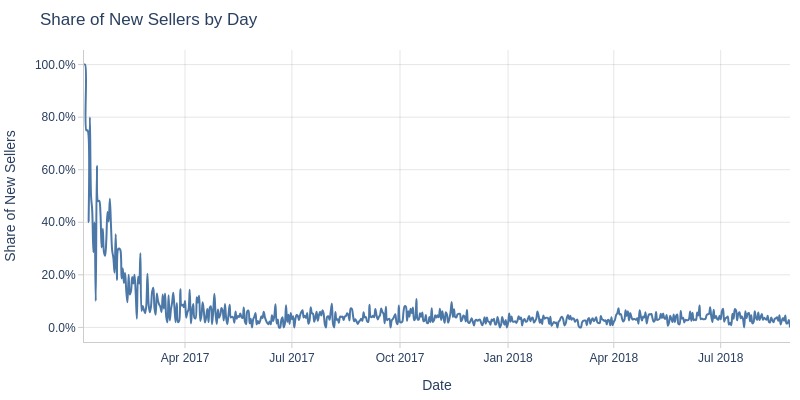
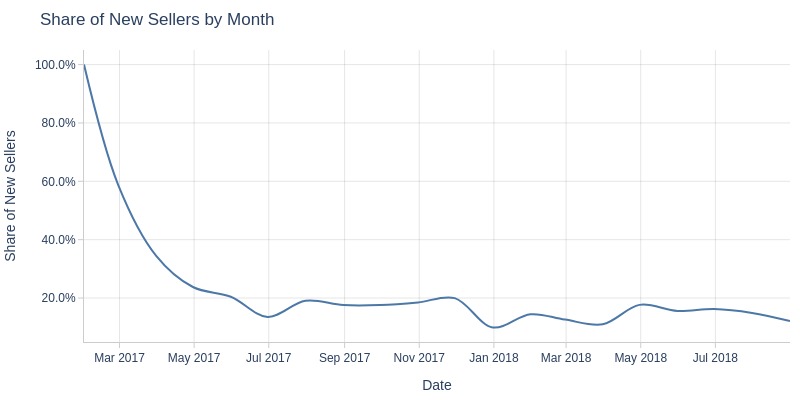
Key Observations:
New seller share declined until June 2017
Stabilized at 10-20% thereafter
By Weekday vs Weekend
tmp_df_res = (tmp_df_sales_sellers[['order_purchase_dt', 'seller_id', 'is_seller_first_order', 'purchase_day_type']].drop_duplicates()
.groupby([pd.Grouper(key='order_purchase_dt', freq='ME'), 'purchase_day_type'], observed=True)
.agg(
new_sellers_cnt=('is_seller_first_order', 'sum'),
all_sellers_cnt=('seller_id', 'nunique')
)
.reset_index()
)
tmp_df_res['new_sellers_share'] = tmp_df_res['new_sellers_cnt'] / tmp_df_res['all_sellers_cnt']
pb.line(data_frame=tmp_df_res, color='purchase_day_type')
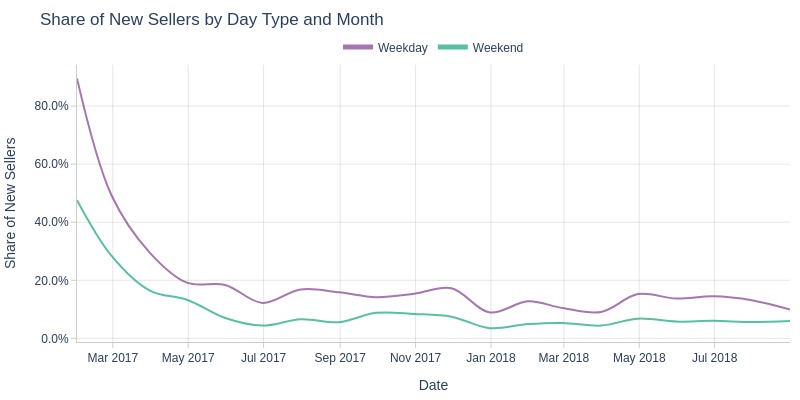
Key Observations:
Weekends consistently had lower new seller share than weekdays
By Top Seller States
top_states = (tmp_df_sales_sellers
.groupby('seller_state', observed=False)['order_id']
.nunique()
.nlargest(5)
.index.tolist()
)
tmp_df_res = (tmp_df_sales_sellers[lambda x: x.seller_state.isin(top_states)]
[['order_purchase_dt', 'seller_id', 'is_seller_first_order', 'seller_state']].drop_duplicates()
.groupby([pd.Grouper(key='order_purchase_dt', freq='ME'), 'seller_state'], observed=False)
.agg(
new_sellers_cnt=('is_seller_first_order', 'sum'),
all_sellers_cnt=('seller_id', 'nunique')
)
.reset_index()
)
tmp_df_res['new_sellers_share'] = tmp_df_res['new_sellers_cnt'] / tmp_df_res['all_sellers_cnt']
pb.line(data_frame=tmp_df_res, color='seller_state')
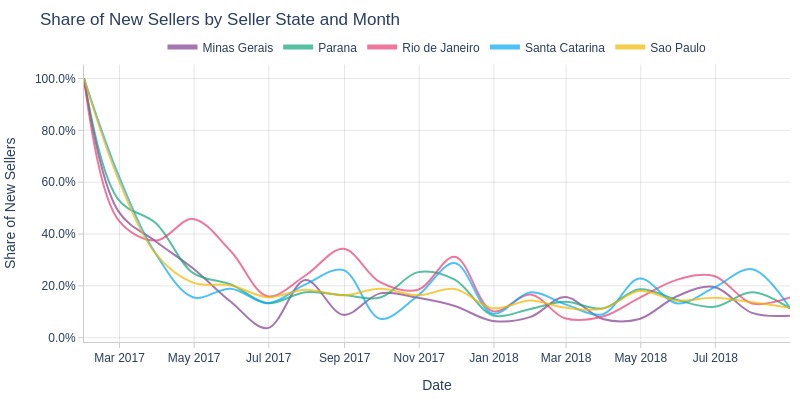
Key Observations:
Minimal state-level differences in new seller share
Minas Gerais often slightly lower
del tmp_df_res
Ratio of Number of Sellers and Customers#
Active Sellers and Customers
customers_cnt_all = (tmp_df_sales_sellers.resample('ME', on='order_purchase_dt')['customer_unique_id']
.nunique()
.to_frame()
)
sellers_cnt_all = (tmp_df_sales_sellers.resample('ME', on='order_purchase_dt')['seller_id']
.nunique()
.to_frame()
)
tmp_df_res = customers_cnt_all.merge(sellers_cnt_all, left_index=True, right_index=True).reset_index()
tmp_df_res['seller_customer_ratio'] = (tmp_df_res['seller_id'] / tmp_df_res['customer_unique_id']).round(2)
labels = pd.Series(dict(
order_purchase_dt = 'Date'
, seller_customer_ratio = 'Ratio of Number of Sellers and Customers'
))
fig = tmp_df_res.viz.line(
x=labels.index[0]
, y=labels.index[1]
, labels=labels
, title='Ratio of Number of Sellers and Customers by Month'
)
pb.to_slide(fig)
fig.show()
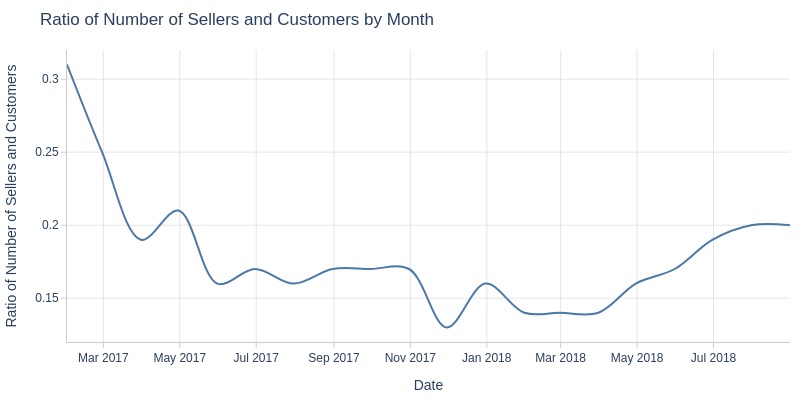
Key Observations:
Pre-November 2017: customer growth outpaced sellers
Post-November 2017: reversed trend
New Sellers and Customers
tmp_df_sales_sellers['first_order_customer_dt'] = tmp_df_sales_sellers.groupby('customer_unique_id')['order_purchase_dt'].transform('min')
tmp_df_sales_sellers['is_first_month_for_customer'] = (
(tmp_df_sales_sellers['order_purchase_dt'].dt.month == tmp_df_sales_sellers['first_order_customer_dt'].dt.month) &
(tmp_df_sales_sellers['order_purchase_dt'].dt.year == tmp_df_sales_sellers['first_order_customer_dt'].dt.year)
)
tmp_df_sales_sellers['first_order_seller_dt'] = tmp_df_sales_sellers.groupby('seller_id')['order_purchase_dt'].transform('min')
tmp_df_sales_sellers['is_first_month_for_seller'] = (
(tmp_df_sales_sellers['order_purchase_dt'].dt.month == tmp_df_sales_sellers['first_order_seller_dt'].dt.month) &
(tmp_df_sales_sellers['order_purchase_dt'].dt.year == tmp_df_sales_sellers['first_order_seller_dt'].dt.year)
)
customers_cnt_new = (tmp_df_sales_sellers[tmp_df_sales_sellers.is_first_month_for_customer].resample('ME', on='order_purchase_dt')['customer_unique_id']
.nunique()
.to_frame()
)
sellers_cnt_new = (tmp_df_sales_sellers[tmp_df_sales_sellers.is_first_month_for_seller].resample('ME', on='order_purchase_dt')['seller_id']
.nunique()
.to_frame()
)
tmp_df_res = customers_cnt_new.merge(sellers_cnt_new, left_index=True, right_index=True).reset_index()
tmp_df_res['seller_customer_ratio'] = (tmp_df_res['seller_id'] / tmp_df_res['customer_unique_id']).round(2)
labels = pd.Series(dict(
order_purchase_dt = 'Date'
, seller_customer_ratio = 'Ratio of New Sellers and New Customers'
))
fig = tmp_df_res.viz.line(
x=labels.index[0]
, y=labels.index[1]
, labels=labels
, title='Ratio of Number of New Sellers and Number of New Customers by Month'
)
pb.to_slide(fig)
fig.show()
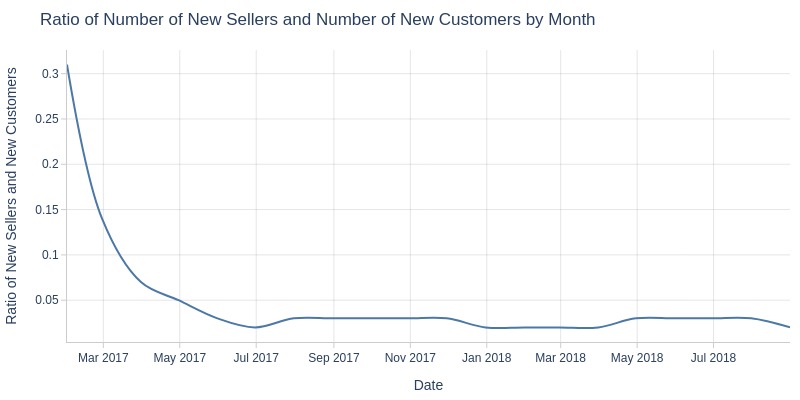
Key Observations:
Pre-July 2017: stronger new customer growth
Post-July 2017: similar growth rates for new customers/sellers
Number of Orders per Customer#
By month
tmp_df_res = (
df_sales.groupby([pd.Grouper(key = 'order_purchase_dt', freq='ME'), 'customer_unique_id'])['order_id']
.nunique()
.reset_index()
)
labels = pd.Series(dict(
order_purchase_dt = 'Date'
, order_id = 'Average Number of Orders per Customer'
))
fig = tmp_df_res.viz.line(
x=labels.index[0]
, y=labels.index[1]
, agg_func='mean'
, freq='ME'
, labels=labels
, title='Average Number of Orders per Customer by Month'
)
pb.to_slide(fig)
fig.show()
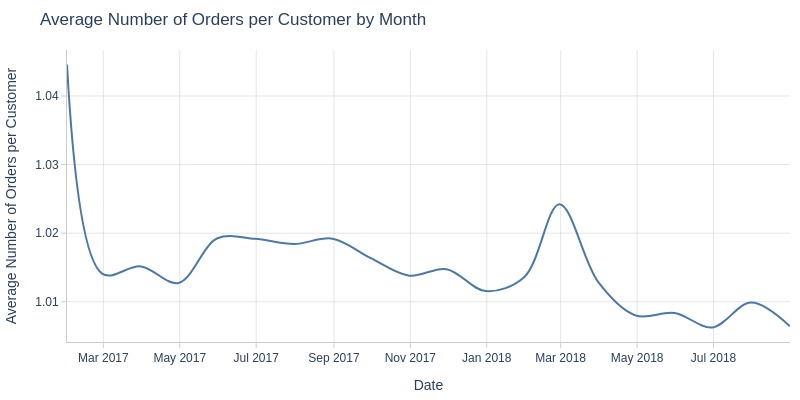
Key Observations:
The average number of orders per user fluctuates around 1 throughout the entire period.
Number of Reviews#
pb.configure(
df = df_reviews
, time_column = 'review_creation_dt'
, time_column_label = 'Date'
, metric = 'review_id'
, metric_label = 'Number of Reviews'
, agg_func = 'nunique'
, freq = 'ME'
)
By Day and Month
for freq in ['D', 'ME']:
pb.line_resample(
freq=freq
, to_slide=True if freq == 'ME' else False
).show()
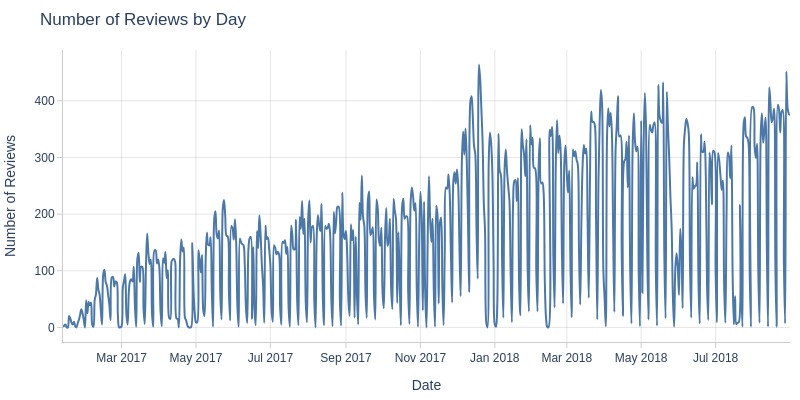
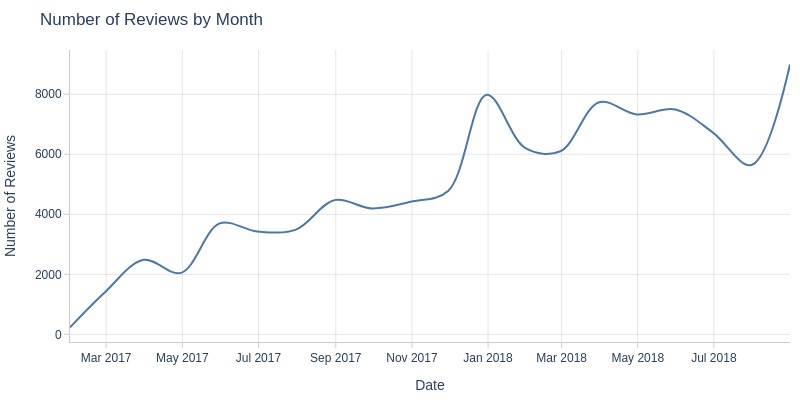
Key Observations:
Daily review counts fluctuate significantly with extreme drops
Reviews may not be recorded daily but in batches
Review counts grew steadily until 2018, then stabilized at 6-8k monthly
By Day of Week
pb.area_resample(color='review_creation_weekday', freq='W', title='Number of Reviews by Day of Week and Week')
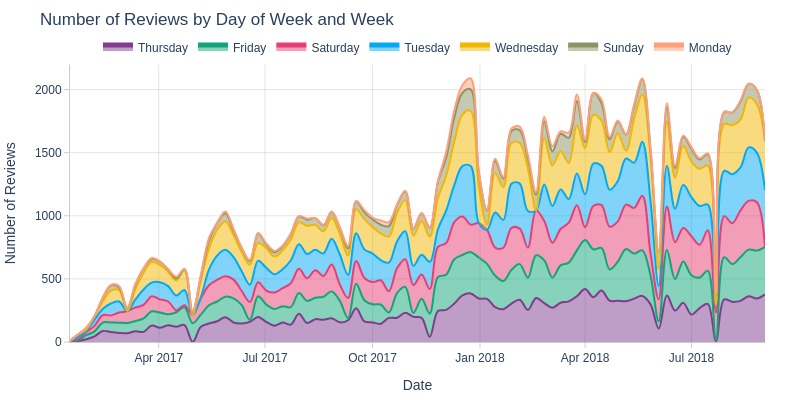
pb.heatmap(x=pd.Grouper(key=pb.time_column, freq='W')
, y='review_creation_weekday'
, text_auto=False
, title='Number of Reviews by Day of Week and Week'
, to_slide=True
)
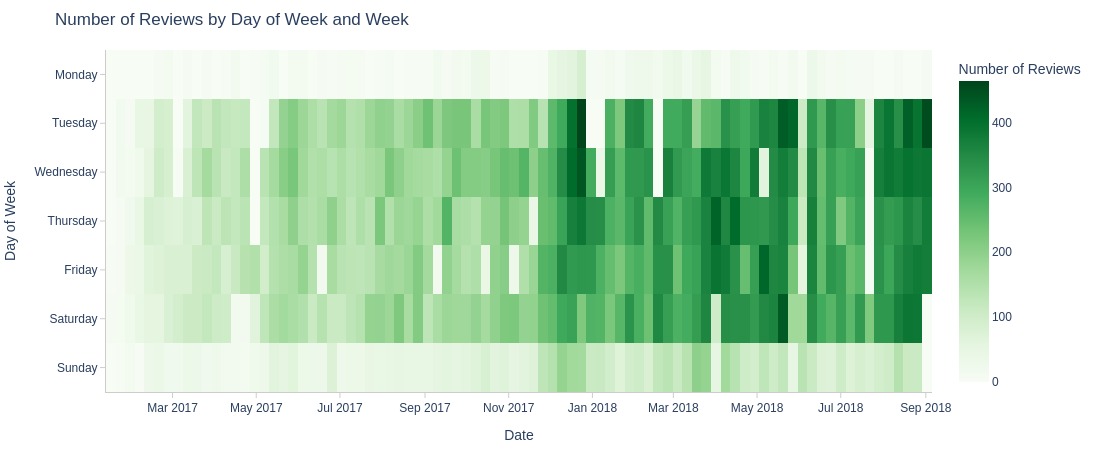
Key Observations:
Significantly fewer reviews created on Mondays/Sundays
Minimal differences between other weekdays
By Weekday vs Weekend
pb.line_resample(color='review_day_type')
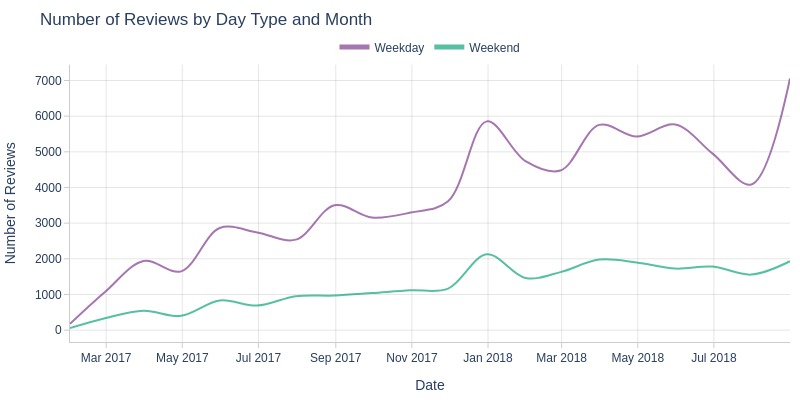
Key Observations:
Workdays consistently generate more reviews than weekends
By Review Score
pb.line_resample(color='review_score')
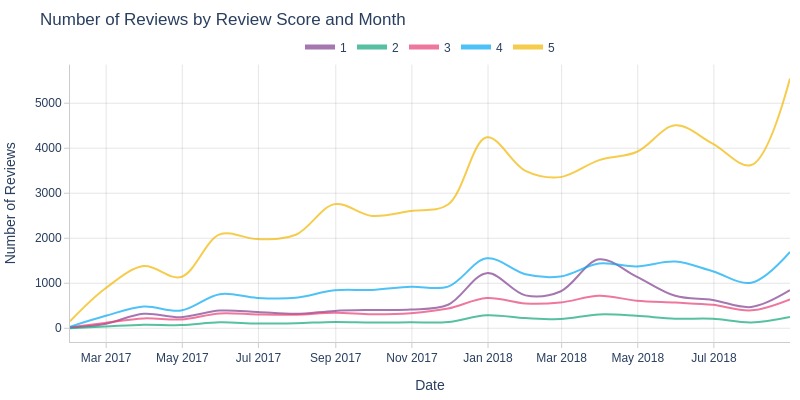
Key Observations:
5-star reviews significantly outnumber others monthly
2-star reviews are consistently the least common
More 1-star reviews than 2/3-star reviews
Review Score#
pb.configure(
df = df_reviews
, time_column = 'review_creation_dt'
, time_column_label = 'Date'
, metric = 'review_score'
, metric_label = 'Average Review Score'
, agg_func = 'mean'
, freq = 'ME'
)
By Day and Month
for freq in ['D', 'ME']:
pb.line_resample(
freq=freq
, to_slide=True if freq == 'ME' else False
).show()
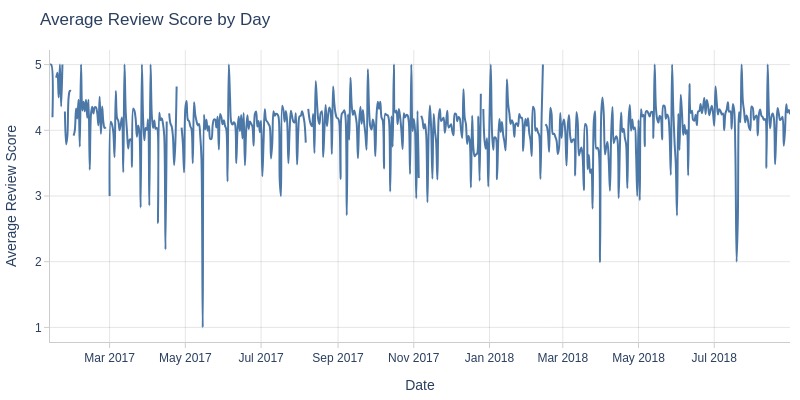
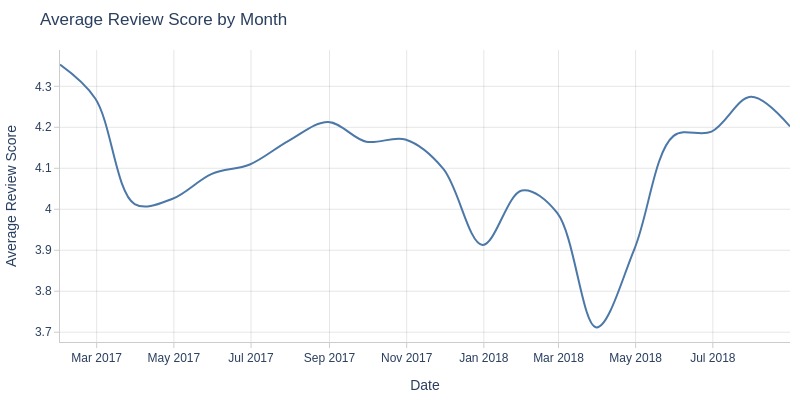
Key Observations:
Daily average review scores fluctuate wildly (3-5)
Monthly averages declined from August 2017 to March 2018, then spiked
By Weekday vs Weekend
pb.line_resample(color='review_day_type', to_slide=True)
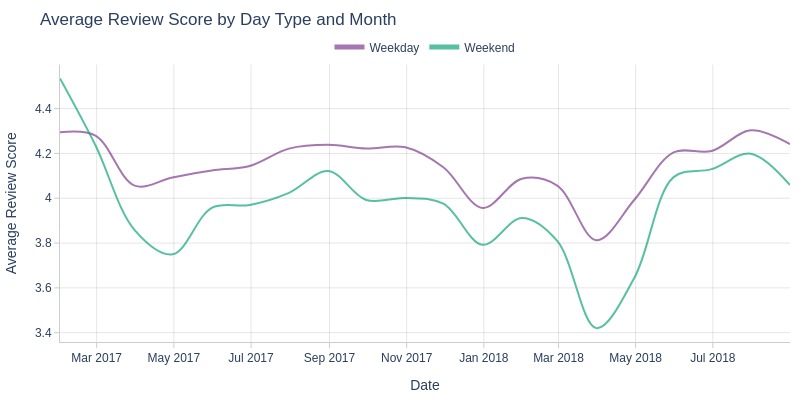
Key Observations:
Workdays consistently have higher average review scores than weekends
NPS#
For calculating NPS, we will divide customers into the following groups:
Promoters: customers who gave a rating of 5
Passive: customers who gave a rating of 4
Detractors: customers who gave a rating of 1-3
Let’s look at how NPS changed by month.
tmp_df_res = (
df_reviews.pivot_table(index=pd.Grouper(key='review_creation_dt', freq='ME'), columns='review_score', values='review_id', aggfunc='nunique')
)
tmp_df_res['total_responses'] = tmp_df_res.sum(axis=1)
tmp_df_res['promoters'] = tmp_df_res[5]
tmp_df_res['detractors'] = tmp_df_res[1] + tmp_df_res[2] + tmp_df_res[3]
tmp_df_res['nps'] = (tmp_df_res['promoters'] - tmp_df_res['detractors']) * 100 / tmp_df_res['total_responses']
tmp_df_res.reset_index(inplace=True)
labels = pd.Series(dict(
review_creation_dt = 'Date'
, nps = 'NPS'
))
fig = tmp_df_res.viz.line(
x=labels.index[0]
, y=labels.index[1]
, labels=labels
, title='NPS by month'
)
pb.to_slide(fig)
fig.show()
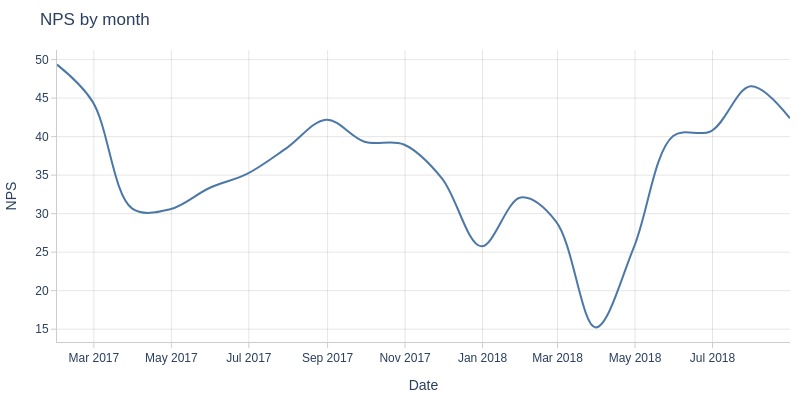
Key Observations:
NPS remains satisfactory (0-49) throughout
Many neutral customers, few critical issues
Significant NPS drop in March 2018
Freight Cost Ratio#
pb.configure(
df = df_sales
, time_column = 'order_purchase_dt'
, time_column_label = 'Date'
, metric = 'freight_ratio'
, metric_label = 'Average Freight Cost Ratio'
, agg_func = 'mean'
, freq = 'ME'
, update_fig={'yaxis': {'tickformat': '.1%'}}
)
By Day and Month
for freq in ['D', 'ME']:
pb.line_resample(
freq=freq
, to_slide=True if freq == 'ME' else False
).show()
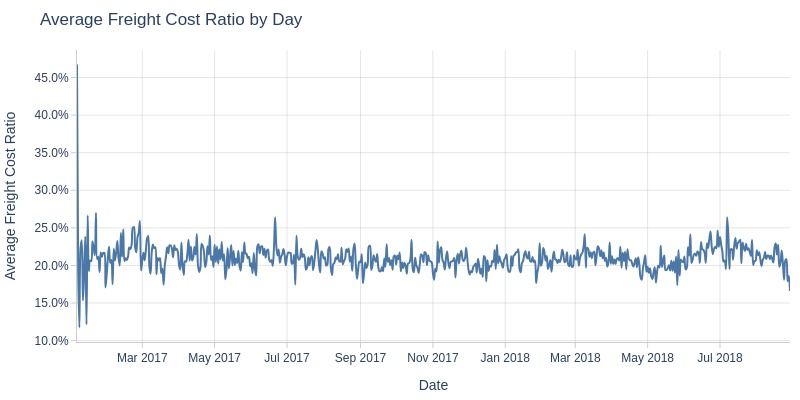
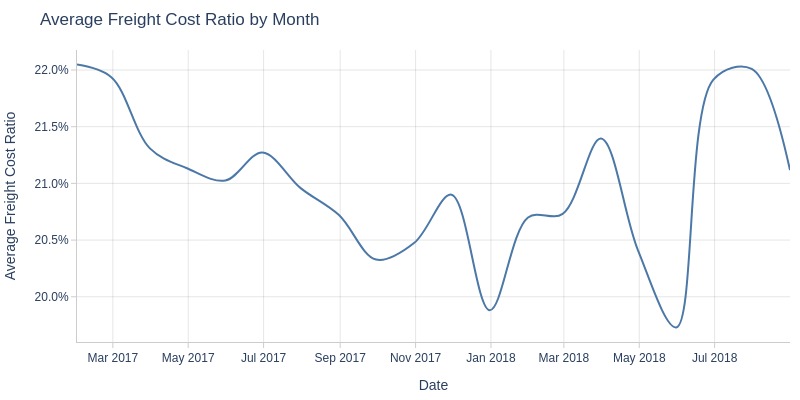
Key Observations:
Shipping cost share of order value remains stable (0.2-0.22)
By Order Weight Category
pb.line_resample(color='order_total_weight_cat')
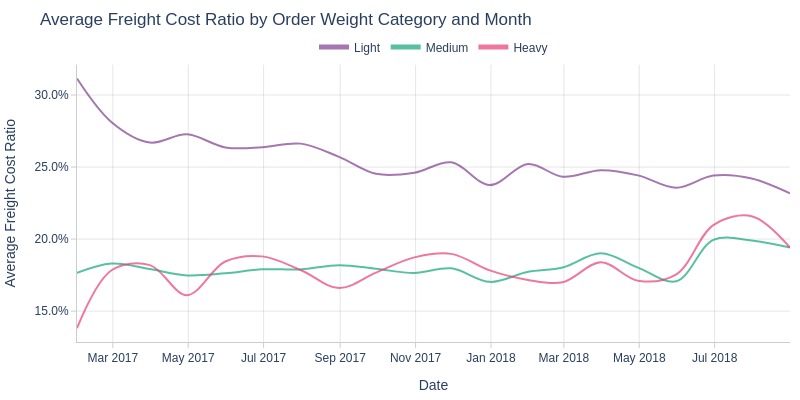
Key Observations:
Light items have higher shipping cost share than medium/heavy
Minimal difference between medium/heavy items
By Presence of Installment Payments
pb.line_resample(color='order_has_installment')
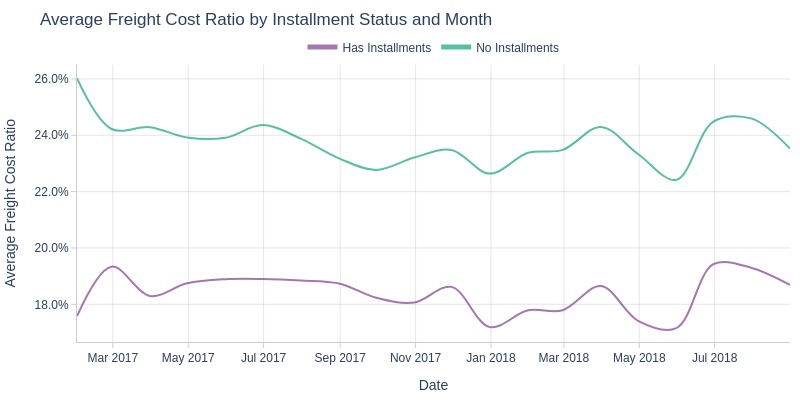
Key Observations:
Installment orders consistently have lower shipping cost share
By Top Customer States
pb.line_resample(color='customer_state')
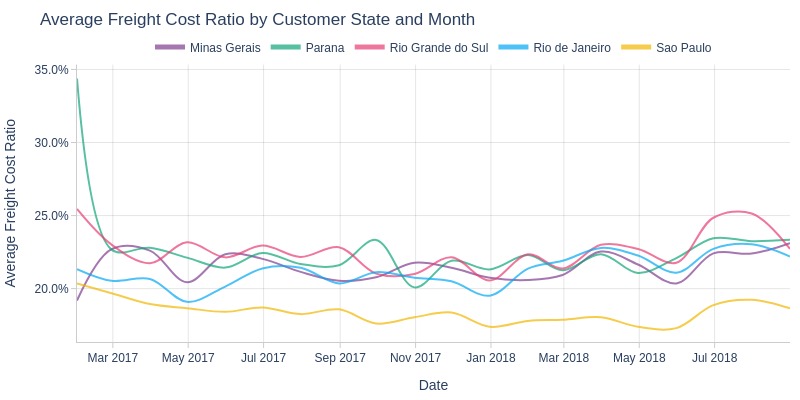
Key Observations:
São Paulo consistently has lowest shipping cost share among top states
By Top Customer Cities
pb.line_resample(color='customer_city')
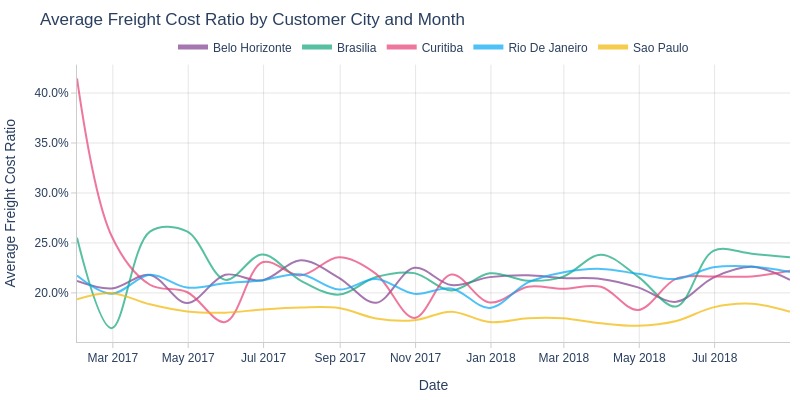
Key Observations:
São Paulo city usually has lowest shipping cost share among top cities
Delivery Time#
pb.configure(
df = df_sales.dropna(subset='delivery_time_days')
, time_column = 'order_purchase_dt'
, time_column_label = 'Date'
, metric = 'delivery_time_days'
, metric_label = 'Average Delivery Time, days'
, metric_label_for_distribution = 'Delivery Time, days'
, agg_func = 'mean'
, freq = 'ME'
)
By Day and Month
pb.box(mode='time_series', freq='M').show()
pb.box(mode='time_series', freq='M', upper_quantile=0.95).show()
for freq in ['D', 'ME']:
pb.line_resample(
freq=freq
, to_slide=True if freq == 'ME' else False
).show()
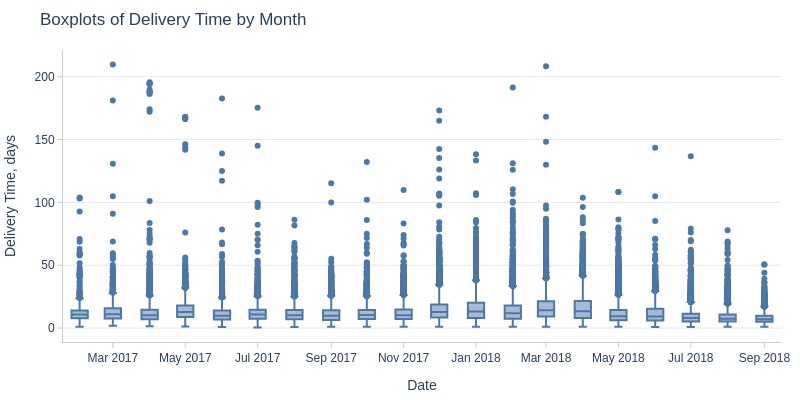
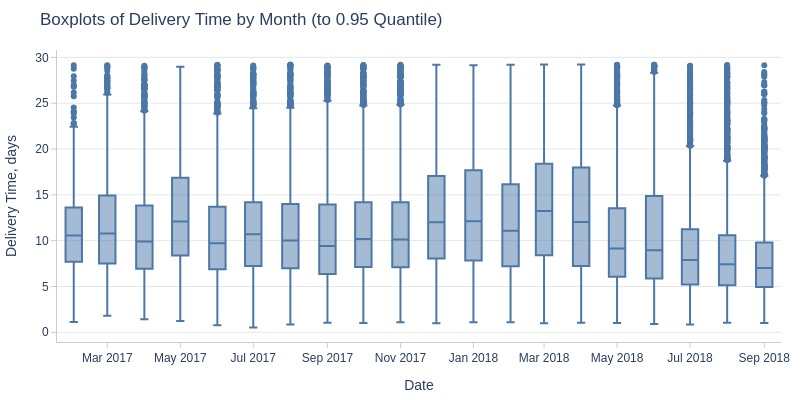
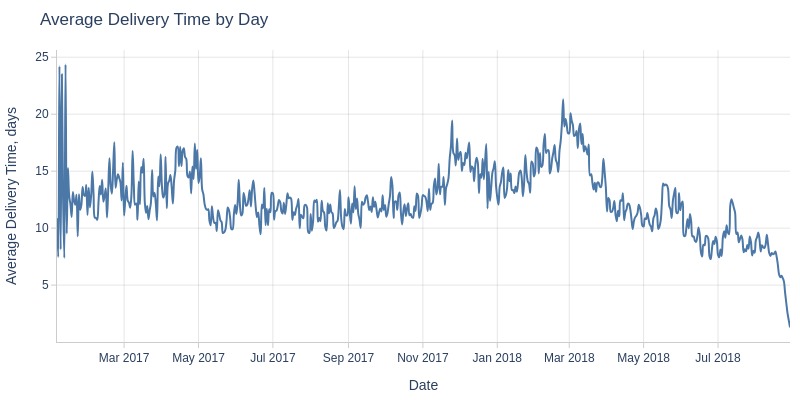
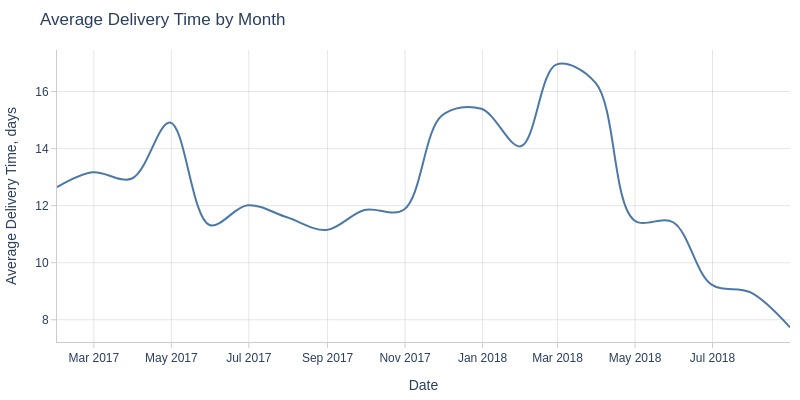
Key Observations:
Average delivery time fluctuates daily (5-20 days)
Grew from August 2017-February 2018, then dropped sharply to ~8 days
By Review Score
pb.line_resample(color='order_avg_reviews_score', to_slide=True)
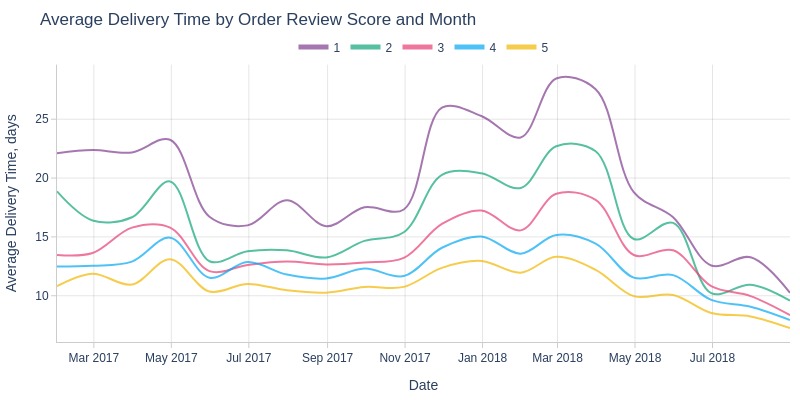
Key Observations:
Lower ratings typically correlate with longer delivery times
By Top Customer States
pb.line_resample(color='customer_state', to_slide=True)
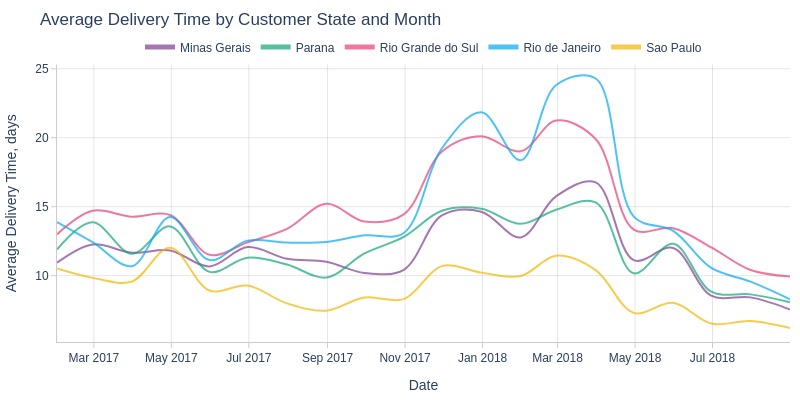
Key Observations:
São Paulo consistently has fastest delivery among top states
Rio de Janeiro and Rio Grande do Sul show slowest deliveries
By Top Customer Cities
pb.line_resample(color='customer_city', to_slide=True)
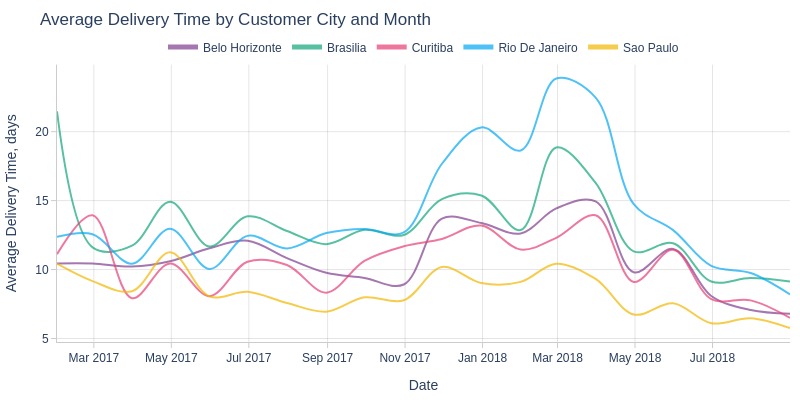
Key Observations:
Rio de Janeiro had steeper delivery time increases (Oct 2017-Feb 2018)
Delivery Delay Time#
By Day and Month
labels = pd.Series(dict(
order_purchase_dt = 'Date'
, delivery_delay_days = 'Average Delivery Delay Time, days'
))
for freq, period in [('D', 'Day'), ('ME', 'Month')]:
fig = df_sales.viz.line(
x=labels.index[0]
, y=labels.index[1]
, agg_func='mean'
, freq=freq
, labels=labels
, title=f'Average Delivery Delay Time by {period}'
)
if freq == 'ME':
pb.to_slide(fig)
fig.show()
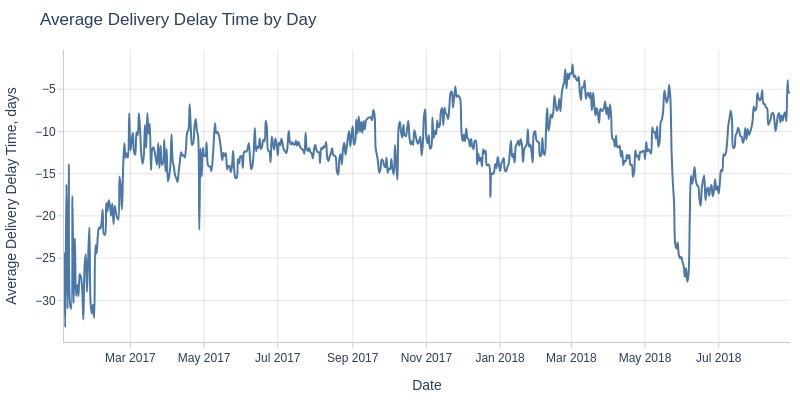
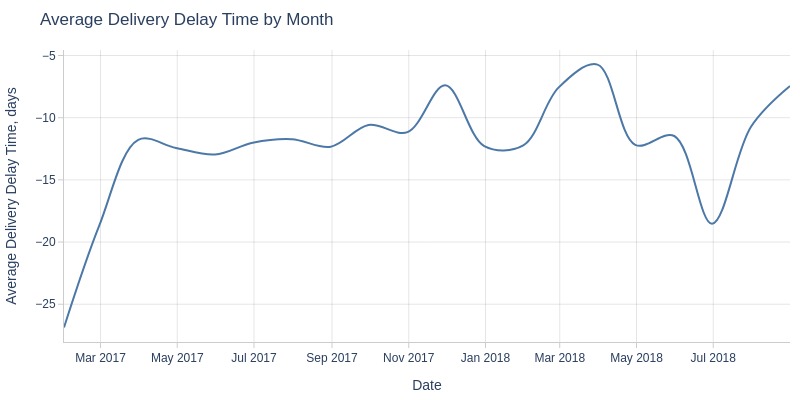
Key Observations:
All months show faster-than-expected deliveries
Early 2017 to March 2017: improving lead times (~12 days ahead)
June 2018: deliveries ~20 days ahead of estimates
Carrier Handoff Delay#
By Day and Month
labels = pd.Series(dict(
order_purchase_dt = 'Date'
, avg_carrier_delivery_delay_days = 'Average Carrier Handoff Delay, days'
))
for freq, period in [('D', 'Day'), ('ME', 'Month')]:
fig = df_sales.viz.line(
x=labels.index[0]
, y=labels.index[1]
, agg_func='mean'
, freq=freq
, labels=labels
, title=f'Average Carrier Handoff Delay by {period}'
)
if freq == 'ME':
pb.to_slide(fig)
fig.show()
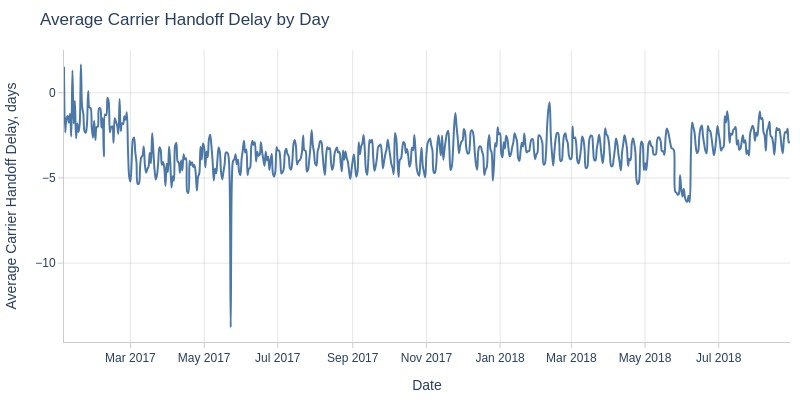
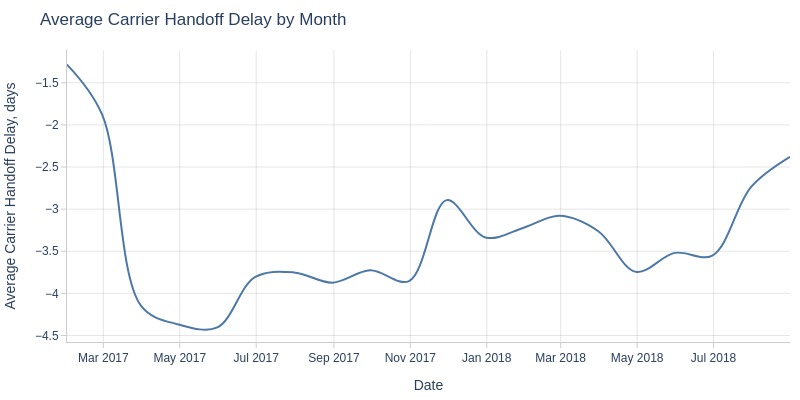
Key Observations:
Carrier handoff consistently faster than limits
Pre-May 2017: improving lead times (peaked at 4.5 days ahead)
Post-May 2017: declining to ~2.5 days ahead by August
Proportion of Each Stage in Delivery Time#
Let’s look at what percentage of the total delivery time each stage occupies.
We will not consider any anomalous dates, as there are only a few and they will not significantly affect the result.
tmp_df_sales = (
df_sales[[
'order_purchase_dt',
'order_approved_dt',
'order_delivered_carrier_dt',
'order_delivered_customer_dt',
]]
[lambda x: (x.order_delivered_customer_dt >= x.order_purchase_dt) & (x.order_approved_dt >= x.order_purchase_dt)
& (x.order_delivered_carrier_dt >= x.order_approved_dt) & (x.order_delivered_customer_dt >= x.order_delivered_carrier_dt)
]
.dropna()
)
tmp_df_sales['from_purchase_to_customer'] = (tmp_df_sales['order_delivered_customer_dt'] - tmp_df_sales['order_purchase_dt']).dt.total_seconds()
tmp_df_sales['From Purchase to Approved'] = (
(tmp_df_sales['order_approved_dt'] - tmp_df_sales['order_purchase_dt']).dt.total_seconds() * 100 / tmp_df_sales['from_purchase_to_customer']
).round(2)
tmp_df_sales['From Approved to Carrier'] = (
(tmp_df_sales['order_delivered_carrier_dt'] - tmp_df_sales['order_approved_dt']).dt.total_seconds() * 100 / tmp_df_sales['from_purchase_to_customer']
).round(2)
tmp_df_sales['From Carrier to Customer'] = (
(tmp_df_sales['order_delivered_customer_dt'] - tmp_df_sales['order_delivered_carrier_dt']).dt.total_seconds() * 100 / tmp_df_sales['from_purchase_to_customer']
).round(2)
tmp_df_sales = (
tmp_df_sales[['order_purchase_dt', 'From Purchase to Approved', 'From Approved to Carrier', 'From Carrier to Customer']]
.melt(id_vars = 'order_purchase_dt', var_name='Stage', value_name='Percent of All Delivery Time')
.rename(columns={'order_purchase_dt': 'Date'})
)
category_orders = {
'Stage': ['From Purchase to Approved', 'From Approved to Carrier', 'From Carrier to Customer']
}
fig = tmp_df_sales.viz.area(
x='Date'
, y='Percent of All Delivery Time'
, color='Stage'
, agg_func='mean'
, freq='ME'
, title='Average Percent of All Delivery Time by Stage and Month'
, category_orders=category_orders
)
pb.to_slide(fig)
fig.show()
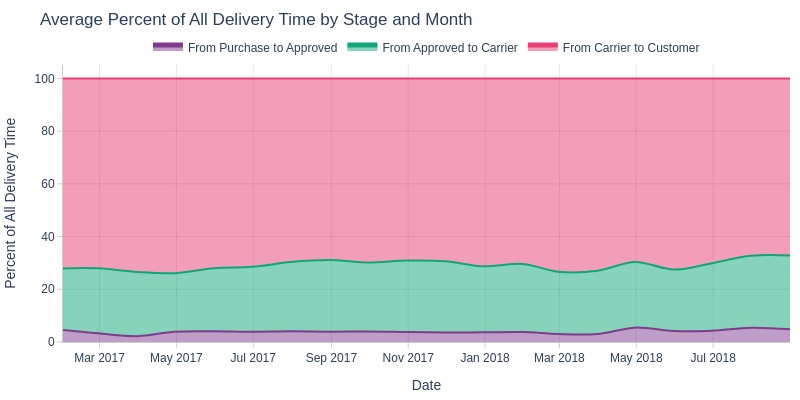
Key Observations:
Carrier delivery consumes most of total delivery time
Order Weight#
pb.configure(
df = df_sales
, time_column = 'order_purchase_dt'
, time_column_label = 'Date'
, metric = 'total_weight_kg'
, metric_label = 'Average Weight of Orders, kg'
, metric_label_for_distribution = 'Weight of Orders, kg'
, agg_func = 'mean'
, freq = 'ME'
)
By Day and Month
pb.box(mode='time_series', freq='M').show()
pb.box(mode='time_series', freq='M', upper_quantile=0.95).show()
for freq in ['D', 'ME']:
pb.line_resample(freq=freq).show()
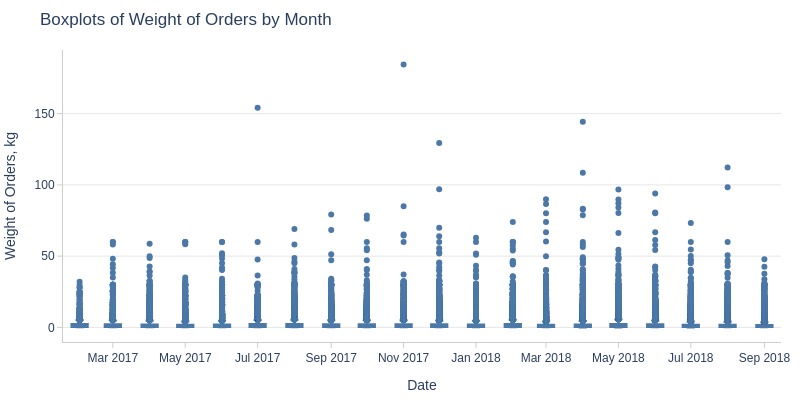
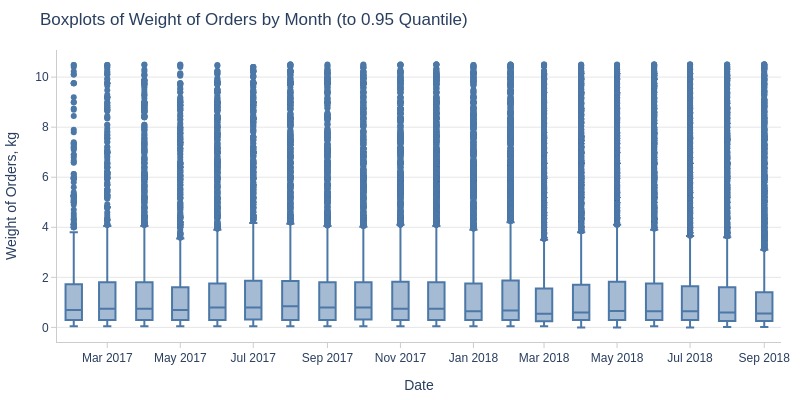
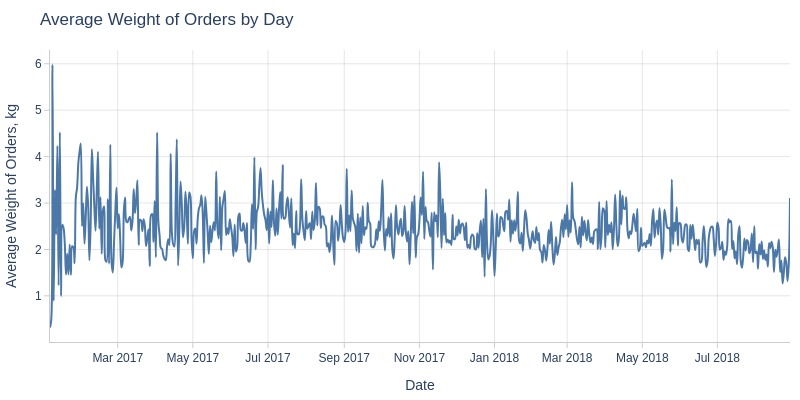
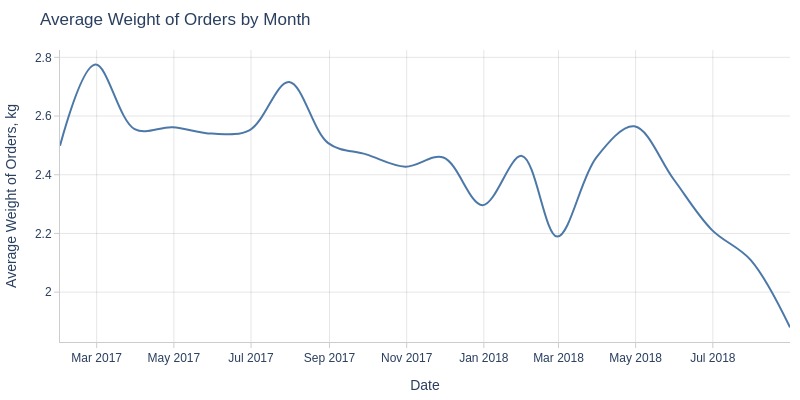
Key Observations:
Average order weight declining monthly (2.8kg → 1.9kg)
By Review Score
pb.line_resample(color='order_avg_reviews_score')
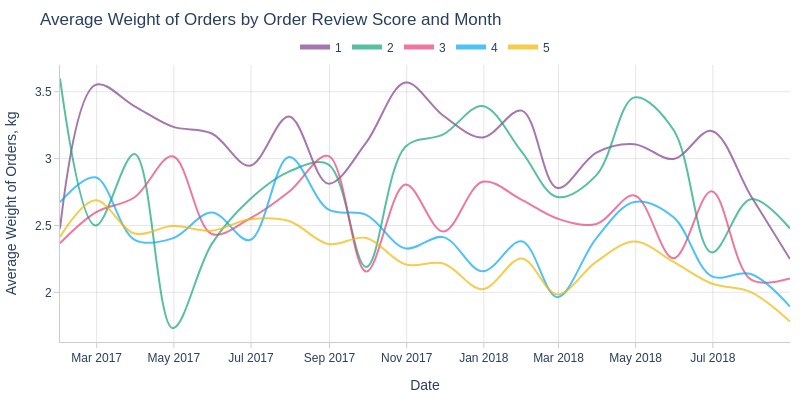
Key Observations:
1-star orders typically heaviest
2-star orders show most monthly weight variability
By Whether the Order is Delayed or Not
pb.line_resample(color='is_delayed')
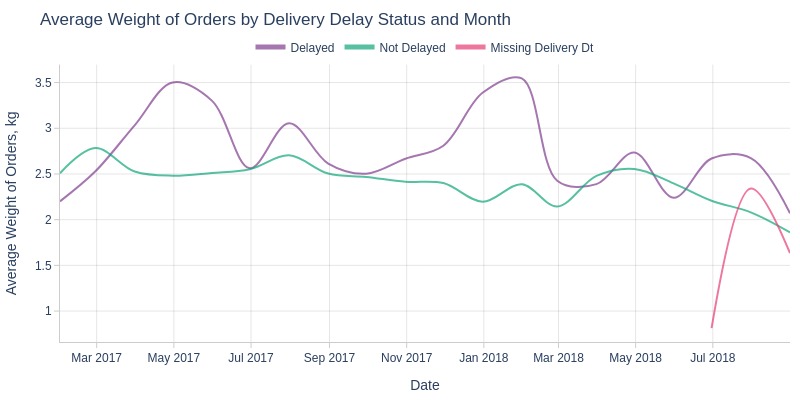
Key Observations:
Delayed orders usually heavier
Non-delayed weights more stable monthly
By Presence of Installment Payments
pb.line_resample(color='order_has_installment')
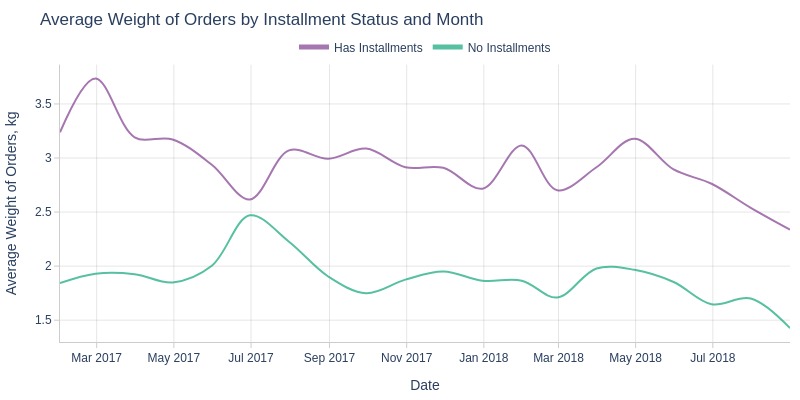
Key Observations:
Installment orders consistently heavier
By Delivery Time Category
pb.line_resample(color='delivery_time_days_cat')
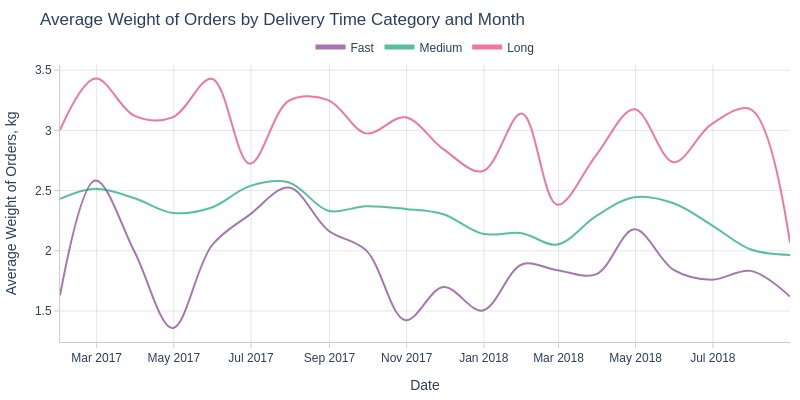
Key Observations:
Lighter orders typically deliver faster
By Top Customer Cities
pb.line_resample(color='customer_city')
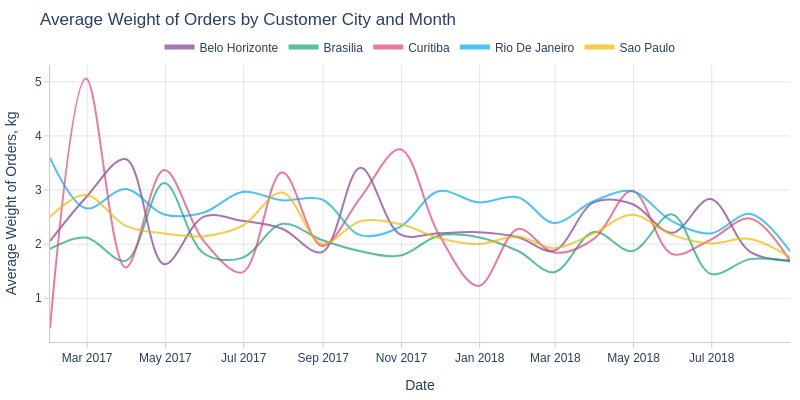
Key Observations:
Curitiba shows most monthly weight variability among top cities
Number of Products in Order#
Prepare dataframe for analysis.
pb.configure(
df = df_sales
, time_column = 'order_purchase_dt'
, time_column_label = 'Date'
, metric = 'products_cnt'
, metric_label = 'Average Number of Products in Order'
, metric_label_for_distribution = 'Number of Products in Order'
, agg_func = 'mean'
, freq = 'ME'
)
By Day and Month
pb.box(mode='time_series', freq='M').show()
for freq in ['D', 'ME']:
pb.line_resample(freq=freq).show()
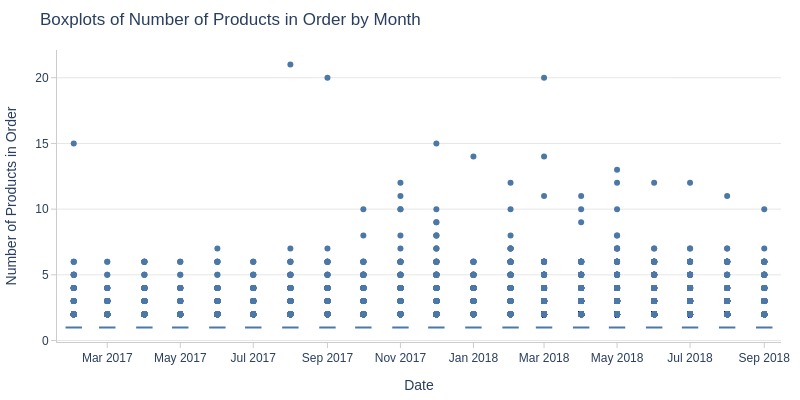
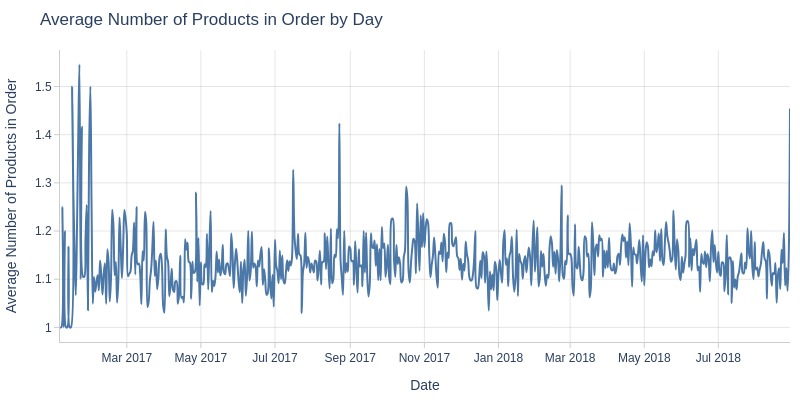
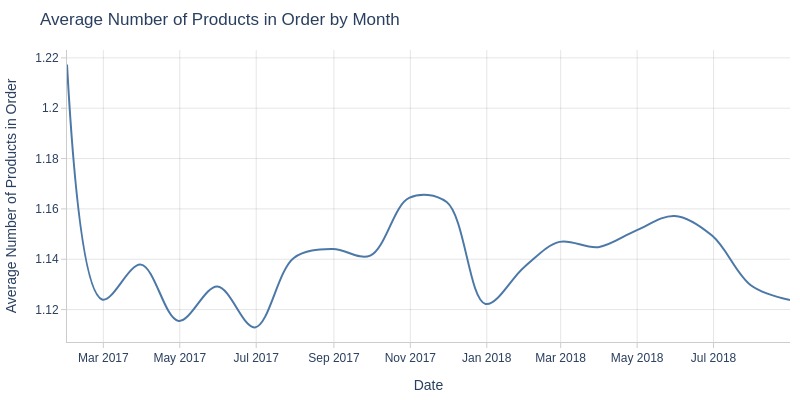
Key Observations:
Average products per order remains stable (1.12-1.16)
By Review Score
pb.line_resample(color='order_avg_reviews_score')
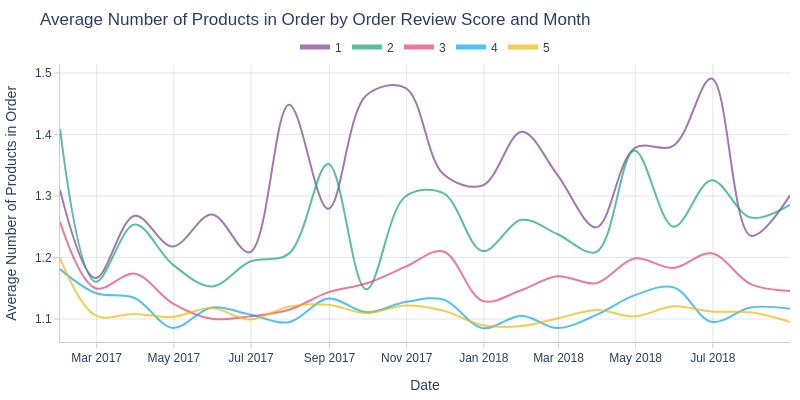
Key Observations:
1/2-star orders typically have more products
4/5-star orders usually have fewest products
By Whether the Order is Delayed or Not
pb.box(mode='time_series', color='is_delayed', freq='M').show()
pb.line_resample(color='is_delayed')
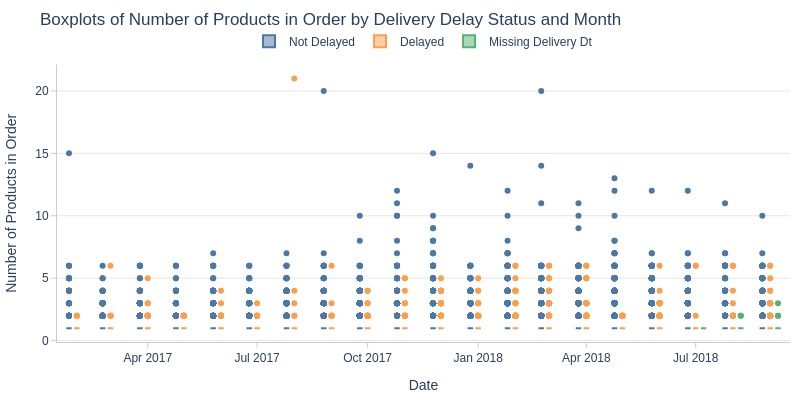
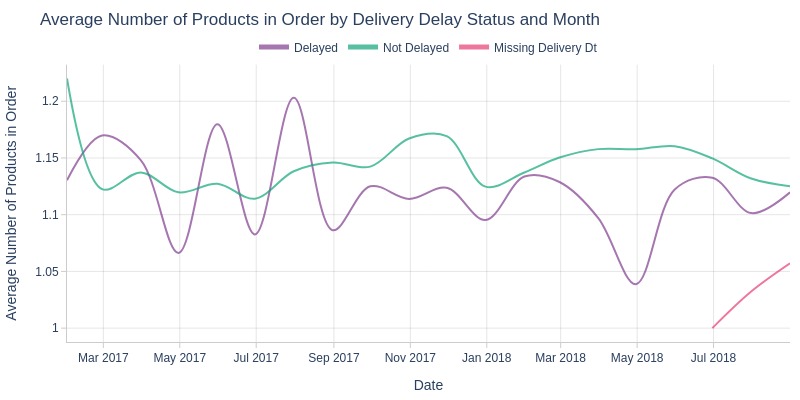
Key Observations:
Delayed orders show more product count variability
By Presence of Installment Payments
pb.box(mode='time_series', color='order_has_installment', freq='M').show()
pb.line_resample(color='order_has_installment')
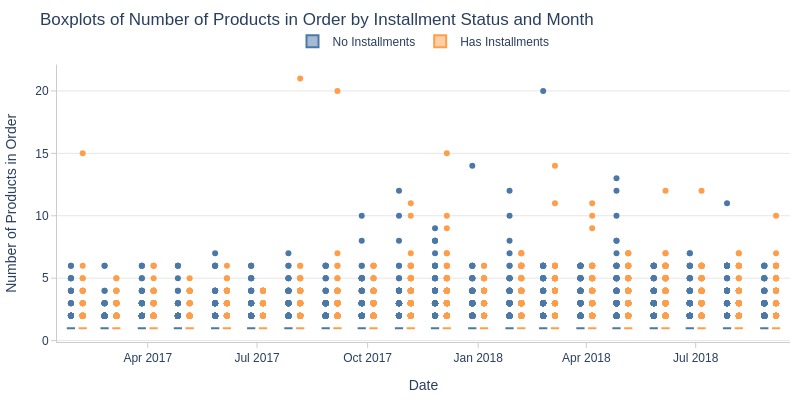
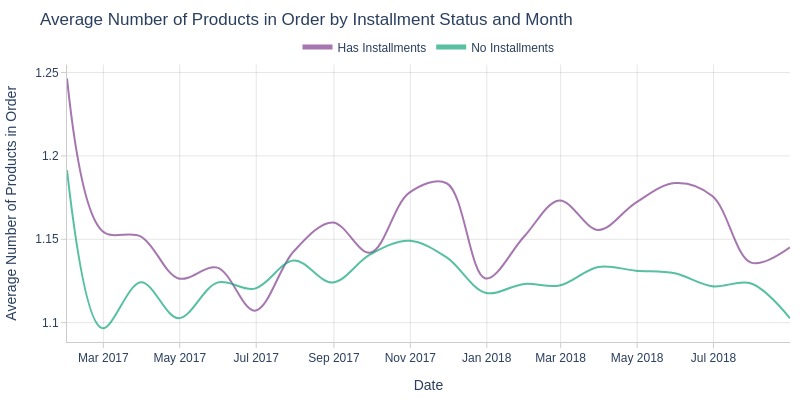
Key Observations:
Installment orders usually contain more products
By Top Customer Cities
pb.line_resample(color='customer_city')
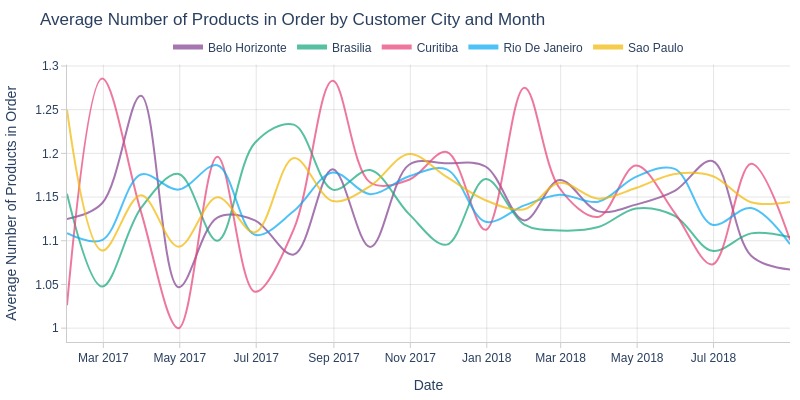
Key Observations:
Curitiba shows most monthly product count variability
Number of Unique Products in Order#
pb.configure(
df = df_sales
, time_column = 'order_purchase_dt'
, time_column_label = 'Date'
, metric = 'unique_products_cnt'
, metric_label = 'Average Number of Unique Products in Order'
, metric_label_for_distribution = 'Number of Unique Products in Order'
, agg_func = 'mean'
, freq = 'ME'
)
By Day and Month
pb.box(mode='time_series', freq='M').show()
for freq in ['D', 'ME']:
pb.line_resample(freq=freq).show()
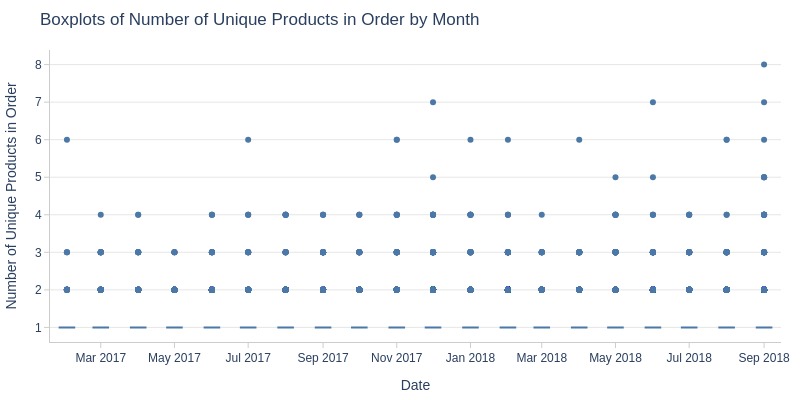
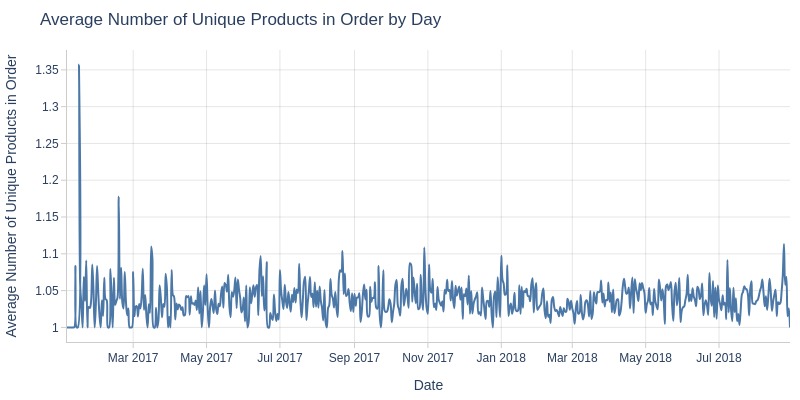
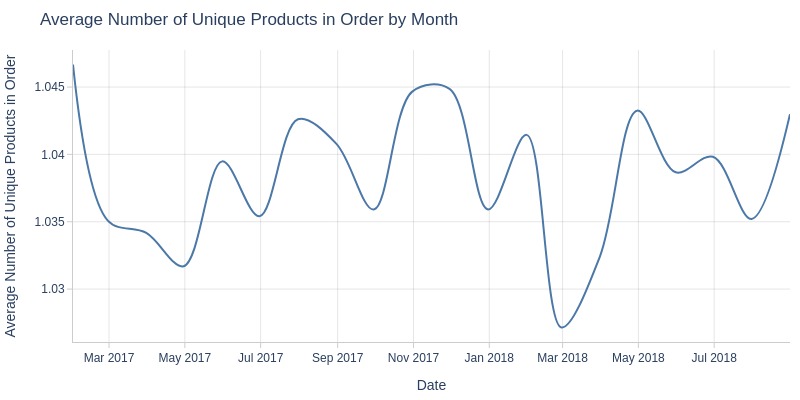
Key Observations:
Average unique products per order remains stable (1.03-1.045)
By Review Score
pb.line_resample(color='order_avg_reviews_score')
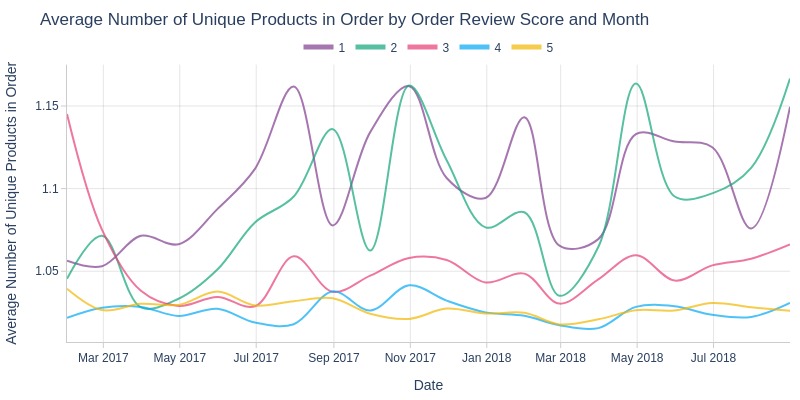
Key Observations:
1/2-star orders have more unique products
4/5-star orders have fewest unique products
By Whether the Order is Delayed or Not
pb.box(mode='time_series', color='is_delayed', freq='M').show()
pb.line_resample(color='is_delayed')
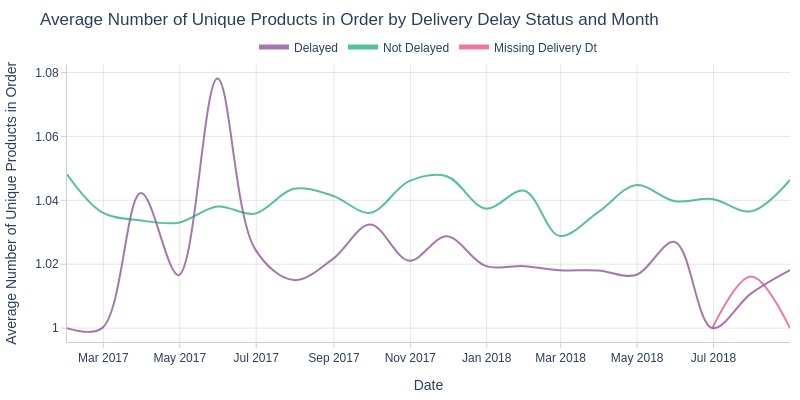
Key Observations:
Non-delayed orders slightly higher in unique products
Delayed orders show more variability
By Presence of Installment Payments
pb.box(mode='time_series', color='order_has_installment', freq='M').show()
pb.line_resample(color='order_has_installment')
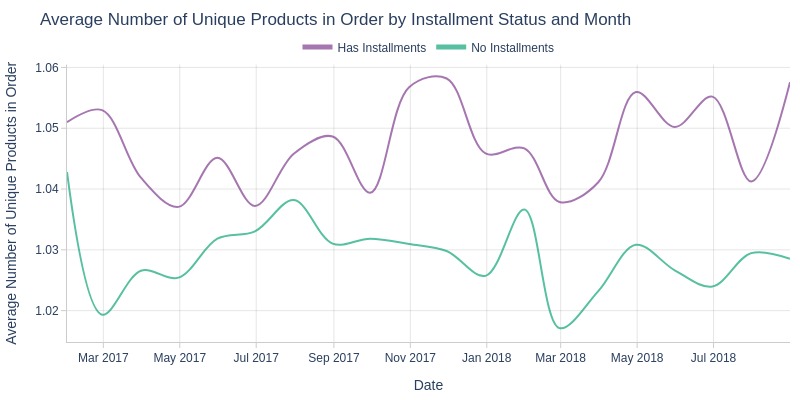
Key Observations:
Installment orders consistently have more unique products
Product Price in Order#
pb.configure(
df = df_sales
, time_column = 'order_purchase_dt'
, time_column_label = 'Date'
, metric = 'avg_products_price'
, metric_label = 'Average Product Price in Order, R$'
, metric_label_for_distribution = 'Product Price in Order, R$'
, agg_func = 'mean'
, freq = 'ME'
)
By Day and Month
pb.box(mode='time_series', freq='M').show()
pb.box(mode='time_series', freq='M', upper_quantile=0.95).show()
for freq in ['D', 'ME']:
pb.line_resample(freq=freq).show()
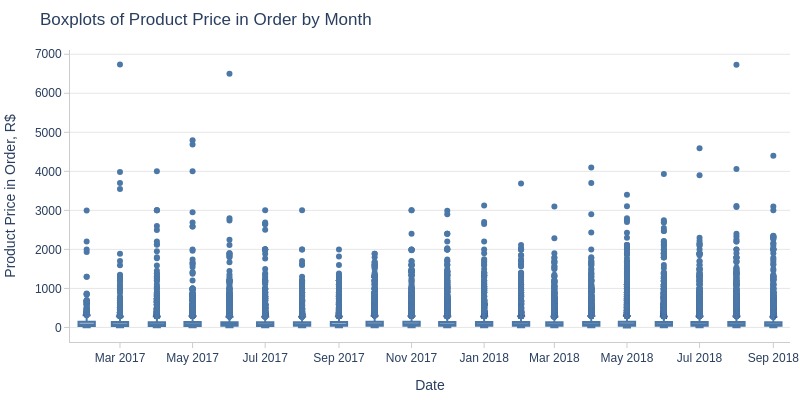
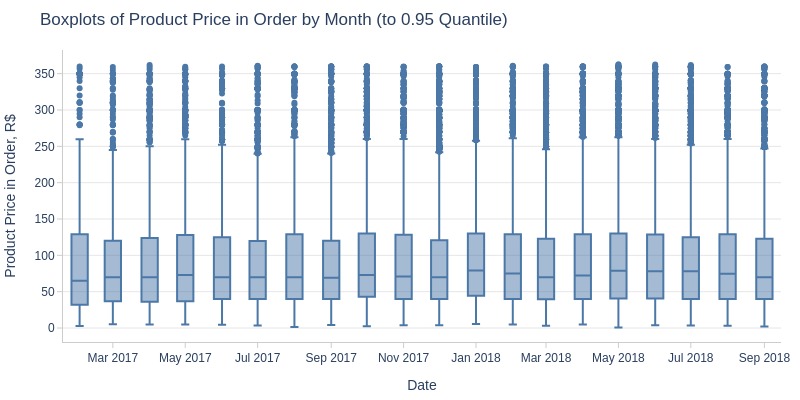
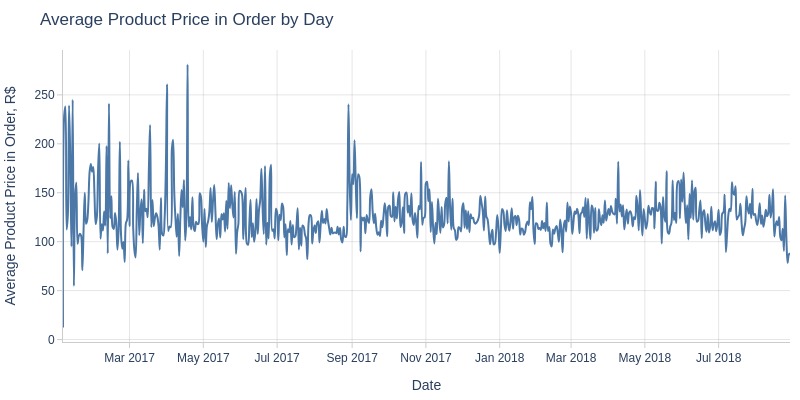
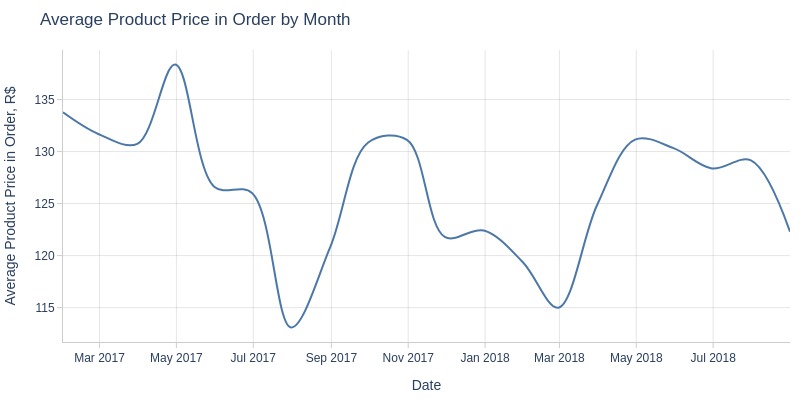
Key Observations:
No Black Friday spike in average product price
Monthly average product price fluctuates (115-135 R$)
Clear seasonality:
Pre-July 2017: decline
July-Oct 2017: growth
Oct 2017-Mar 2018: decline
Mar-Apr 2018: growth
Post-Apr 2018: decline
By Review Score
pb.line_resample(color='order_avg_reviews_score')
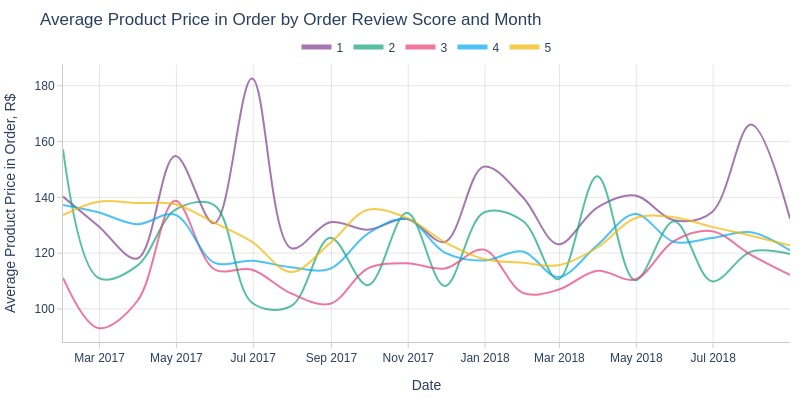
Key Observations:
1-star orders typically have highest product prices
3-star orders usually lowest
By Whether the Order is Delayed or Not
pb.line_resample(color='is_delayed')
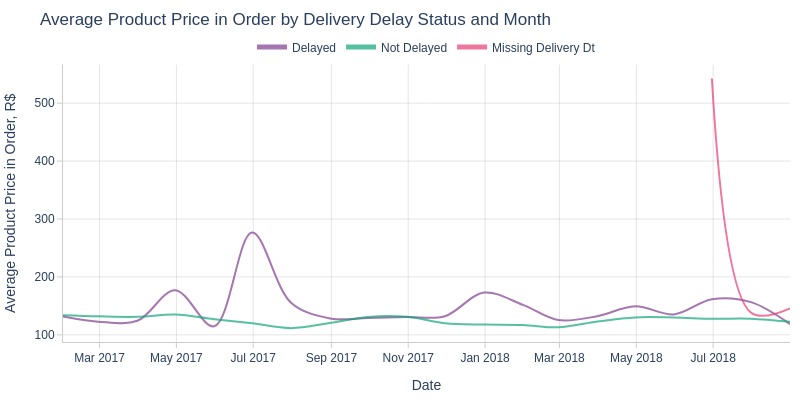
Key Observations:
Delayed orders usually have higher product prices
June 2017 saw sharp price spike in delayed orders
By Presence of Installment Payments
pb.line_resample(color='order_has_installment')
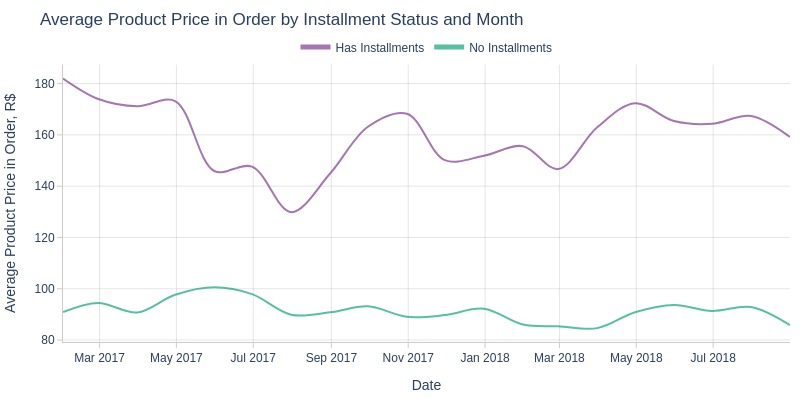
Key Observations:
Installment orders have significantly higher product prices
Number of Sellers in Order#
pb.configure(
df = df_sales
, time_column = 'order_purchase_dt'
, time_column_label = 'Date'
, metric = 'sellers_cnt'
, metric_label = 'Average Number of Sellers in Order'
, metric_label_for_distribution = 'Number of Sellers in Order'
, agg_func = 'mean'
, freq = 'ME'
)
By Day and Month
pb.box(mode='time_series', freq='M').show()
for freq in ['D', 'ME']:
pb.line_resample(freq=freq).show()
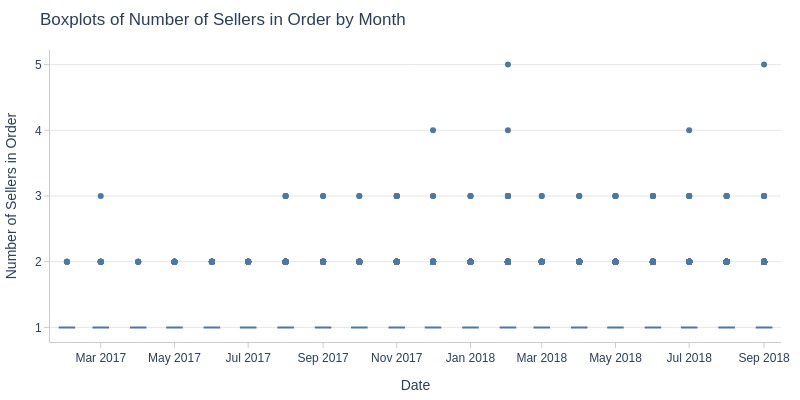
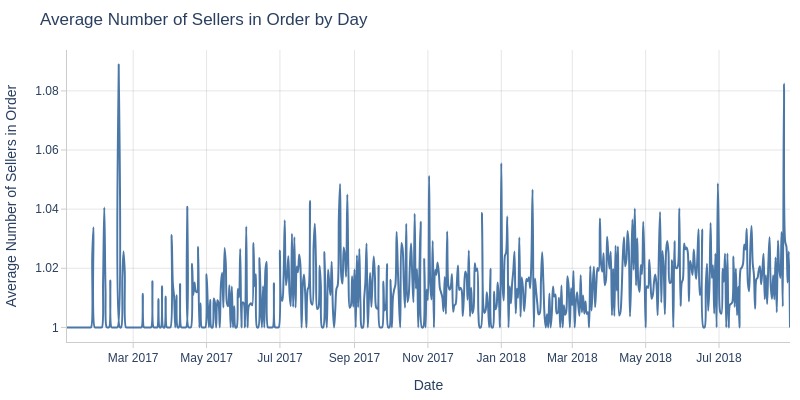
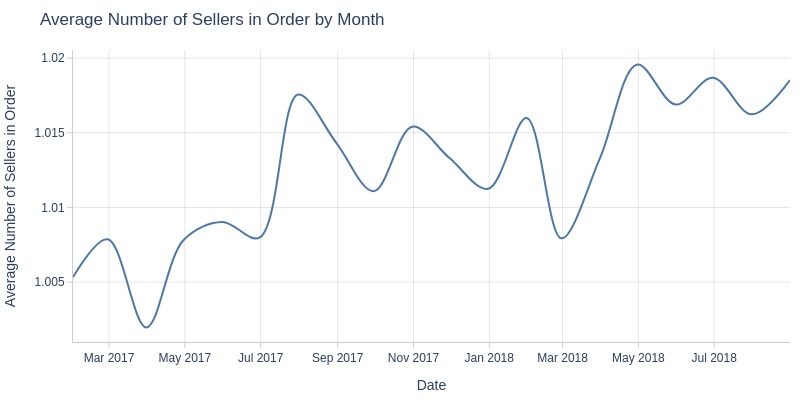
Key Observations:
Average sellers per order grows minimally (1→1.02)
By Review Score
pb.line_resample(color='order_avg_reviews_score')
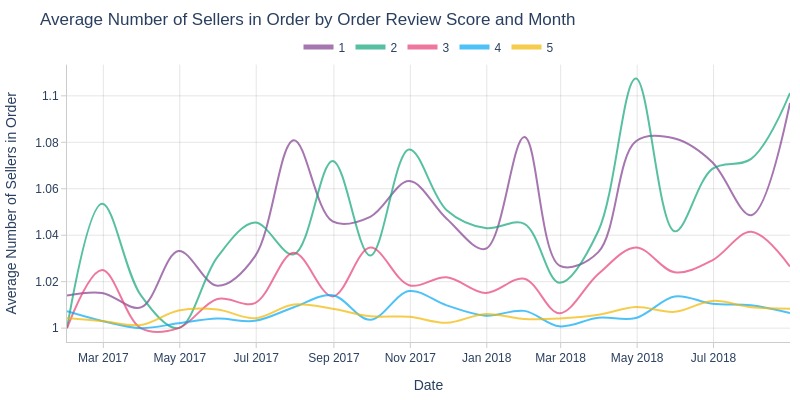
Key Observations:
1/2-star orders typically involve more sellers
4/5-star orders involve fewest sellers
By Whether the Order is Delayed or Not
pb.box(mode='time_series', color='is_delayed', freq='M').show()
pb.line_resample(color='is_delayed')
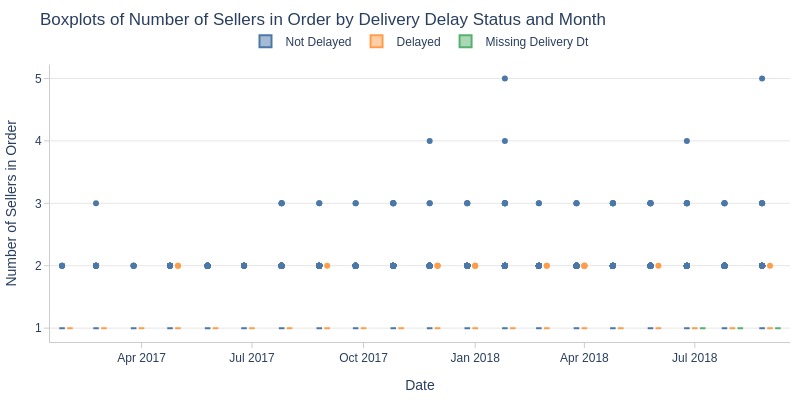
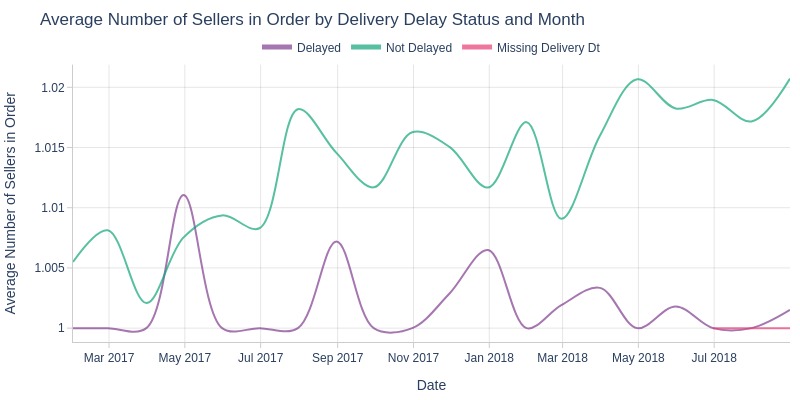
Key Observations:
Non-delayed orders slightly higher in seller count
April 2018 saw sharp seller count spike in undelivered orders
By Presence of Installment Payments
pb.box(mode='time_series', color='order_has_installment', freq='M').show()
pb.line_resample(color='order_has_installment')
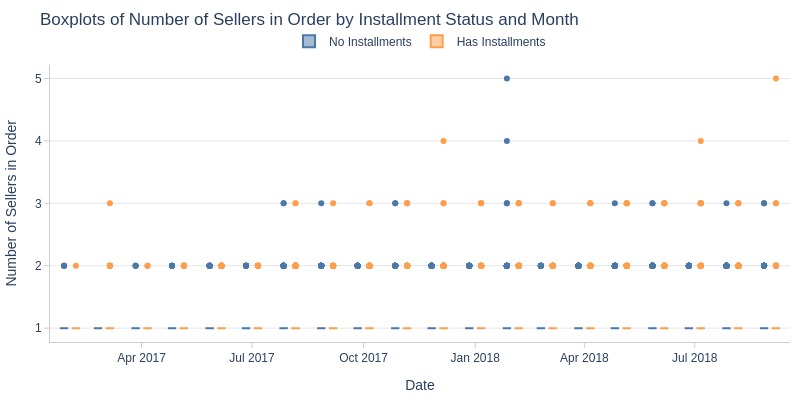
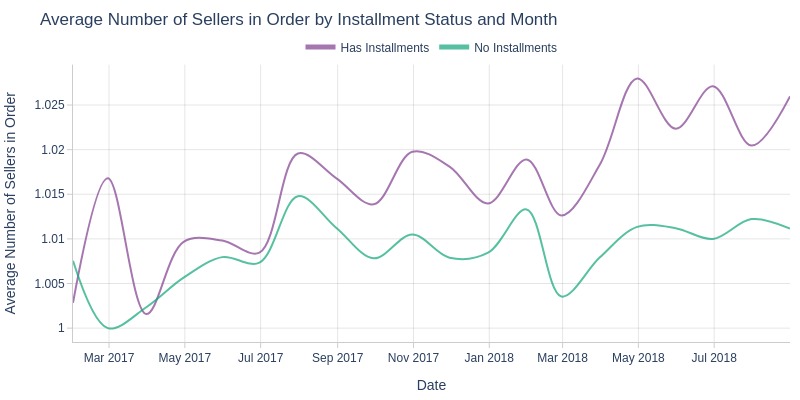
Key Observations:
Installment orders consistently involve more sellers
Number of Categories in Order#
pb.configure(
df = df_sales
, time_column = 'order_purchase_dt'
, time_column_label = 'Date'
, metric = 'product_categories_cnt'
, metric_label = 'Average Number of Categories in Order'
, metric_label_for_distribution = 'Number of Categories in Order'
, agg_func = 'mean'
, freq = 'ME'
)
By Day and Month
pb.box(mode='time_series', freq='M').show()
for freq in ['D', 'ME']:
pb.line_resample(freq=freq).show()
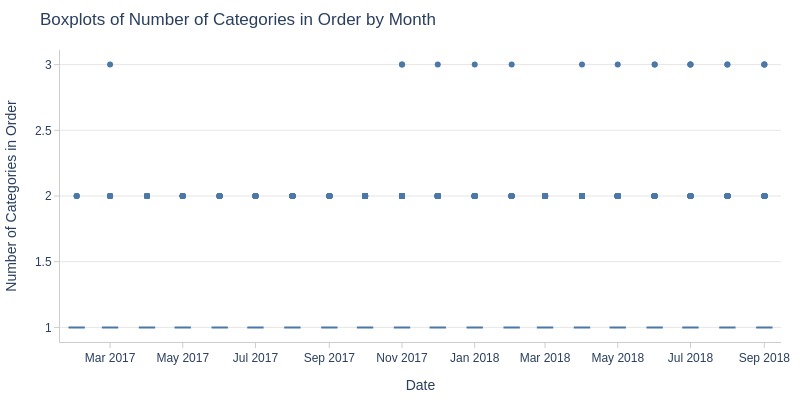
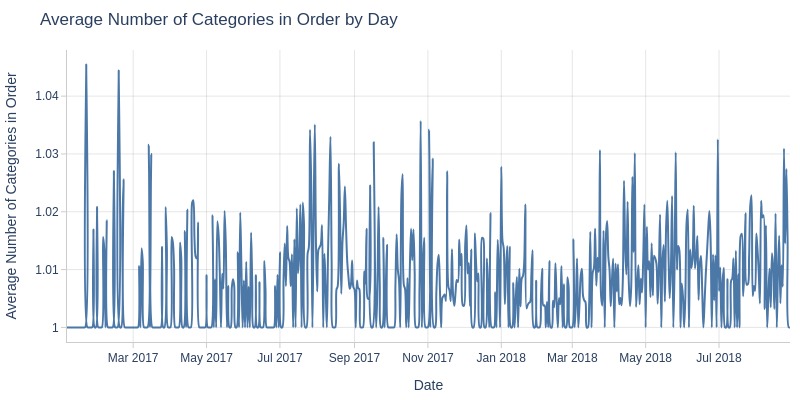
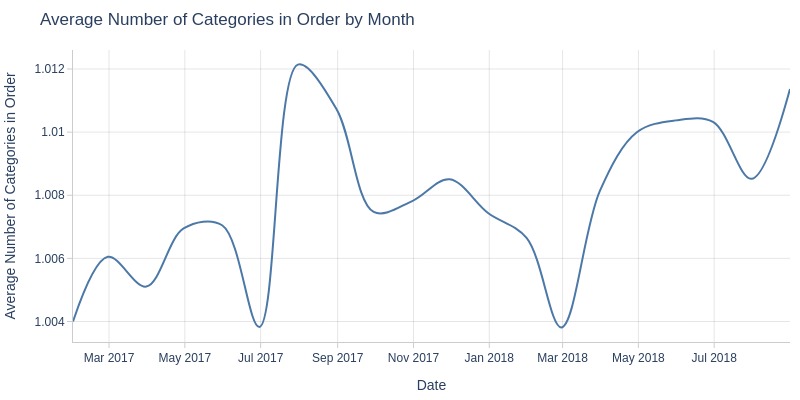
Key Observations:
Average categories per order remains stable
By Review Score
pb.line_resample(color='order_avg_reviews_score')
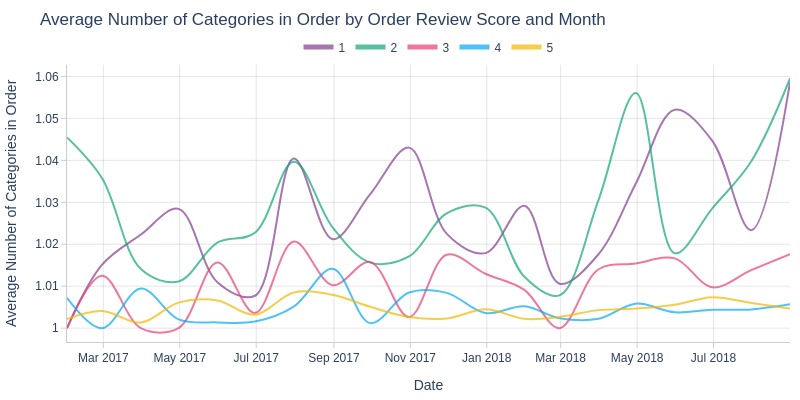
Key Observations:
1/2-star orders involve more categories
By Presence of Installment Payments
pb.box(mode='time_series', color='order_has_installment', freq='M').show()
pb.line_resample(color='order_has_installment')
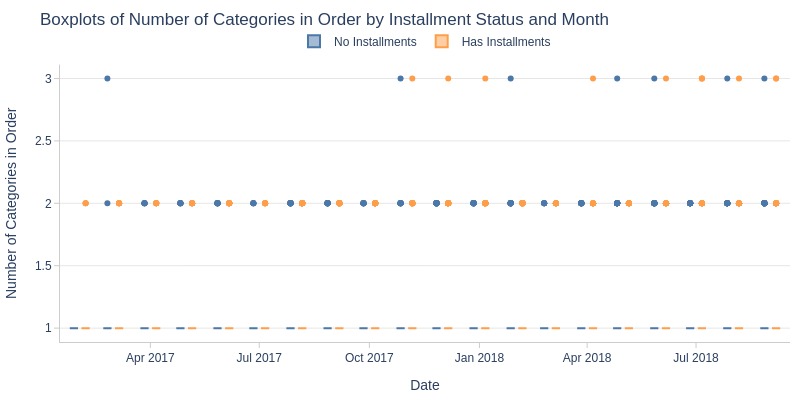
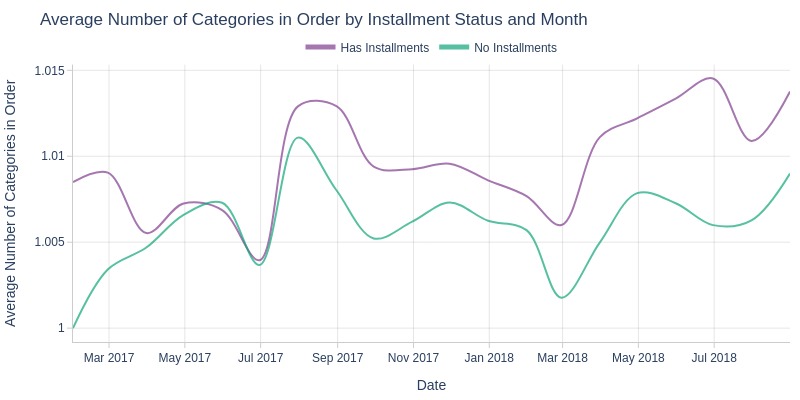
Key Observations:
Installment orders have slightly more categories